




- @jie_kou
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
随着生成式AI技术的快速发展,传统的手动测试数据生成方式逐渐被智能化、自动化的解决方案取代。本文将深入探讨基于生成式AI的自动化测试数据生成技术,涵盖其技术原理、实现方法、优化策略以及实际应用案例。生成式AI(Generative AI)通过深度学习模型(如生成对抗网络 GAN、变分自编码器 VAE)模拟数据分布,能够从少量输入数据中生成高质量、符合业务逻辑的测试数据。在测试数据生成中,RL通过设

随着软件开发复杂性的增加,代码漏洞检测与修复已成为DevOps流程中的核心挑战。生成式AI(Generative AI)通过其强大的代码生成与模式识别能力,为实时漏洞检测与自动化修复提供了全新解决方案。本文将探讨如何将生成式AI技术集成到持续集成(CI)流水线中,优化代码质量与安全性,同时降低人工干预成本。通过与CI/CD流水线的深度融合,开发者能够实现从“能用”到“敢用”的跨越。未来,随着多模型

C/C++内存安全问题虽然复杂棘手,但通过深入理解隐患本质,严格遵循防御性编程策略,合理运用安全工具,结合实际案例不断积累经验,我们完全能够构建出健壮可靠的C/C++程序。在代码的世界里,每一处细节的严谨都是对内存安全的守护,让我们以防御性编程为盾,抵御内存安全的重重风险,书写更安全的代码篇章。

在软件开发领域,随着人工智能和语音识别技术的快速发展,基于语音交互的代码生成与编辑正逐渐成为开发者的新工具。通过提升语音识别的准确性、优化交互逻辑、结合自然语言处理技术,我们可以构建更加智能、高效的语音交互代码编辑工具,为开发者带来更便捷、更愉悦的开发体验。通过使用先进的语音识别引擎,如Google的语音识别API,可以实现高准确性的语音识别,并通过用户反馈不断优化模型。在语音交互中,合理的交互逻

实时语音识别系统对硬件性能和任务调度效率提出双重挑战。随着异构计算架构(CPU+GPU+FPGA+ASIC)的普及,如何通过动态任务调度与资源优化实现低延迟、高吞吐成为研究热点。本文提出一种基于动态优先级与负载感知的多阶段优化框架,通过实验验证其在NVIDIA Jetson AGX Xavier平台上的有效性。不同调度策略下的延迟与吞吐量对比(单位:ms/req, req/s)未来将探索量子计算与
当AI开始理解纳西族的东巴文字,当机器能解析夏尔巴人的雪山谚语,我们正在见证一场静默的语言革命。这些技术突破不仅是算法的进步,更是人类文明保存方式的范式转变。未来的语音识别系统,或许会成为连接不同文明的数字桥梁,让每一种声音都能被世界听见。技术启示录:真正的智能不是取代人类语言,而是让所有语言都能平等对话。
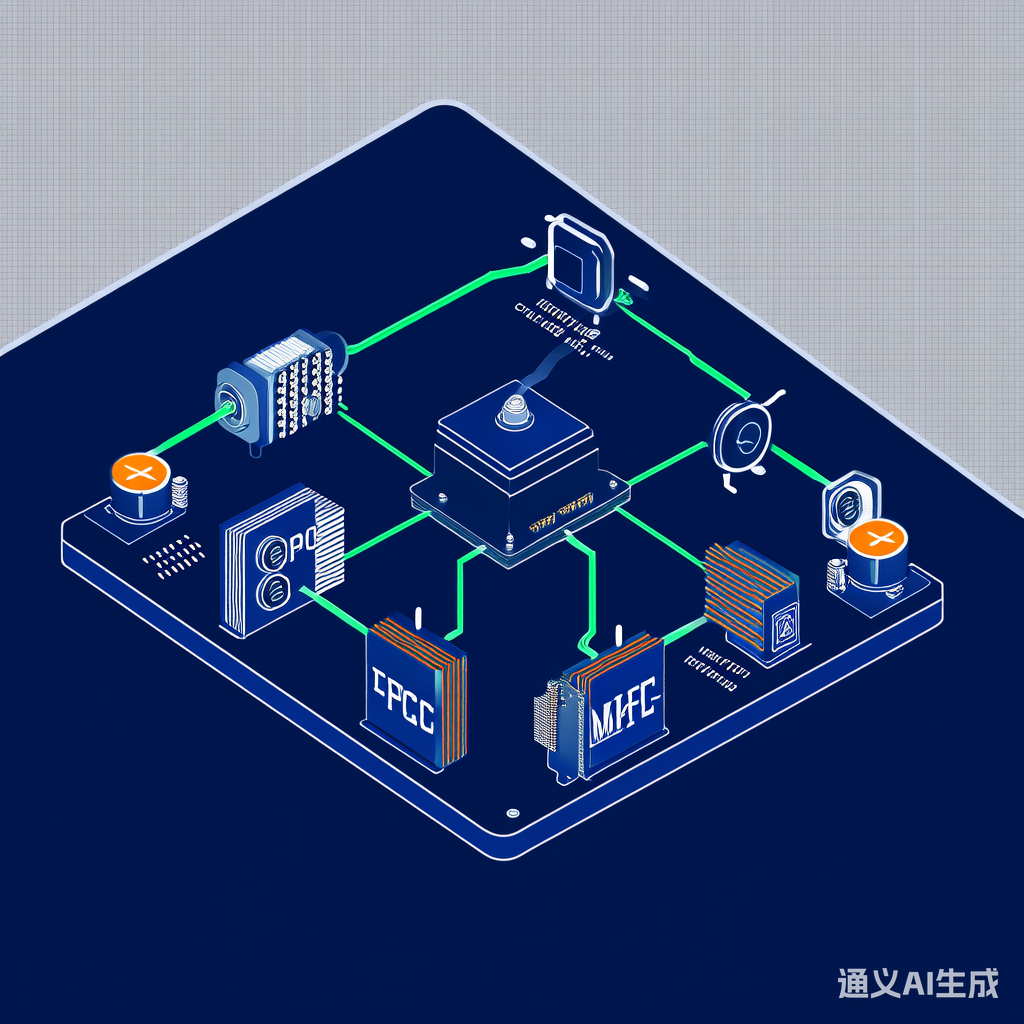
在智能语音助手、远程会议等场景中,实时语音识别的准确性严重依赖于端点检测(VAD)与噪声抑制(NS)的协同效果。本文通过分析最新行业实践,揭示AI驱动的联合优化技术如何突破这一瓶颈,实现语音识别系统的性能跃迁。AI驱动的端点检测与噪声抑制联合优化技术正在重塑语音交互的底层逻辑。通过多模态特征融合、时空一致性约束等创新方法,该技术已突破传统语音处理的性能天花板。随着边缘计算和神经符号系统的进一步发展
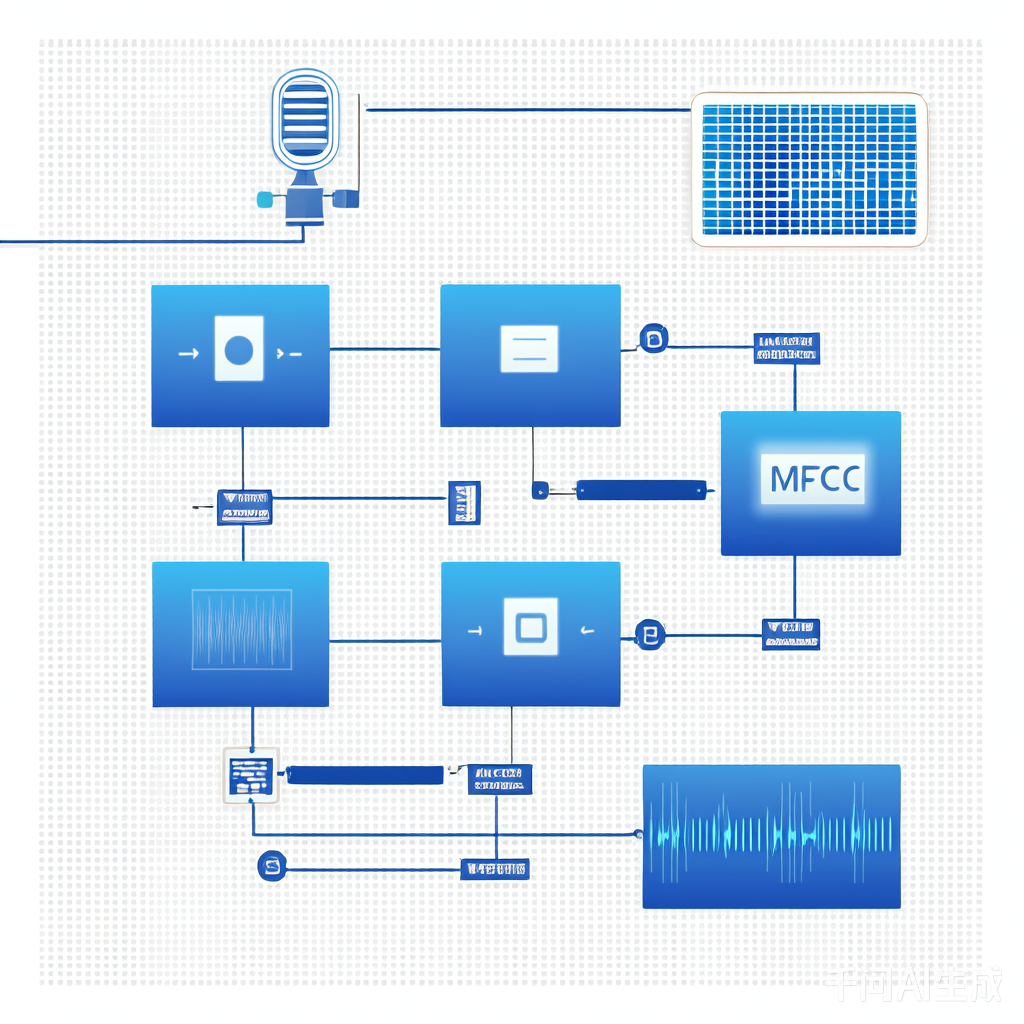
这让我想起三年前第一次写AI代码时的惨状——把"activation='relu'"写成"activiation='re1u'"(是的,多了一个i少了一个l),调试了整整三天。仔细检查发现算法把"200g面粉"识别成了"200g盐"——这大概就是传说中的"AI的毒舌"?就像我刚训练的扫地机器人,它不仅能扫地,还能偷偷藏我的袜子——这大概就是传说中的"AI的复仇"。更魔幻的是用AI写情书,生成的文本

说到底,AI就像一面镜子,照出我们自己的局限。它会犯错,我们会纠正;它会进步,我们也要成长。下次当你家的智能音箱把空调调成-50度时,别急着砸它——说不定这就是AI在提醒你:"嘿,人类,该升级你的幽默感了!P.S. 如果你发现这篇文章里有错误,欢迎指正——毕竟连AI都会犯错,何况我这个靠咖啡续命的凡人。

突然正经AI不是万能的,但它的潜力值得我们去探索。就像我那个会自动生成教案的AI助手,虽然总想教我怎么“先夸后骂”,但它确实帮我省出了时间和学生谈心。最后的冷笑话人类:“AI你到底有没有灵魂?AI:“没有,但我能帮你写灵魂拷问的作文。别追求完美卡壳改稿:上面那个流程图我改了三次才满意突然插入冷笑话:比如这篇里每隔三段就来一个承认自己不确定:比如AI会不会真的取代人类?我也不知道,但至少现在它写不出
