




- @iamfromhuoxing
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1.先检查ssh连接是否有效:ssh -T git@github.com,看返回的仓库对不对的上,如果对不上就重新连接,一般会是 hi xxxxxxx。然后重新git remote add origin git@github.com:XXX/XXX。4.最后如果发现如何检查都错误,可能是远程仓库缓存异常(比如尝试了很多次连接仓库)3.如果是ssh连接在pycharm的github的设置页面左下角勾
MCP(模型上下文协议)是一种开放协议,用于实现大语言模型(LLM)应用与外部数据源、工具之间的无缝集成。它为 AI 应用连接各类数据源和工具提供了标准化方式,使所有符合 MCP 规范的客户端都能与所有符合 MCP 规范的服务器互通(即插即用)。
see在wsl接入pycharm中读取文件时碰到。
条件密度 = 切片fX∣Yx∣yfXYxyfYy。#%% md。
装饰器的典型结构是外层函数接收一个函数作为参数,并返回一个内层函数,这个内层函数会增强或修改原函数的行为。:装饰器必须返回一个函数,这个函数可以是一个新的函数,也可以是对原有函数的包装。参数和被装饰函数的参数需要匹配,因为装饰器需要能够接收被装饰函数的所有参数,并将它们传递给被装饰函数。:用于给被装饰函数增加功能,装饰函数就像一个加工厂,通过把被装饰函数作为装饰函数的参数进行。:装饰器不仅可以添加

在38中,如果你的参数字典想同时给好多人用,但是**params是不会自动筛选的,这时候可以在类里面(例子中是TrainNet)的构造参数里加一个**kwargs,这样多余的参数就会自动 传入**kwargs,这样就保证了参数不错误但也不发挥作用。路径与文件分割:directory, filename = os.path.split(path) #(‘/home/user/docs’, ‘file
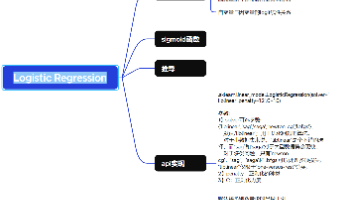
ggg代表一个常用的逻辑函数(logistic function)为SSS形函数(Sigmoid function),公式为:gz11e−zgz1e−z1hx11e−wTxhx1e−wTx1。
对于一个离散随机变量XXX,其可能取值为x1x2xnx1x2...xn,对应的概率分布为p1p2pnp1p2...pnHX−∑i1npilog2piHX−i1∑npilog2pi其中,piPXxipiPXxi表示随机变量XXX取值为xix_ixi的概率。给定随机变量XXX和YYYXXX在YY。
【代码】数据结构-4(常用排序算法、二分查找)
权重变化会导致激活值变化,激活值变化导致最后的预测值变化,预测值变化导致损失函数变化 ,梯度下降算法就是反回去一步一步求权重的导数,找到权重变化对损失函数的影响,找到影响最大的那个权重变化方式。即损失函数对前面所有权重的敏感度。给第一层加入各种w权重,根据权重选择激发下一层的进一步结果,机器学习就是学习这些权重具体的值。倒数第二层,只要把各种抽象事物最后根据参数选择激发某个具体的结果然后输出。梯度
