




- @hawkman
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
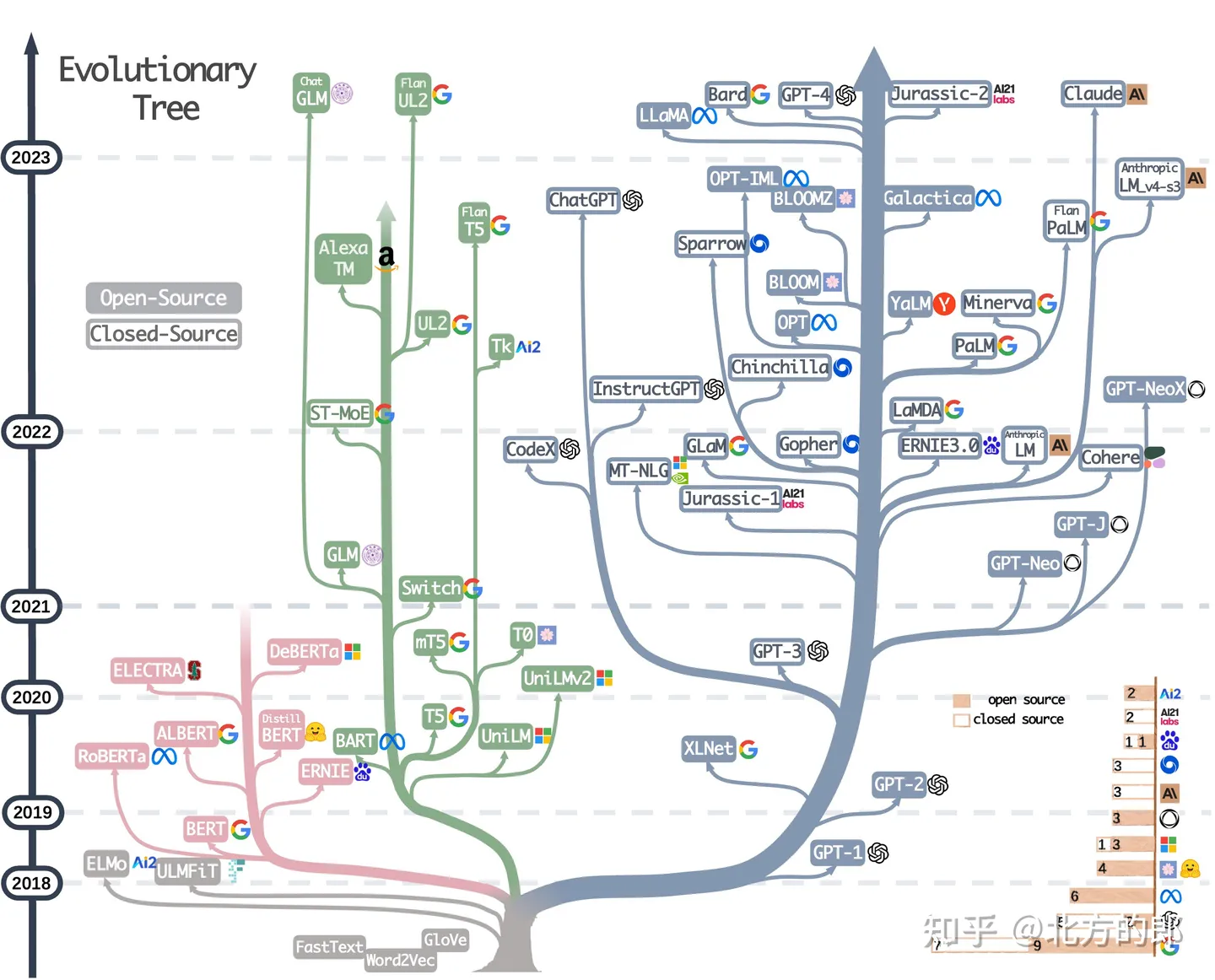
近期大语言模型迅速发展,让大家看得眼花缭乱,感觉现在LLM的快速发展堪比寒武纪大爆炸,各个模型之间的关系也让人看的云里雾里。最近一些学者整理出了 ChatGPT 等语言模型的发展历程的进化树图,让大家可以对LLM之间的关系一目了然。论文:https://arxiv.org/abs/2304.13712Github(相关资源):https://github.com/Mooler0410/LLMsPr
PaddleHub可以便捷地获取PaddlePaddle生态下的预训练模型,完成模型的管理和一键预测。配合使用Fine-tune API,可以基于大规模预训练模型快速完成迁移学习,让预训练模型能更好地服务于用户特定场景的应用。模型概述:模型概述 DeepLabv3+ 是Google DeepLab语义分割系列网络的最新作,其前作有 DeepLabv1,DeepLabv2, DeepLabv...
字节跳动团队提出DepthAnything3(DA3),通过"深度-光线"表示法和单一Transformer架构,统一了3D视觉任务。DA3采用教师-学生训练范式,利用合成数据生成高质量伪标签,显著提升了模型性能。实验表明,DA3在相机位姿估计、几何重建等任务上全面超越现有方法,位姿准确率平均提升35.7%。该模型展示了作为3D基础模型的潜力,为通用3D感知发展奠定了基础。
1. 简介现在情感分析有很广泛的应用,例如:评论分析与决策,通过对产品多维度评论观点进行倾向性分析,给用户提供该产品全方位的评价,方便用户进行决策评论分类,通过对评论进行情感倾向性分析,将不同用户对同一事件或对象的评论内容按情感极性予以分类展示舆情监控,通过对需要舆情监控的实时文字数据流进行情感倾向性分析,把握用户对热点信息的情感倾向性变化等等百度针对情感分析也提供了多种解决方案...
使用Pandas进行数据操作的时候,有时需要分组将数据错位进行操作。在数据分析中经常遇到需要分组使用a列的第n行数据与去b列的第n+1行数据进行对比或者计算的要求,下面是我使用pandas解决该问题的方法。这个时候可以通过操作Index来实现。不过Pandas针对这种情况已经提供了一种方法了,就是shift函数。定义如下:pandas.DataFrame.shiftDataFrame....
1.功能描述:支持对图片中的手写中文、手写数字进行检测和识别,针对不规则的手写字体进行专项优化,识别准确率可达90%以上2.平台接入具体接入方式比较简单,可以参考我的另一个帖子,这里就不重复了:http://ai.baidu.com/forum/topic/show/9433273.调用攻略(Python3)及评测3.1首先认证授权:在开始调用任何API之前需要先进行认证授...
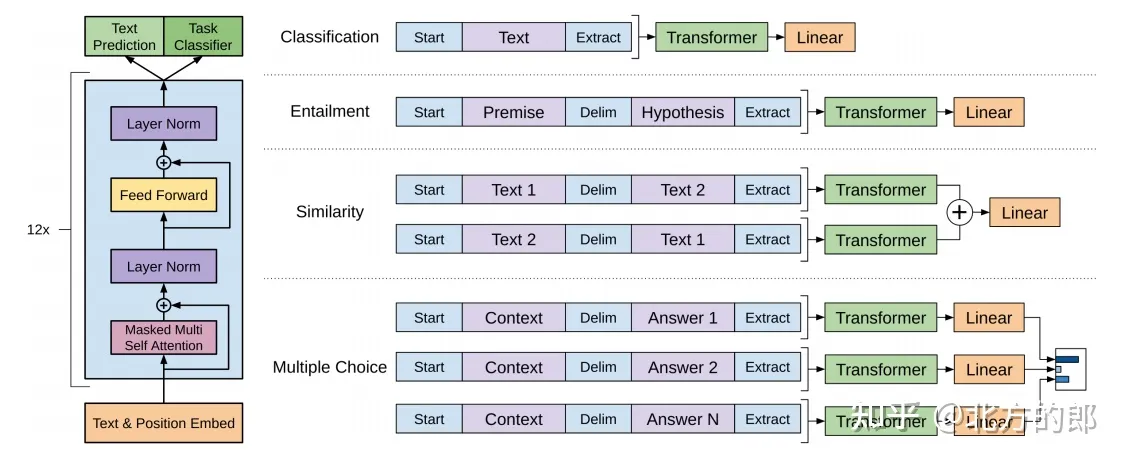
GPT和BERT的输入顺序不同:GPT是从左到右的单向模型,它只能在当前位置之前看到的上下文信息,而BERT是一种双向模型,它可以同时看到前面和后面的文本信息。GPT和BERT的训练数据不同:GPT使用了更广泛的训练数据,包括维基百科和网页文本,而BERT则使用了更多的语言任务,如问答和阅读理解。GPT和BERT的任务不同:GPT是一种基于语言模型的生成式模型,可以生成类似人类写作的文本,而BER
Stability AI与它的多模式AI研究实验室DeepFloyd共同宣布研究版本DeepFloyd IF的发布,这是一款强大的文text-to-image级联像素扩散模型(cascaded pixel diffusion model),复现了Google的Imagen(北方的郎:深入浅出讲解Stable Diffusion原理,新手也能看明白),Imagen也依赖于一个冻结的文本编码器:先将文

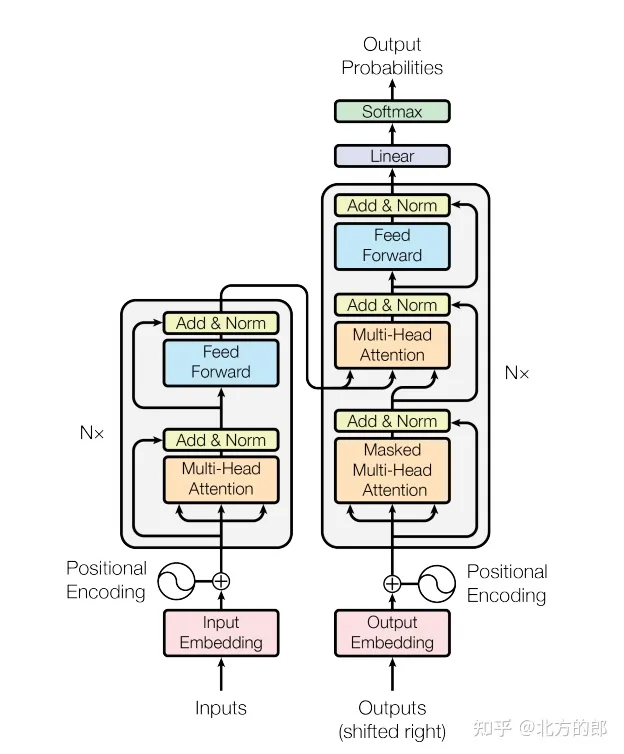
Transformer模型通过引入自注意力机制和多头注意力机制来替代传统的循环神经网络和卷积神经网络,从而提高了模型的表现。同时,Transformer模型还采用了分头处理和残差连接等技术,进一步提高了模型的效率和表现。该模型在机器翻译等任务中取得了极高的性能,成为自然语言处理领域的经典模型之一。
机器学习的过程中很多时候需要用到类似透视表的功能。Pandas提供了pivot和pivot_table实现透视表功能。相对比而言,pivot_table更加强大,在实现透视表的时候可以进行聚类等操作。pivot_table帮助地址:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.pivot_table.htm...