




- @d905133872
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
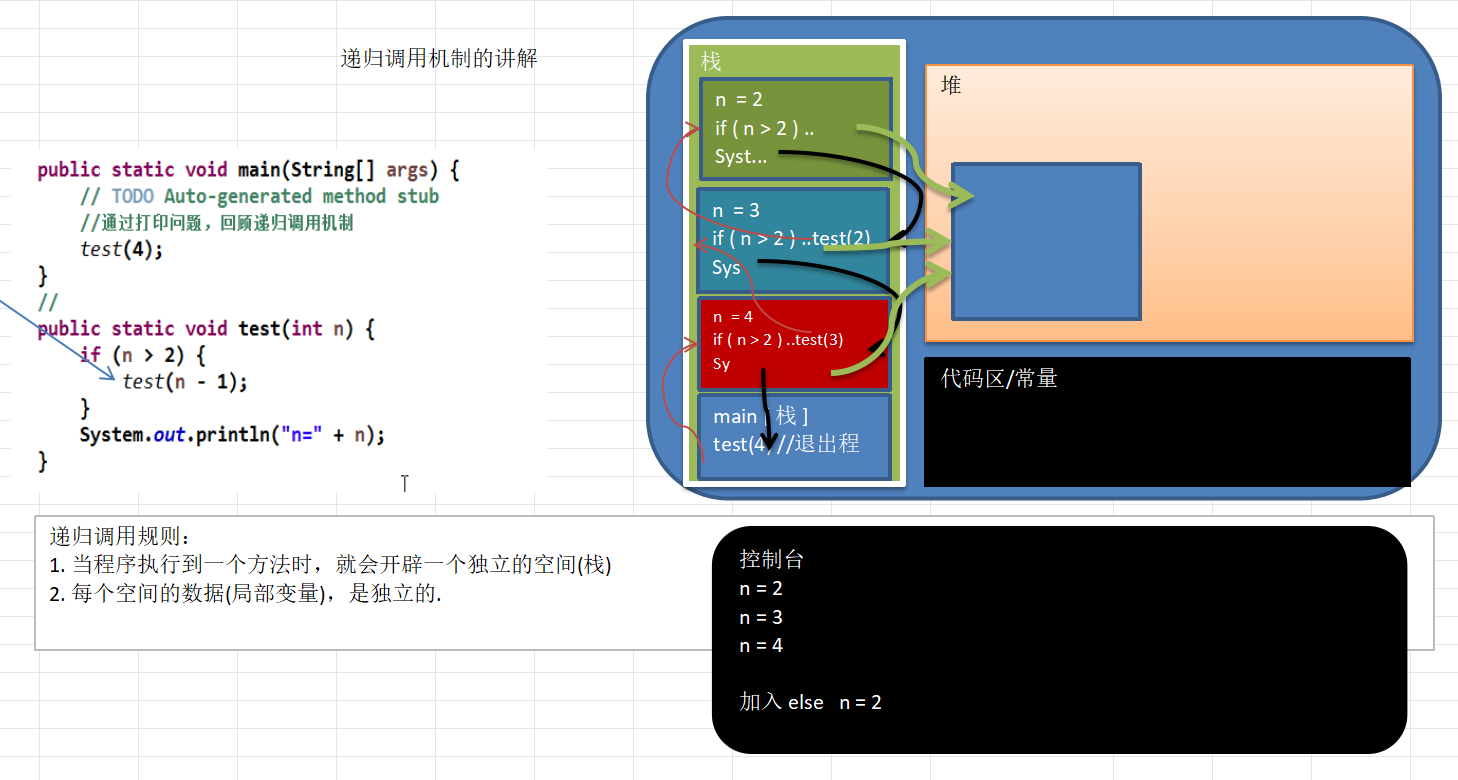
递归机制与常见案例分析(迷宫回溯问题、八皇后问题)
Apache Spark是一个开源的、强大的分布式查询和处理引擎,它提供MapReduce的灵活性和可扩展性,但速度明显要快上很多;拿数据存储在内存中的时候来说,它比Apache Hadoop 快100倍,访问磁盘时也要快上10倍。

*自定义聚合函数类:计算年龄平均值1. 继承UserDefineAggregateFunction2. 重写方法*/// 输入数据的结构Array(// 缓冲区数据的结构:BufferArray(// 函数计算结果的数据类型:Out// 函数的稳定性// 缓冲区初始化// 根据输入的值更新缓冲区数据// 缓冲区数据合并// 计算平均值。

传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue)主要应用于大数据实时处理领域。发布/订阅:消息的发布者不会将消息直接发送给特点的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。最新定义:Kafka是一个开源的分布式事件流平台(Event Streaming Platform)被公司用于高性能数据管道流分析数据集成和关键任务应用。

我们之前学习过hive,hive是一个基于hadoop的SQL引擎工具,目的是为了简化mapreduce的开发。由于mapreduce开发效率不高,且学习较为困难,为了提高mapreduce的开发效率,出现了hive,用SQL的方式来简化mapreduce:hive提供了一个框架,将SQL转换成mapreduce来执行。执行的效率不会因此提升,但开发效率会大大提高。

HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库非结构化数据存储的数据库,基于列的模式存储。利用Hadoop HDFS作为其文件存储系统,写入性能很强,读取性能较差。利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。关系型数据库存储数据是以表格的形式存储,非关系型数据库是以进行存储。通过进行存储,当在用key读取value

将hbase中的jar包导入到hive中。二、修改Hive配置文件。

sc.textFile读取数据源,并对结构化数据进行拆分。

传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue)主要应用于大数据实时处理领域。发布/订阅:消息的发布者不会将消息直接发送给特点的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。最新定义:Kafka是一个开源的分布式事件流平台(Event Streaming Platform)被公司用于高性能数据管道流分析数据集成和关键任务应用。
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库非结构化数据存储的数据库,基于列的模式存储。利用Hadoop HDFS作为其文件存储系统,写入性能很强,读取性能较差。利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。关系型数据库存储数据是以表格的形式存储,非关系型数据库是以进行存储。通过进行存储,当在用key读取value