




- @chenwewi520feng
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
因为Spring Batch 会启用一个 H2 数据库,在这个数据库中,Sping 会对 Batch 需要的配置进行配置。以上,完成了读取文本文件内容并求和、存储至mysql数据库中,是通过注解完成该项工作。数据源文件能正常的读取到,且能针对每个学生的数据进行求和并存储至mysql中。本文使用的是jdk8,较高版本的spring batch需要jdk11环境。启动app.java,然后观察应用程序
介绍了Flink的历史背景以及未来规划、Flink的核心特性以及Flink的API层次结构,在使用过程中会有一个总体上的概念。

软件测试是一个非常专业的工作,在大多数的软件建设组织中,都会有软件测试类的岗位(或类似名称的岗位)来对交付的软件进行验证。在软件全生命周期质量保证的理念下,基于软件过程的测试类别被更为细致的提出来,如需求测试、架构测试、设计测试、单元测试、集成测试、用户验证测试等。对软件质量来说,单元测试有非常积极的作用,是测试金字塔中最重要的部分。有一些团队会直接使用生产上的数据作为测试环境数据,实际上这不是非

因为Spring Batch 会启用一个 H2 数据库,在这个数据库中,Sping 会对 Batch 需要的配置进行配置。以上,完成了读取文本文件内容并求和、存储至mysql数据库中,是通过注解完成该项工作。数据源文件能正常的读取到,且能针对每个学生的数据进行求和并存储至mysql中。本文使用的是jdk8,较高版本的spring batch需要jdk11环境。启动app.java,然后观察应用程序
介绍了Flink的历史背景以及未来规划、Flink的核心特性以及Flink的API层次结构,在使用过程中会有一个总体上的概念。
本文通过在hdfs中三种不同数据格式文件存储相同数量的数据,通过hive和impala两种客户端查询进行比较。本文前提:熟悉hadoop、hive和impala、kafka、flink等,并且其环境都可正常使用。(在后续的专栏中都会将对应的内容补全,目前已经完成了zookeeper和hadoop的部分。)本文分为一般建议,下面通过实际操作进行比较实现1亿条数据在hive和impala中不同sql的
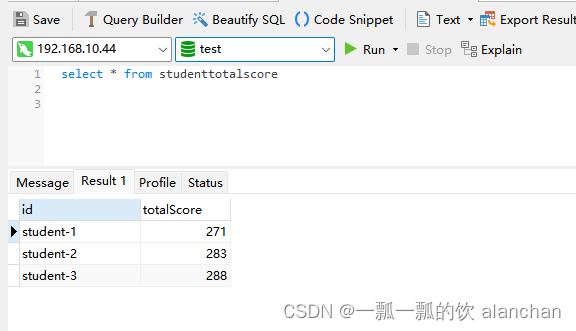
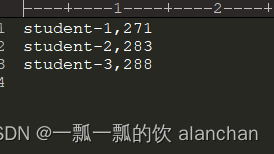
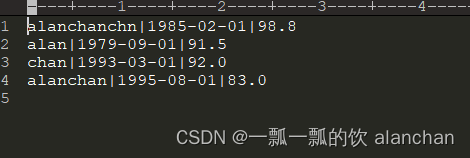
本文介绍了1个示例,即通过spring boot 启动spring batch的任务,该任务是通过注解实现的。文件位置:/sping-batch/src/main/resources/student-data.txt。本文使用的是jdk8版本,最新版本的spring core和springb batch用不了。以上,通过spring boot 启动spring batch的任务,该任务是通过注解实
文件位置:/sping-batch/src/main/resources/spring-batch-context4.xml。文件位置:/sping-batch/src/main/resources/spring-batch-context5.xml。文件位置:/sping-batch/src/main/resources/context-datasource2.xml。以上,介绍了2个示例,即从
代理模式上,基本上有Subject角色,RealSubject角色,Proxy角色。Subject角色负责定义RealSubject和Proxy角色应该实现的接口;RealSubject角色用来真正完成业务服务功能;Proxy角色负责将自身的Request请求,调用realsubject 对应的request功能来实现业务功能,自己不真正做业务。代理对象和被代理对象一般实现相同的接口,调用者与代理

本文介绍几种简单的并发测试方法。本文分为。
