




- @chensq_yinhai
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
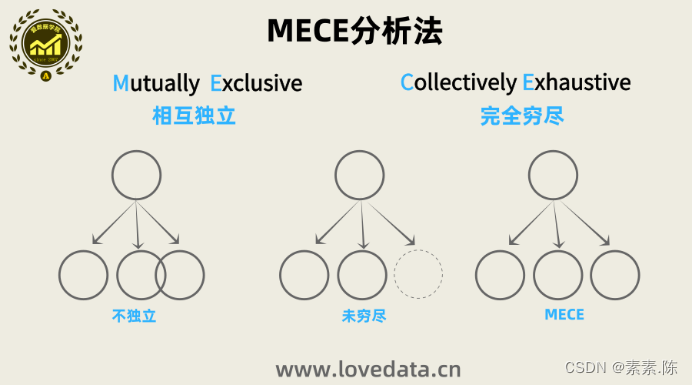
什么是框架性思维?它是由一个个的思维框架积累而来。本文介绍分析常用的几个思维框架。一些职位描述中会要求分析师有框架性思维,能够被考察的是思维框架,通过思维框架判断框架性思维能力。笔者查阅了多篇文章,定义思维框架为:思考问题的套路,本质是在不断发现问题分析问题解决问题的过程中沉淀的行之有效的方法论。不同行业、不同岗位思维框架不同,不同领域、不同学科思维框架不同。
【代码】python 调用Dify接口的示例。
一般我们会把数据的整合、预处理过程及需要展示的数据处理过程放到oracle中,而把模型运算放到python中。因此造成了运维人员的工作复杂度,因此把oracle存储过程的调用权限给python,是一种很好的选择。下面我把自己用python调用oracle中需要注意的细节在这里阐述一番。以代码的形式展示如下:import cx_Oracle as cxaddress = "用户名/密码@IP:端口/

select t.table_nameas 表名称,c1.comments as 表备注,c2.column_name as 字段名称,c2.data_type as 字段类型,c2.data_length as 字段长度,c3.comments as 字段备注from-- 查询指定用户下的表名称(select table_name from all_all_tables where owner

【代码】向RAGFlow中上传文档到对应的知识库。
【代码】python 调用Dify接口的示例。
之前写过py访问oracle的代码,这次在之前的基础上加工而成,把过程记录下来,方便日后查阅!def pyVisitHive(params ,sql_text):from pyhive import hiveimport pandas as pdconn=hive.Connection(host = params.get('ip'),port = params.get('port'),
在机器学习的二分类问题中,IV值(Information Value)主要用来对输入变量进行编码和预测能力评估。特征变量IV值的大小即表示该变量预测能力的强弱,在面对大量变量的情况下,可计算各个变量的IV值,取IV值大于某个固定值的变量参与到模型中去,这样不仅保留了特征携带的信息量。且提高了模型效率,此外有利于给客户解释和汇报。2. IV值计算(python 代码如下)#######...

kingbase 数据库存储过程
数据挖掘有人说,大数据是新时代的黄金和石油,掌握了它,就掌握了新经济的命脉;用好了它,就拥有了新战略型资源。数据挖掘,就是从大量的,不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们实事先不知道的,但又是潜在有用的信息和知识的过程。大数据研发的目的是利用大数据技术去发现大数据的价值并将其应用到相关领域,通过大数据的处理相关问题促进社会的发展。数据挖掘的内容集中在几个方面上,即