




- @blink182007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Docker拉取镜像失败解决方案 摘要:在执行docker pull命令下载vllm/vllm-openai:v0.10.1.1镜像时出现错误,多个文件层下载失败,最终报错"failed to copy"和"EOF"。建议尝试以下解决方法: 更换网络环境或使用加速节点 重新执行拉取命令 检查网络连接稳定性 确认Docker服务运行正常 该错误通常由网络连接问
(16条消息) 【TensorRT】TensorRT was linked against cudnn 8.6.0 but loaded cudnn 8.3.2_半路转行的水博的博客-CSDN博客。(16条消息) win10下 yolov8 tensorrt模型加速部署【实战】_FeiYull_的博客-CSDN博客。(16条消息) Win10环境下yolov8快速配置与测试_FeiYull_的博客
添加红色框里边的三条DNS服务器解析地址,复制放到/etc/resolv.conf添加覆盖之前的就行。执行修改了 /etc/host 文件,wq!我的是WSL2子系统,当前网络的DNS服务器发生变化了。此时若不打开科学上网络,返回。此时若打开科学上网络,返回。至此,问题已得到解决!

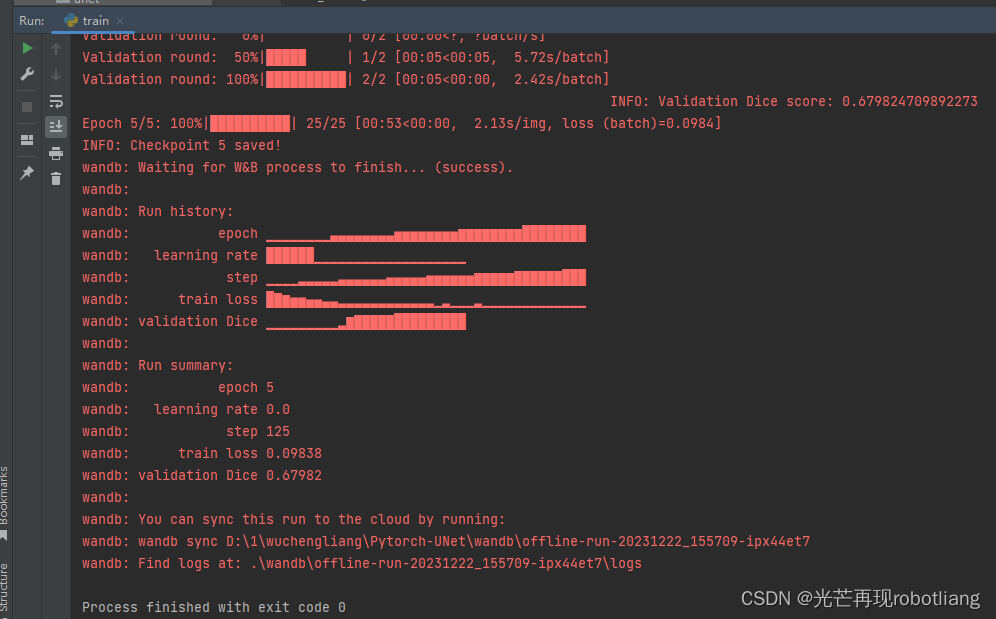
learning_rate: float = 1e-5 ——>修改为——> learning_rate: float =0.0001。发现dice值无论和validation Dice始终为负值和趋近于(无限接近于0)0,具体情况如下图所示。tips:一旦成功得到各项指标以后,再把学习率改回去,可能就无法复现之前的“趋近于0”的现象了。再次尝试运行就可以正常输出得到正常的各项Dice值了。将tra
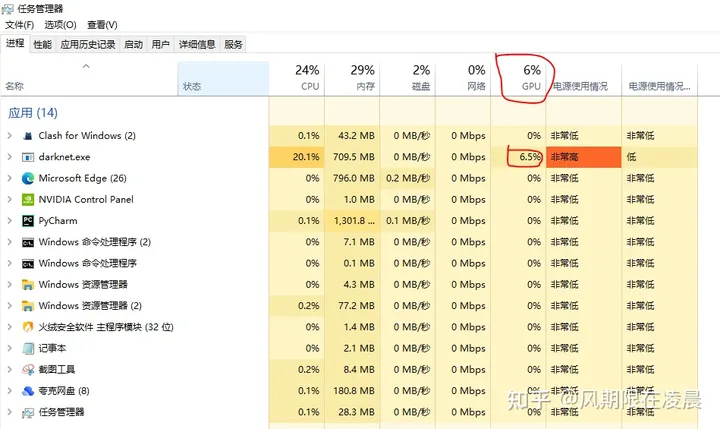
我刚安装了全新的RTX 4080GPU,以便在运行机器学习脚本时加快训练过程。我看不到GPU使用率超过10%,这可能意味着代码没有跑起来。对于不熟悉任务管理器视图的情况下来说,原因并不那么明显。我所做的假设是Windows任务管理器将仅显示整体GPU使用情况。经过一番思考,我意识到 GPU 内存使用率是比较之高的,所以GPU其实一定做了很多工作,然后我意识到我追求的指标是“CUDA”性能,默认情况
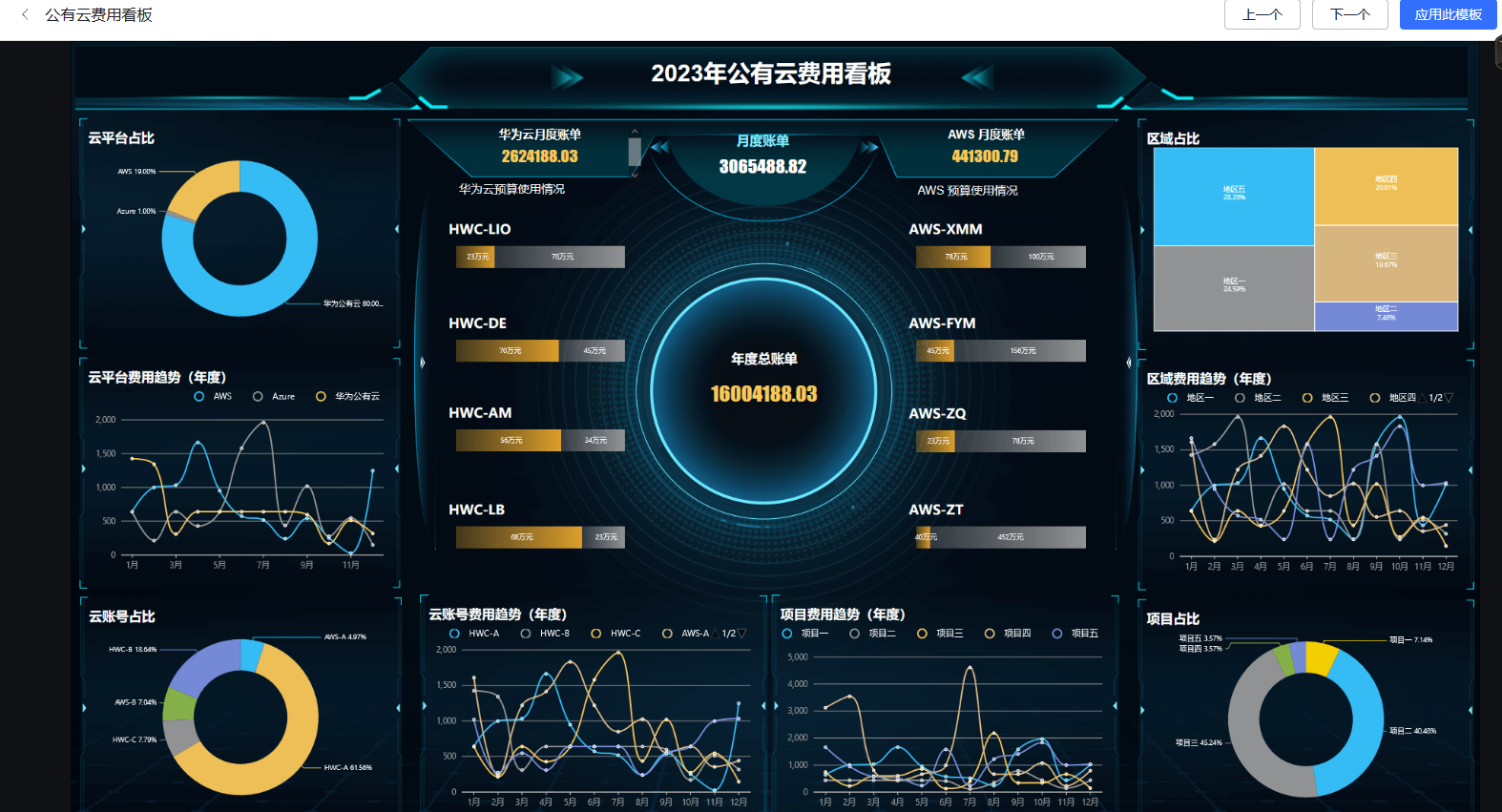
单独对dataease-2.2\core\core-frontend和dataease-2.2\core\core-backtend进行生命周期的mvn clean install。基于这些模板就可以构建自己的大数据可视化的看板了。多留意——dataease-2.2\core\core-frontend路径下的pom.xml文件内的注释和上面的参考教程具体细节,需要手动修改。最后的目的是基于产出的
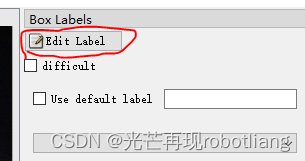
点击这个Box Labels里面的Edit Label即可,进行对需要修改的类名称进行修改即可,如果直接修改classes.txt文件,在里面强行增加一个类,可能会无法起到任何作用,且labelimg还可能出现list out of range这种报错。
: 无法将“E:\anaconda333\Scripts\conda.exe”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果。所在位置 E:\360MoveData\Users\14508\Documents\WindowsPowerShell\profile.ps1:4 字符: 4。最近卸载又重装了anaconda3,然后就报错了,简单记录一下解决。经典老问题了

添加红色框里边的三条DNS服务器解析地址,复制放到/etc/resolv.conf添加覆盖之前的就行。执行修改了 /etc/host 文件,wq!我的是WSL2子系统,当前网络的DNS服务器发生变化了。此时若不打开科学上网络,返回。此时若打开科学上网络,返回。至此,问题已得到解决!
learning_rate: float = 1e-5 ——>修改为——> learning_rate: float =0.0001。发现dice值无论和validation Dice始终为负值和趋近于(无限接近于0)0,具体情况如下图所示。tips:一旦成功得到各项指标以后,再把学习率改回去,可能就无法复现之前的“趋近于0”的现象了。再次尝试运行就可以正常输出得到正常的各项Dice值了。将tra