- @babyai996
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
dlib 的人脸检测算法使用的是基于 HOG 特征和级联分类器的方法。级联分类器是一种多层分类器,每一层都是一个弱分类器,通过级联的方式可以得到一个强分类器。dlib 的人脸检测算法使用了一个 5 层的级联分类器,可以在不同尺度的图像中检测出人脸。dlib 的人脸特征提取算法使用的是基于深度学习的方法。具体来说,它使用了一个 29 层的卷积神经网络,可以将人脸图像转换为一个 128 维的向量,这个

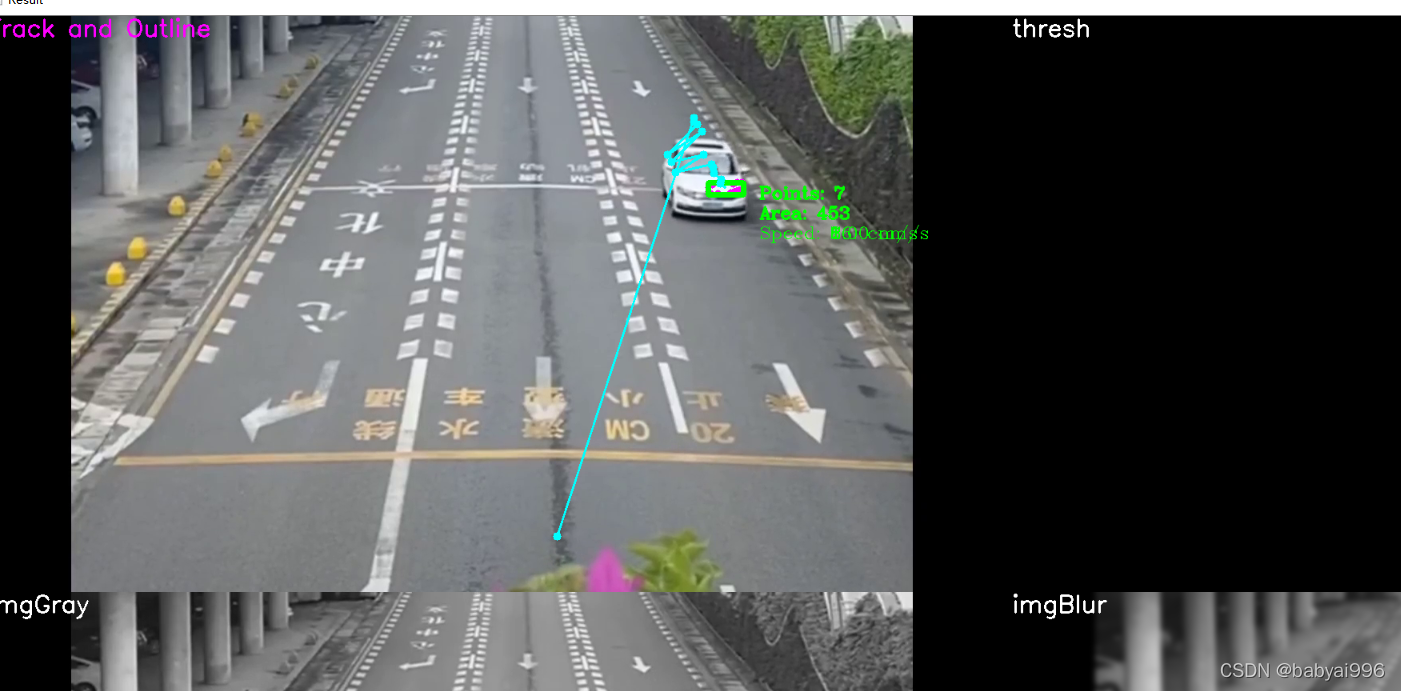
基于matlab的运动目标检测与跟踪算法研究clcclear allclose allstart = 1 ;%可以识别不同格式的视频%folder_name = 'denis_walk.avi' ;folder_name = 'denis_run.avi' ;%folder_name = 'run.avi' ;%folder_name = '1.wmv' ;%folder_name = 'davi
随着社会经济的发展,选择到超市购物的消费者越来越多,超市排长队付账的矛盾也越来越突出。对此,我们提出一种新型的购物车,通过识别商品录入同时放入购物车中,并利用检测系统检测是否与已知的商品信息相匹配,并把商品信息传送到显示屏上。实现人工智能识别超市商品商品效果图:效果视频:、python yolo超市商品识别项目代码下载:链接:https://pan.baidu.com/s/1Ha7Y3-qW-ev

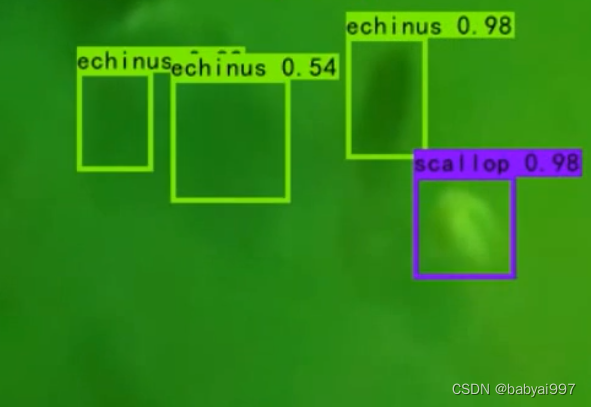
准确率表示模型对正确目标的识别率,召回率表示模型对所有目标的识别率,精确率表示模型对所有预测目标的正确率,F1 分数表示准确率和召回率的调和平均数,平均精度表示模型在所有类别上的平均精度。本文提出了一种基于 YOLOv5 的水下海洋目标检测方法,使用数据增强方法进行了大量实验,并与其他方法进行了对比,实现了在检测各种不同的海洋环境和水下目标中都取得较高的准确率,具有较好的泛化能力。YOLOv5是一
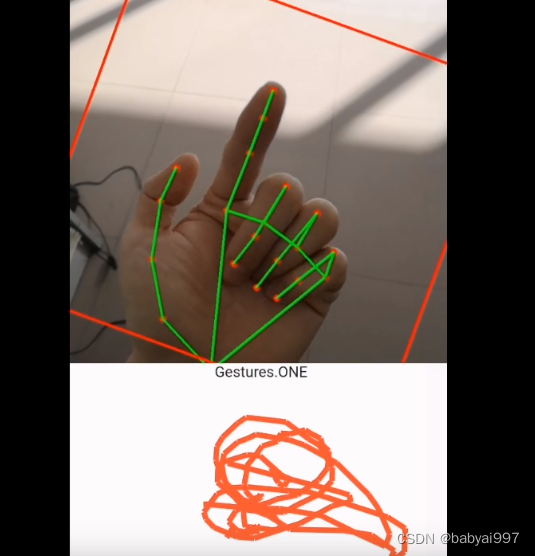
基于Android的openpose手势交互手势识别。
随着人工智能技术的飞速发展,AI已经逐渐渗透到教育领域的各个方面,改变了传统的教学模式和学习方式。AI技术不仅能提高教学效率,还能为学生提供个性化的学习体验,尤其在当前教育资源不均衡的背景下,AI工具为教育带来了新的可能性。本报告将全面总结目前教学中能够使用的AI工具,包括真实应用案例、背后的技术工具名称和使用的网址,旨在为教育工作者和学习者提供参考。

YOLOv10(You Only Look Once version 10)是清华大学研究人员开发的最新目标检测算法,是YOLO系列模型的最新版本。与前几代YOLO相比,YOLOv10在模型架构和训练方法上都有显著创新。YOLOv10的核心思想是通过深度神经网络直接从图像中预测边界框和类别概率,实现端到端的目标检测。

是一个特殊的常量,通常用于判断输入是否已经结束。当你从文件或标准输入(比如键盘)读取数据时,如果到达了文件的末尾或者用户输入了结束信号(比如按下。是一种常见的方法,适用于需要逐个字符处理输入的场景。为了让大家更容易理解,我们可以简化代码,避免复杂的操作。会从标准输入读取一个字符,并返回其ASCII值。是一个标准库函数,用于从标准输入(通常是键盘)读取一个字符。就像是书的最后一页,当你读到最后一页时

有一个分数序列 q1p1,q2p2,q3p3,q4p4,q5p5,....�1�1,�2�2,�3�3,�4�4,�5�5,.... ,其中qi+1=qi+pi��+1=��+��, pi+1=qi,p1=1,q1=2��+1=��,�1=1,�1=2。比如这个序列前66项分别是21,32,53,85,138,211321,32,53,85,138,2113。时间限制: 1000 ms内存限制:

基于计算机视觉技术的入侵检测通过设计图像处理方法实现对某一动态场景的实时观测,并在场景存在外来入侵情况时向上层管理系统发送入侵检测结果;要求独立编写具有以下功能模块的程序源码,1. 通过手机/个人笔记本内置摄像机连续观测某一动态场景;2. 获取摄像机实时视频流数据,并以一定时间间隔以jpg/bmp/png形式保存图片至本地;3. 至少对图像进行一种预处理,如高斯平滑、直方图均衡化等;4. 场景存在