- @Z0709D
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了基于Spark的粤港澳大湾区气象分析系统Mint的设计与实现。系统采用三台虚拟机搭建分布式Hadoop集群,集成Spark、Hive、Flink等大数据组件,构建了多源气象数据采集处理体系。通过实时和离线双通道采集气象数据,利用Spark进行批处理分析和LSTM等算法预测,最终通过Django实现数据可视化展示和AI智能解读。系统具备气象数据采集、处理、分析、预测及可视化功能,为粤港澳大
基于ElasticSearch 7.10.0和Kibana的二手房搜索与数据分析系统。系统通过爬取广东省链家网2万多条房源数据,实现高效检索、数据分析和可视化展示。核心功能包括:1)利用ElasticSearch实现条件筛选、高亮显示和聚合分析;2)通过Kibana构建可视化大屏,展示TOP小区行情、价格区间分布等;3)采用REST API完成索引设计、数据CRUD操作及高级查询。系统架构充分发挥
简单手写Jar包完成数据筛选计算,通过Hadoop完成任务并存储在hive中。利用Django和echarts完成数据可视化
本文介绍了Python爬虫框架Scrapy的基本使用指南。Scrapy是一个高效的异步爬虫框架,包含Spider(核心爬取逻辑)、Item(数据结构)、Pipeline(数据处理)、Middleware(请求响应处理)和Settings(全局配置)等核心组件。文章详细讲解了如何安装Scrapy、创建项目、编写爬虫代码、定义数据模型,以及配置中间件和管道。同时介绍了Scrapy的性能优化设置、数据存
本文介绍了基于Spark的粤港澳大湾区气象分析系统Mint的设计与实现。系统采用三台虚拟机搭建分布式Hadoop集群,集成Spark、Hive、Flink等大数据组件,构建了多源气象数据采集处理体系。通过实时和离线双通道采集气象数据,利用Spark进行批处理分析和LSTM等算法预测,最终通过Django实现数据可视化展示和AI智能解读。系统具备气象数据采集、处理、分析、预测及可视化功能,为粤港澳大
简单手写Jar包完成数据筛选计算,通过Hadoop完成任务并存储在hive中。利用Django和echarts完成数据可视化
本文介绍了使用MaxKB构建AI知识库并实现数据库查询与AI问答功能的完整流程。首先说明了MaxKB作为企业级智能体平台的特点,支持多种大模型接入和知识库构建。详细讲解了基于Docker的安装部署步骤,包括镜像拉取、容器创建等。重点演示了如何通过MaxKB连接DeepSeek API和MySQL数据库,构建包含SQL生成、数据查询和AI对话的工作流,并提供了具体的提示词设置方案。文章还总结了实践过
本文介绍了使用MaxKB构建AI知识库并实现数据库查询与AI问答功能的完整流程。首先说明了MaxKB作为企业级智能体平台的特点,支持多种大模型接入和知识库构建。详细讲解了基于Docker的安装部署步骤,包括镜像拉取、容器创建等。重点演示了如何通过MaxKB连接DeepSeek API和MySQL数据库,构建包含SQL生成、数据查询和AI对话的工作流,并提供了具体的提示词设置方案。文章还总结了实践过
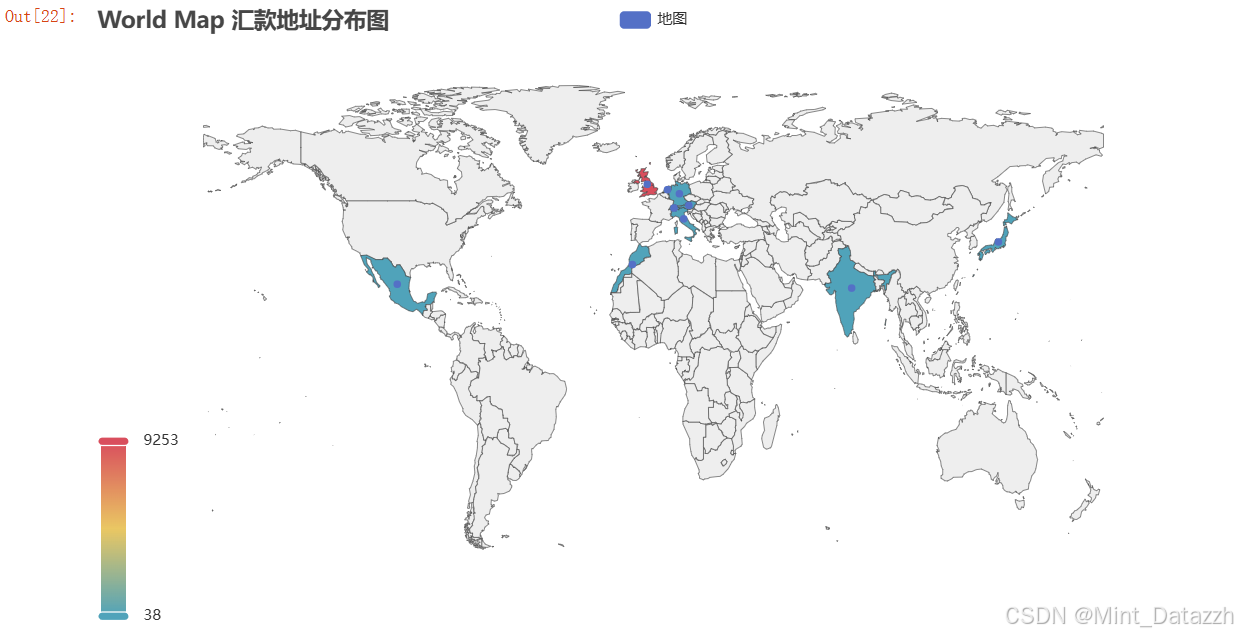
python数据分析期末案例
暴力破解简单加密rar文件