




- @March_A
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目标检测中的指针识别。
Keras是一个高层次的深度神经网络框架接口,由Python 编写而成并基于TensorFlow、Theano及CNTK后端,相当于TensorFlow、Theano、CNTK的上层接口,具有操作简单、上手容易、文档资料丰富、环境配置容易等优点,但因其过度封装导致缺乏灵活性、使用受限。自然语言处理(NLP):是计算机科学,人工智能,语言学关注计算机和人类自然语言之间的相互作用的领域。1. np.s

ResNet在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。
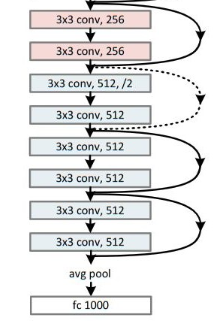
GoogLeNet在2014年由Google团队提出。GoogLeNet模型参数只有VGG的 1/20 。GoogLeNet在2014年由Google团队提出,斩获当年ImageNet竞赛中 Classification Task (分类任务) 第一名。网络中的亮点:图片尺寸变换:Inception结构 注意:每个分支所得的特征矩阵高和宽必须相同1.2 定义模型1.4 模型训练
加入了 dropout 后,输入的特征都存在被随机清除的可能,所以该神经元不会再特别依赖于任何一个输入特征,也就是不会给任何一个输入特征设置太大的权重。通过传播过程,dropout 将产生和 L2 正则化相同的收缩权重的效果。对于不同的层,设置的keep_prob大小也不一致,神经元较少的层,会设keep_prob为 1.0,而神经元多的层则会设置比较小的keep_prob通常被使用在计算机视觉领
根据已知用户购买、浏览数据,对用户未来的购买意向,进行预测。提前知道用户购买意向,可以大大提升,电商平台对物流的掌控力度,提前备货。对消费者也是一定好处,商品购买意向预测,相当于商品找消费者,实现个性化服务,消费者购物体验会大大提升~数据加载数据探索特征工程算法筛选模型评估。
找出性价比较高的车:python:sklearn标签编码(LabelEncoder) sklearn.preprocessing.LabelEncoder的使用:在训练模型之前,通常都要对数据进行一定得处理。将类别编号是一种常用的处理方法,比如把类别“电脑”,“手机”编号为0和1,可使用LabelEncoder函数。作用:将n个类别编码为0~n-1之间的整数(包括0和n-1)聚类种类最佳参数kme
正确的边界框(ground truth)中除去被预测正确的边界框,剩下的边界框的数量。预测出的所有边界框中除去预测正确的边界框,剩下的边界框的数量。不同recall下的最高precision的均值。即模型给出的所有预测结果中命中真实目标的比例。一个没有被检测出来的ground truth。即模型给出的预测结果最多能覆盖多少真实目标,模型给出的所有预测结果中命中真实目标的比例。被找到的正确目标和所有
要点:Faster R-CNN算法流程可分为3个步骤对于特征图上的每个3x3的滑动窗口,计算出滑动窗口中心点对应 原始图像上的中心点,并计算出k个anchor boxes (注意和proposal的差异)。对于一张1000x600x3的图像,大约有 60x40x9(20k)个anchor,忽略跨越边界的 anchor以后,剩下约6k个anchor。对于RPN 生成的候选框之间存在大量重叠,基于候选