- @Learning_xzj
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
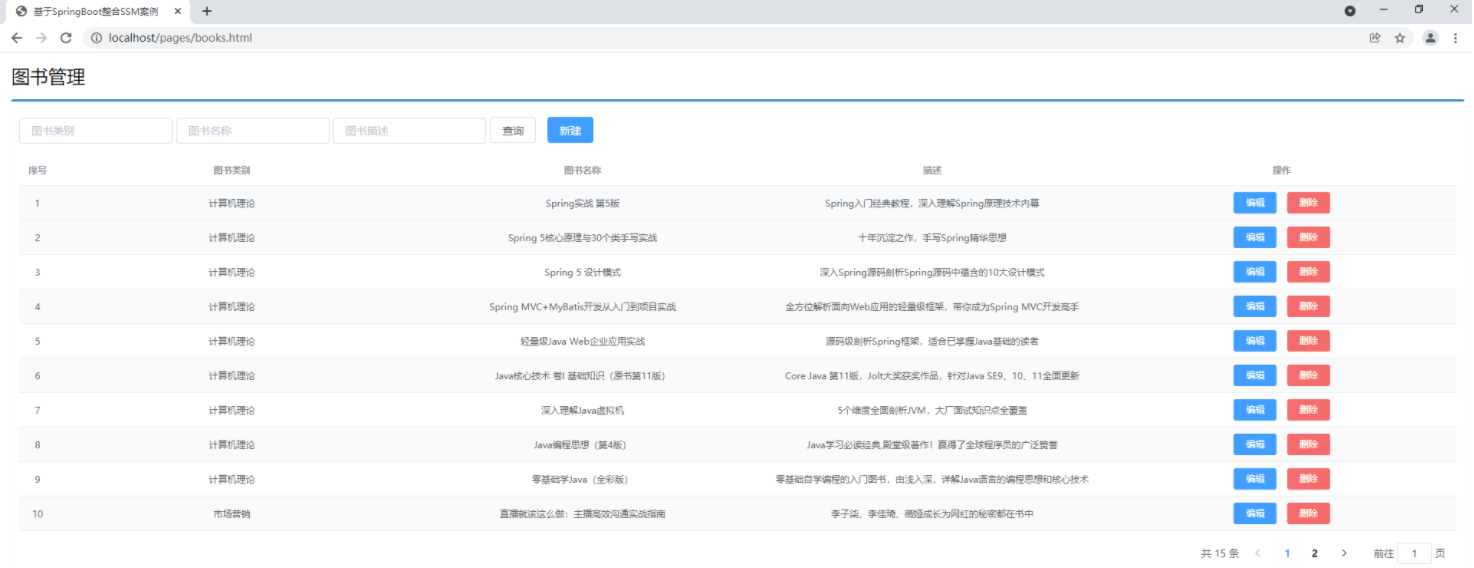
本文所涉及的代码已经编译打包到我的云服务器中:http://47.106.176.37:8080/pages/books.html 欢迎大家测试访问。主页面添加删除修改分页条件查询希望通过这个案例,各位小伙伴能够完成基础开发的技能训练。整体开发过程采用做一层测一层的形式进行,过程完整。页面数据模型定义异步请求获取数据这样在页面加载时就可以获取到数据,并且由VUE将数据展示到页面上了。默认
APIAPI:Application Programming Interface 应用程序编程接口
来源:依旧英语公众号的“回译”模块。回译法学英语中文:人工智临诸多挑战,最棘手的是树立正确的伦理规范。补充词汇:1. artificial intelligence 人工智能2. ethics 伦理译文:(1)my version(may be some errors)Artificial intelligence are fac...
Spring Boot的核心功能就是为整合第三方框架提供自动配置,SpringBoot之所以好用,就是它能方便快捷的整合其他技术,这一部分咱们就来聊聊一些技术的整合方式,通过本文的学习,大家能够感受到SpringBoot到底有多酷炫。本文将学习如下技术的整合方式:- 整合JUnit- 整合MyBatis- 整合MyBatis-Plus- 整合Druid......
什么是iframe标签?iframe标签是一个双标签/围堵式标签<iframe></iframe>,是一个内联框架iframe标签的作用?用于在当前的HTML页面中嵌入另一个文档,比如当好几个页面都有大部分的相同内容(相同的页面头部和底部),那么这些相同的页面部分可以放在新的页面中,然后就可以使用<iframe>标签将重复的内容嵌入到各个页面中。iframe标签
转载!!!原文地址:https://blog.csdn.net/weixin_44710964/article/details/104502602?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0.control&spm=1001.2101.3001.4242last-chi
下面通过例子来示范@ConditionalOnClass注解的用法。首先创建一个Maven项目,定义如下配置类:上面配置类使用了@ConditionalOnClass(name=“com.mysql.cj.jdbc.Driver”)修饰,这意味着只有当com.mysql.cj.jdbc.Driver类存在时,该配置类才会上面配置类使用了@ConditionalOnClass(name=“com.m
应用程序直接与数据库打交道,访问效率低为了改善上述现象,开发者通常会在应用程序与数据库之间建立一种临时的数据存储机制,该区域中的数据在内存中保存,读写速度较快,可以有效解决数据库访问效率低下的问题。这一块临时存储数据的区域就是缓存。使用缓存后,应用程序与缓存打交道,缓存与数据库打交道,数据访问效率提高。缓存是什么?缓存是一种介于数据永久存储介质与应用程序之间的数据临时存储介质,使用缓存可以有