




- @JR521314
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
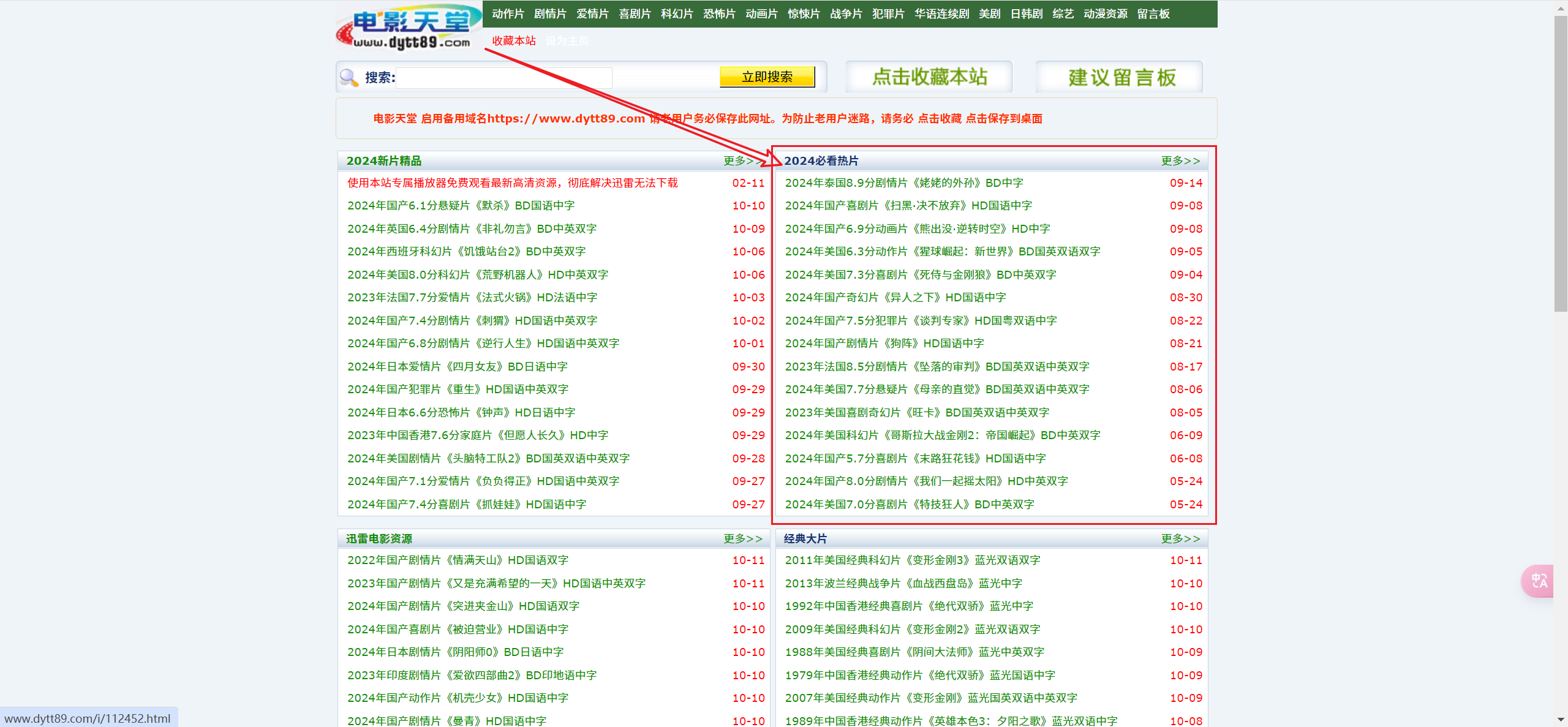
【代码】爬虫3: 抓取电影天堂2024必看热片。
项目简介:使用LSTM模型, 对文本数据进行预测,每次截取字符20, 对第二十一个字符进行预测,LSTM层: units=100, activation=reluDense层: units=输入的文本中的字符种类, 比如我使用的文本有644个不同的字符, 那么units=64激活函数: 因为是多分类, 使用softmax因为这是最后一层, 所以输出神经元的个数也就是644。

1.1.数据收集获取1.2.数据集导入2.1.数据基本处理2.1.数据可视化2.2.缺失值/异常值处理2.3.数据集分割2.2.特征工程3.1.特征预处理3.2.特征选择3.3.特征转换3.1.构建模型选择合适框架ANN,CNN,RNN,FCN填充模型模型的层数每层的神经元数量选用的激活函数3.2.编译模型选择损失函数: 用于衡量模型预测值和实际值之间的差距。

1.如果想要让模型训练的数据得到的结果一致, 需要保证模型使用的训练集和测试集是一样的, 可以设置一下算法的random_state来确保一致。从scikit-learn 0.24 版本开始, joblib 已经不再包含在 sklearn.externals 子模块中了。3.加载模型需要一个变量进行承接, 为了方便, 可以用estimator来承接。filename-要加载读取的模块文件名和路径。

项目简介:使用LSTM模型, 对文本数据进行预测,每次截取字符20, 对第二十一个字符进行预测,LSTM层: units=100, activation=reluDense层: units=输入的文本中的字符种类, 比如我使用的文本有644个不同的字符, 那么units=64激活函数: 因为是多分类, 使用softmax因为这是最后一层, 所以输出神经元的个数也就是644。
模型在训练集和测试集上表现不错, 训练集准确率接近100%, 测试集准确率70%左右,但使用在百度上下载的猫狗图片进行二分类预测时, 测试结果全部显示[0], 也就是猫,希望路过的大佬能指点一下, 请收下我的膝盖!

项目简介:使用LSTM模型, 对文本数据进行预测,每次截取字符20, 对第二十一个字符进行预测,LSTM层: units=100, activation=reluDense层: units=输入的文本中的字符种类, 比如我使用的文本有644个不同的字符, 那么units=64激活函数: 因为是多分类, 使用softmax因为这是最后一层, 所以输出神经元的个数也就是644。
本文摘要介绍了Python函数和模块的核心知识点。函数部分包括内置函数(input/print)、格式化输出(%s/f-string)、函数定义(def)、参数传递方式(位置/关键字/缺省/不定长)和匿名函数(lambda)。模块部分涵盖常用内置模块(builtins/json/datetime/socket等)的功能,包括模块导入语法(import/from...as)、数据格式转换(json处

【摘要】在CentOS7安装Docker时,因阿里云镜像异常导致containerd.io包下载失败。解决方案:1)清理yum缓存并重建;2)更换为清华镜像源;3)安装依赖工具;4)修改docker-ce.repo文件中的下载地址;5)重新执行安装命令。最终成功安装并验证Docker版本。该问题主要因镜像源异常引起,通过切换国内可靠镜像源可有效解决下载校验失败的问题。

1.1.数据收集获取1.2.数据集导入2.1.数据基本处理2.1.数据可视化2.2.缺失值/异常值处理2.3.数据集分割2.2.特征工程3.1.特征预处理3.2.特征选择3.3.特征转换3.1.构建模型选择合适框架ANN,CNN,RNN,FCN填充模型模型的层数每层的神经元数量选用的激活函数3.2.编译模型选择损失函数: 用于衡量模型预测值和实际值之间的差距。