- @JDDTechTalk
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
点击「京东数科技术说」可快速关注「摘要」本文是作者在经历传统保险电销和互联网电销的数据分析实践中进行的一些思考沉淀,或有不足不到之处,欢迎交流指正。◆◆◆电销过程电话销售的过程基...
本文是对 “Neural Architecture Search: A Survey”的翻译,这篇Paper 很好的总结分析了 NAS 这一领域的研究进展。摘要在过去几年中,深度学习在各种任务上(例如图像识别,语音识别和机器翻译)取得了显著进步。这一进步的关键方面之一是新颖的神经架构。目前使用的架构大多是由人类专家开发设计的,这是一个耗时且容易出错的过程。因此,人们对自动神经网络搜索方法越来越感兴
Vicuna模型在整体表现和推理效率上可以说是秒杀Alpaca模型的,对多种自然语言(包含中文)的支持也要远远好于Alpaca模型,确实像社区所说的,目前Vicuna模型可以说是开源大模型的天花板了
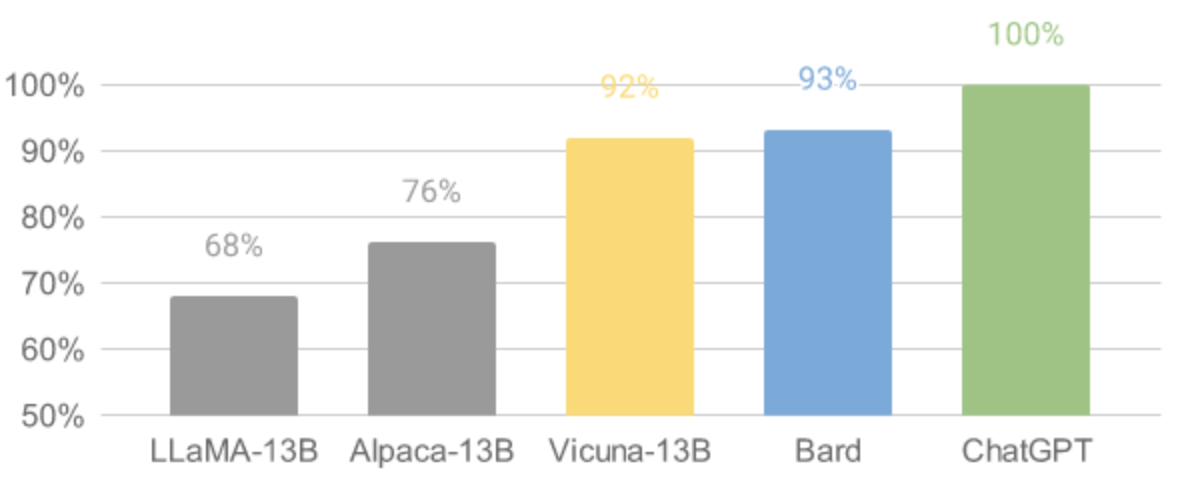
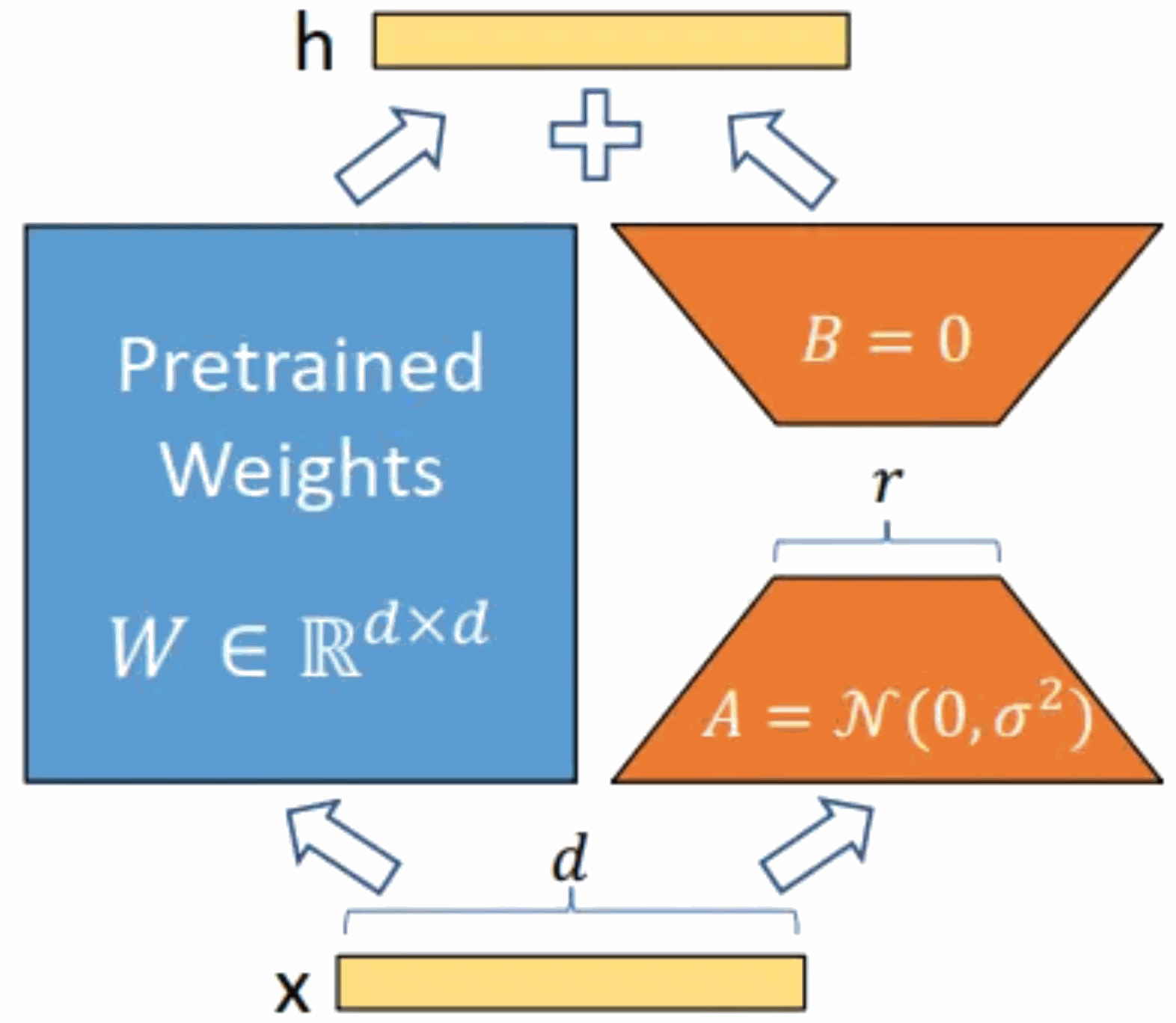
本文进行本地化部署实践的Alpaca-lora模型就是Alpaca模型的低阶适配版本。本文将对Alpaca-lora模型本地化部署、微调和推理过程进行实践并描述相关步骤。
点击「京东数科技术说」可快速关注「摘要」在以互联网为核心,信息不断发展的今天,文本信息作为最重要的网络资源,其中隐含着大量的模式与知识亟待发现与利用。虽然在广泛的数据资源中充斥着大量非...
点击「京东数科技术说」可快速关注京东数科区块链开源底层引擎JD Chain自2019年第一季度正式开源后,得到了诸多企业研发人员、个人开发者的使用反馈。结合这些来自实际应用场景方面的宝...
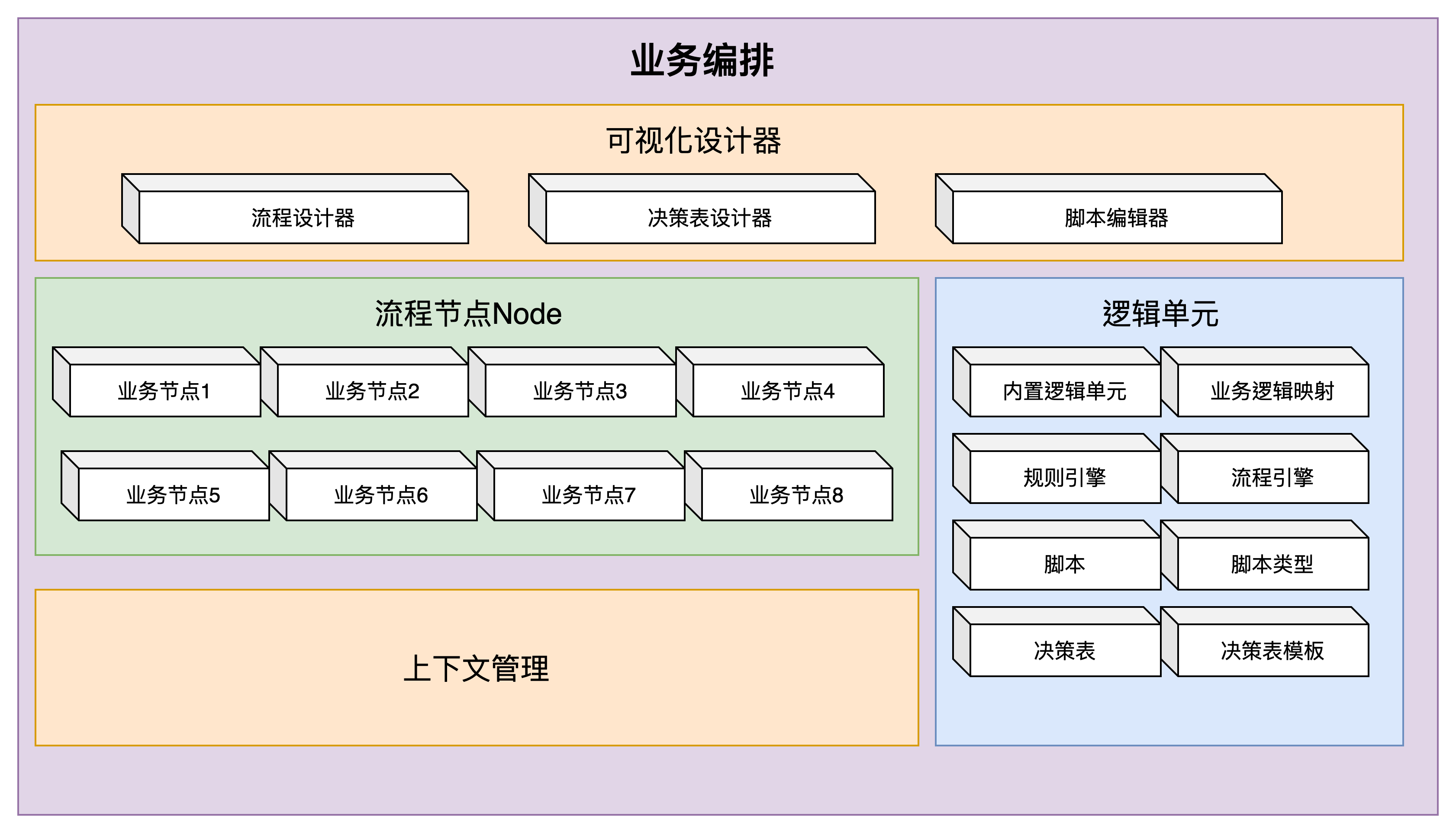
业务编排是实现低代码的路径之一,但不是唯一路径。尤其是当我看到ChartGPT4.0出来之后,人工智能,可以通过一个网页草图自动生成html代码时,我觉得,这可能才是低代码的最终归宿吧。
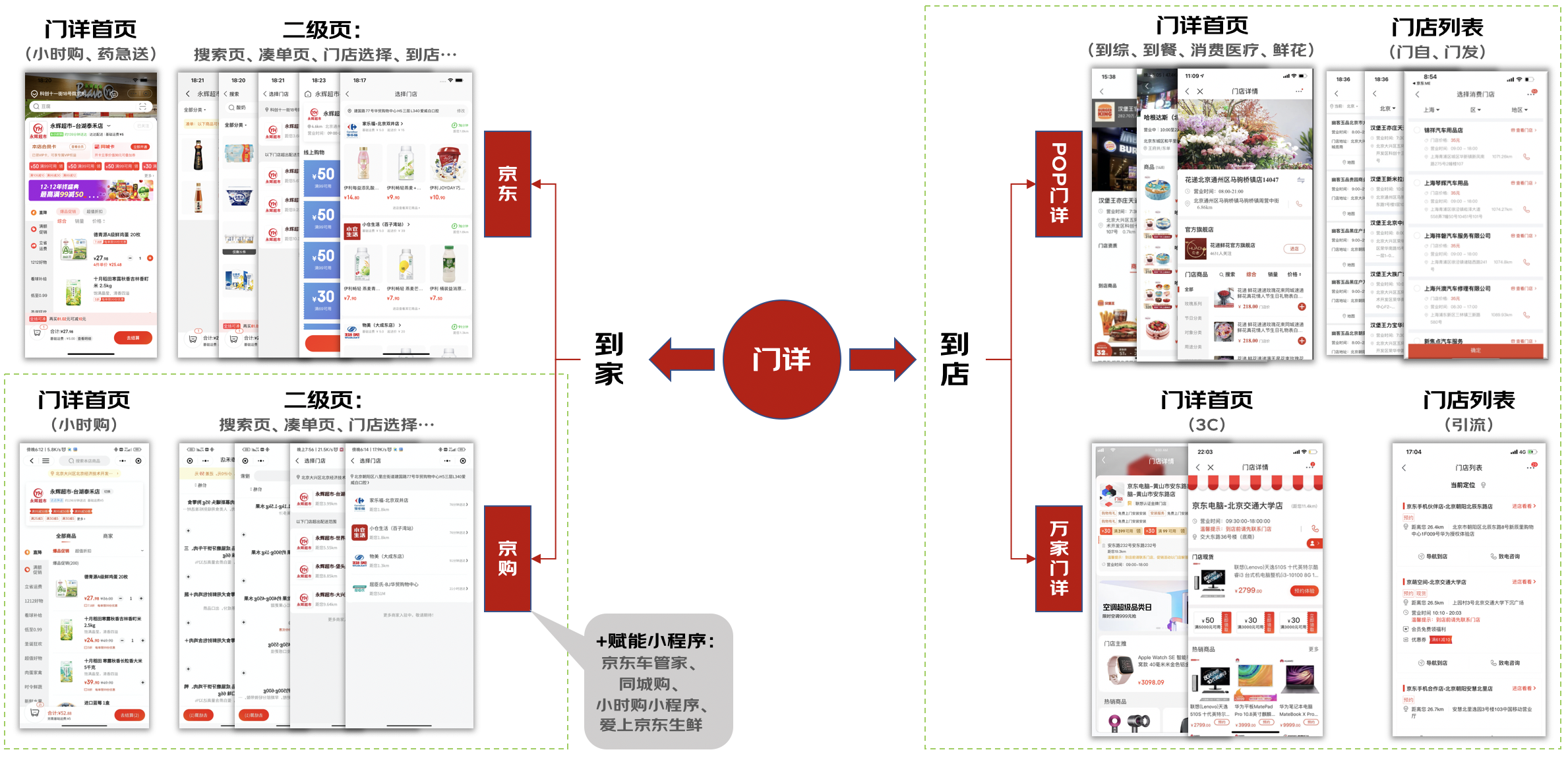
本文主要讲述京东门详业务在支撑过程中遇到的困境,面对问题我们在效率提升、质量保障等方向的探索和实践,在此将实践过程中问题解决的思路和方案与大家一起分享,也希望能给大家带来一些新的启发
key是widget、element和semanticsNode的唯一标识,同一个parent下的所有element的key不能重复,但是在特定条件下可以在不同parent下使用相同的key,比如page1和page2都可以使用ValueKey

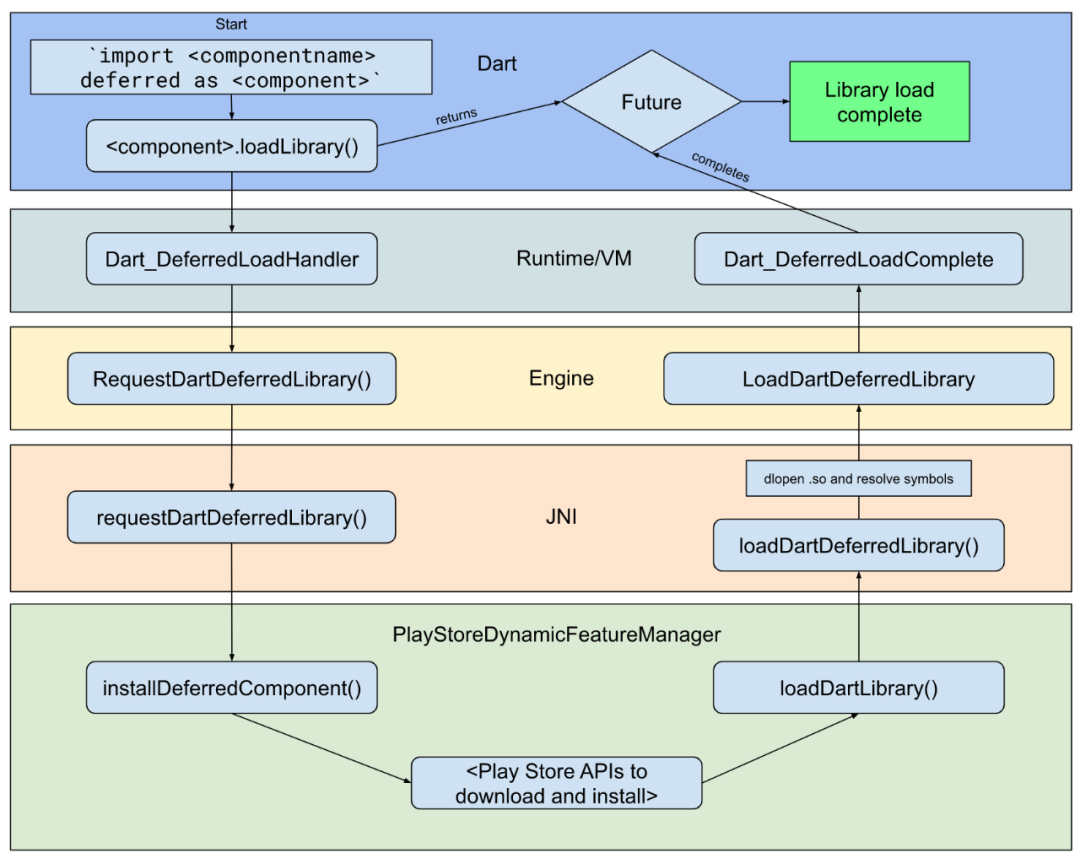
Deferred Components,官方实现的Flutter代码动态下发的方案。本文主要介绍官方方案的实现细节,探索在国内环境下使用Deferred Components,并且实现了最小验证demo。读罢本文,你就可以实现Dart文件级别代码的动态下发。