




- @EQUINOX1
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
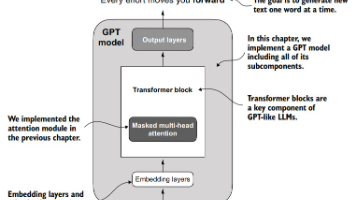
这一章作者带着手搓了一下GPT 2的architecture,架构还是比价清晰易懂的。ch04。
这篇论文就是后面经典的Vision Transformer,核心思想很直接:将一张图片切成一系列固定大小的patch,把一个 patch 当作NLP任务中的一个token,然后送入标准 Transformer Encoder 做图像分类。它证明了在足够大规模数据预训练的条件下,纯架构可以在图像识别任多上达到基至超过CNN。打破了 cv 和 nlp 在模型上的壁垒。paper code网站上 Ima

这篇论文就是后面经典的Vision Transformer,核心思想很直接:将一张图片切成一系列固定大小的patch,把一个 patch 当作NLP任务中的一个token,然后送入标准 Transformer Encoder 做图像分类。它证明了在足够大规模数据预训练的条件下,纯架构可以在图像识别任多上达到基至超过CNN。打破了 cv 和 nlp 在模型上的壁垒。paper code网站上 Ima
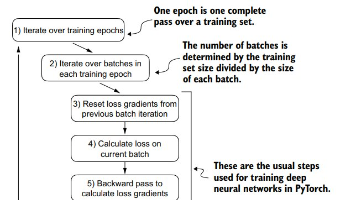
本章主要讲了下如何评价llm生成文本的质量,如何进行预训练。ch05。
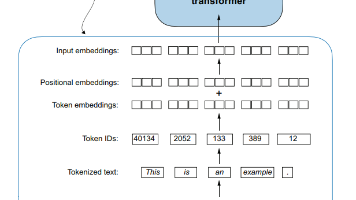
很久没读英文文本了,原作第二章读了有俩小时……总体来说还是非常简单的,主要就是为 llm training 做一些文本预处理的工作。ch02。
本章作为概述,和大部分课程一样,主要目标为 了解基本术语和概念,基本原理。主要以Internet为例。Internet 是一个世界范围的计算机网络,互联了遍及全世界的数十亿计算设备,这些设备可以是传统桌面PC,Linux 工作站以及所谓的服务器,也可以是智能手机,家用电器,汽车等。这些设备我们将其看作节点**主机(host)**以及运行在上面的应用程序主机也称为端系统(end system)端系统

以前我们做图像分类(比如识别猫和狗),第一张图是猫,第二张图是狗,这两张图之间是没有关系的。这叫“独立同分布”。但在现实中,很多数据是有顺序、有前后依赖的:这种**“时间顺序极其重要”的数据,就叫序列数据**。处理这类数据的模型,就是序列模型。假设 xtx_txt 代表第 ttt 天的股票价格。教材中说,交易员想预测第 ttt 天的价格 xtx_txt,他手上的筹码是过去所有的价格:xt−1,

二进制倍增扩展,设当前扩展长度为b,每次尝试往后新加入b个元素,然后求SPD,成功就将b * 2,否则b / 2,并且恢复数组。这样做的复杂度是O(N^2)的,因为我们要维护一个有序数组,每次暴力插入O(N),求SPD O(N),扩展N次。固定左端点l,然后不断往右尝试加入新元素,一旦加入新元素无法满足SPD <= k,那么再开一个段。先考虑这样一个问题,2n个数配成n个pair (xi, yi)

不想跑模型,水了下群友扔的题。发现是一个很裸的树上背包,大概分析下复杂度就ac了。忽然想起来去年也写过类似的一道树上背包,当时对于复杂度是非常疑惑的,始终无法理解时间复杂度是O(N^2)。今天反而一下就分析出来了,正好记录一下。

在深度学习中,模型很容易“死记硬背”训练数据(即过拟合)。比如,如果训练集里所有的猫都在图片的左边,模型可能会认为“左边有一团毛茸茸的东西”才是猫。图像增广就是在把图片喂给神经网络之前,随机地对它进行一些变换(如:翻转、裁剪、改变颜色、加噪等)。它的好处有两点:变相扩大数据集:一张猫的图片经过10种不同的变换,就变成了10张“相似但不同”的训练样本。提高泛化能力(鲁棒性):打破模型对特定属性(如位
