




- @2503_90237586
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
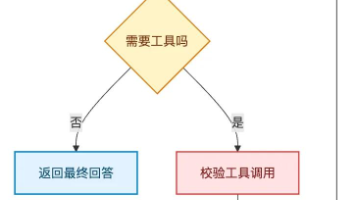
本文探讨了构建最小化Agent执行链的核心思路。作者通过手搓一个仅具备4项基本功能的最小Agent(读取任务、模型决策、工具调用、结果反馈循环),揭示了Agent工程的本质骨架。文章指出,生产级Agent系统(如ClaudeCode、OpenClaw)并非在核心循环上做复杂化,而是围绕这个最小闭环层层构建工具边界、权限控制、记忆管理等运行时保障机制。通过对比早期提示词解析与现代FunctionCa
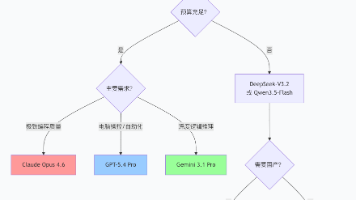
2026年的AI编程战场,正在进入白刃战阶段。Anthropic靠100万Token上下文和顶尖编程能力守住王座,OpenAI用电脑操控能力开辟新赛道,谷歌在推理能力上持续深耕,而国产模型则以肉眼可见的速度缩小差距——GLM-5.1超越Sonnet 4.5 Thinking,DeepSeek V4架构重构蓄势待发。未来已来,只是分布不均。选对工具,你的编程效率可以翻倍;选错工具,你可能会被时代甩下
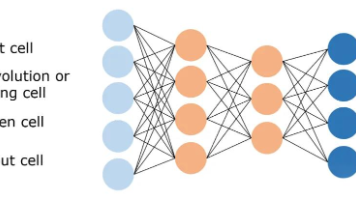
本文系统介绍了深度学习中四种经典神经网络结构:1. CNN通过卷积层提取图像局部特征,池化层降维,适用于图像处理任务;2. RNN通过循环连接处理序列数据,具有记忆功能;3. LSTM改进RNN,通过门控机制解决梯度消失问题,擅长处理长序列;4. Transformer基于自注意力机制,突破序列处理瓶颈,成为NLP领域主流架构。文章详细解析了各网络的结构组成、工作原理及典型应用场景,并介绍了基于T
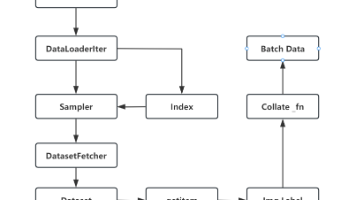
大家可能对DataLoader不太熟悉,但是DataLoader在深度学习有着重要的地位,今天就带大家了解DataLoader的工作流程以及如何通过参数设置进行优化,包括其数据加载和批次处理功能,还提供了代码实践示例,展示了如何创建DataLoader对象以应用于训练和测试数据集。希望对大家有帮助!
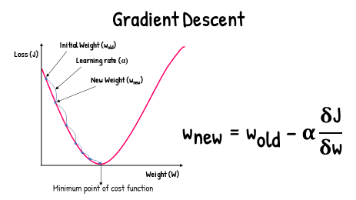
初始化参数:选择一个起始点作为初始参数,这些参数可以是任意值或随机选择的值。计算梯度:计算当前参数点处的。
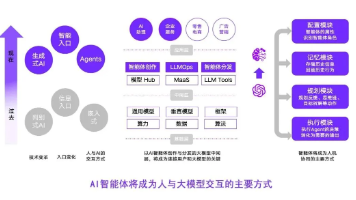
很多人把Agent和大模型混为一谈,其实两者是“升级关系”—— Agent是基于大模型,具备自主决策、任务拆解、工具调用能力的“智能体” ,本质是让大模型从“被动响应”变成“主动做事”。大模型智能体(Agent)的核心,是“让大模型从‘能说’到‘能做’”,它不是替代人类,而是帮人类解放双手,聚焦更有价值的工作。从理论来看,Agent的核心架构(基座、任务规划、工具调用等)是落地的关键;从实践来看,
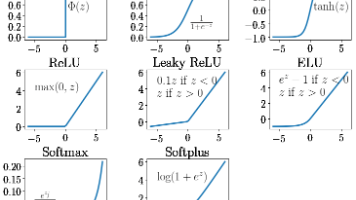
但存在梯度消失问题,且输出不以零为中心。但同样存在梯度消失问题。当输入大于0时,输出等于输入;当输入小于0时,输出为0。解决了ReLU在输入小于0时梯度为0的问题,允许小的梯度流过。将输入向量中的每个元素映射到(0, 1)区间内,并且所有输出元素的和为1。用于回归问题,计算预测值与真实值之间差的平方的平均值。用于分类问题,衡量模型预测概率分布与真实概率分布之间的差异。包括二分类交叉熵损失和多类别交
不仅有配套教程讲义还有对应源码数据集,更有零基础入门学习路线,不论你处于什么阶段,这份资料都能帮助你更好地入门到进阶。为了方便大家学习,我整理了一份。需要的兄弟可以按照这个图的方式。
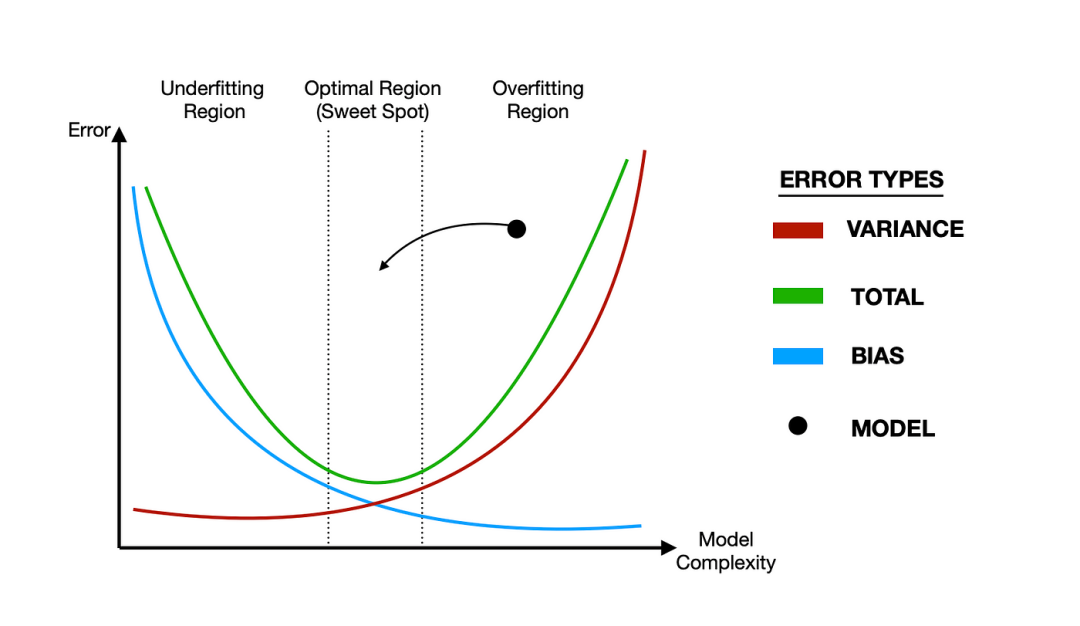
正则化通过约束模型的复杂度来防止过拟合,提高模型的泛化能力,可以根据具体问题和数据集的特点选择合适的正则化技术和参数设置。常用的正则化方法,包括L1正则化(Lasso Regularization)、L2正则化(Ridge Regularization)和Dropout等。其中,L1正则化实现特征选择和模型稀疏化,L2正则化使权重值尽可能小,而Dropout则通过随机丢弃神经元来减少神经元之间的共
本文介绍了如何使用PyTorch进行深度学习模型的搭建和训练。首先,需要根据硬件选择安装CPU或GPU版本的PyTorch。接着,通过torch.utils.data模块准备数据,如使用MNIST数据集。然后,通过继承torch.nn.Module定义模型,并设置损失函数和优化器。训练过程包括喂数据、计算预测值、计算损失和调整参数。训练完成后,使用测试集评估模型准确率,并可以保存和加载模型。文章还