




- @2301_76341691
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
电科金仓开源KESMCPServer,通过MCP协议实现AI工具与KES数据库的深度集成。该方案解决了传统开发中频繁切换工具的问题,支持在TRAE/Cursor等开发工具内直接查询数据库结构、分析SQL执行计划、进行健康检查和索引优化。其五层架构设计包含严格的双模式访问控制(推荐生产环境使用Restricted只读模式),支持三种传输方式,并内置9个标准工具。特色功能包括通过sys_hypo扩展实
电科金仓开源KESMCPServer,通过MCP协议实现AI工具与KES数据库的深度集成。该方案解决了传统开发中频繁切换工具的问题,支持在TRAE/Cursor等开发工具内直接查询数据库结构、分析SQL执行计划、进行健康检查和索引优化。其五层架构设计包含严格的双模式访问控制(推荐生产环境使用Restricted只读模式),支持三种传输方式,并内置9个标准工具。特色功能包括通过sys_hypo扩展实
从本次实际使用和多个案例的结果来看,Claude Code 在接入蓝耘 MaaS 后,已经具备“工程可用级”的生成能力端到端能力明确:在单文件 HTML、前端 Demo、Canvas 游戏、Three.js 场景等任务中,生成结果大多可直接运行,减少了大量“拼代码”的前期工作。适合作为原型与验证工具:非常适合用在需求验证、内部演示、方案评审和教学场景中,而不是一开始就手写全部代码。开发者心智成本低

GLM-5是智谱AI推出的新一代旗舰大语言模型,在编程和Agent任务能力上取得重大突破。本文详细介绍了GLM-5的技术规格、核心能力及其在蓝耘MaaS平台上的部署方法。通过实战演示展示其在编程、文本处理、对话等场景的应用效果,并对比分析了其性能优势。GLM-5在多项基准测试中表现优异,编程能力接近国际顶尖水平,Agent能力位居开源模型首位。文章还提供了云端API调用和本地部署方案,帮助开发者快

OpenClaw拥有操控你电脑的最高权限,当你用cpolar把它暴露在公网上时,务必、务必保管好你的网关令牌和cpolar账号密码。不要分享给任何人,否则你的电脑就相当于对别人敞开了大门,后果不堪设想。

OpenClaw是一款面向企业数字化转型的自动化编排引擎,通过零接触部署和模块化架构实现跨平台集成。文章详细解析了其四阶段内核形成过程:从骨架构建(远程脚本安装)、神经塑造(环境配置)、生命激活(独立进程运行)到感官延伸(插件化扩展)。重点介绍了其双核驱动架构(控制面与数据面分离)和微信生态的原生集成能力,展示了该工具如何通过简洁的命令行实现高效自动化运维。OpenClaw的设计体现了现代软件架构
诚实地说,GLM-5.1在极专业的子领域术语(比如师弟那篇论文里涉及的一个CV新算法名称)上偶尔会翻错。但这不是GLM-5.1独有的问题——我拿同样的场景试过DeepSeek-V3.2和Qwen3-235B(都在蓝耘上),表现差不多。解决办法也很简单:在提示词里加一句”如果遇到不确定的专业术语,请保留原文并用[不确定]标注”。
GLM-5是智谱AI推出的新一代旗舰大语言模型,在编程和Agent任务能力上取得重大突破。本文详细介绍了GLM-5的技术规格、核心能力及其在蓝耘MaaS平台上的部署方法。通过实战演示展示其在编程、文本处理、对话等场景的应用效果,并对比分析了其性能优势。GLM-5在多项基准测试中表现优异,编程能力接近国际顶尖水平,Agent能力位居开源模型首位。文章还提供了云端API调用和本地部署方案,帮助开发者快
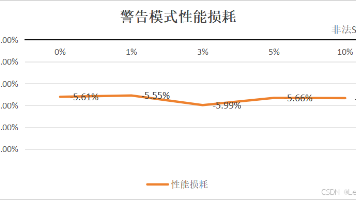
金仓数据库SQL防火墙通过内核层主动防御机制,有效拦截99.99%的SQL注入攻击。该系统提供学习、警告、报错三种智能模式,可自动建立SQL白名单,实现精准防护。实测显示其性能损耗低于6%,且配置简单,两步即可完成设置。该技术已广泛应用于党政、能源等高安全需求领域,从根本上改变了被动防御模式,使数据库安全从"亡羊补牢"转变为"规则先行",为关键数据筑起智能防
World Monitor这个项目的完成度相当高,3D地球的交互很流畅,数据聚合维度也丰富。接入蓝耘API后,点击新闻事件会自动生成摘要和影响分析,把“数据展示”升级成了“情报分析”,这是我觉得最有价值的地方。
