登录社区云,与社区用户共同成长
邀请您加入社区
大语言模型对话能力并非天然具备,而是依赖指令微调与高质量对话数据的协同优化。Vicuna作为Llama生态中最具工程落地价值的开源对话模型,其核心在于将ShareGPT真实用户对话轨迹转化为结构化训练信号,并通过LoRA低秩适配实现高效、稳定、可复现的轻量微调。它不追求参数规模,而聚焦于意图理解、上下文连贯与响应可控性三大实用指标,在AlpacaEval等权威榜单持续领先。尤其适合客服系统、知识库
大语言模型(LLM)的本地化部署正从GPU依赖走向CPU普惠化,核心在于轻量级推理框架与高效量化模型的协同。llama.cpp作为纯C++实现的CPU优先推理引擎,通过AVX2/AVX512指令集优化、内存映射(mmap)与KV Cache缓存亲和设计,显著提升前向传播确定性;配合Vicuna-7b-v1.5等经中文指令微调的开源对话模型及Q4_K_M级别GGUF量化,可在16GB内存笔记本上实现
大语言模型推理不再依赖GPU显卡,CPU也能高效运行——核心在于模型量化与硬件特性协同优化。通过llama.cpp框架,结合Q4_K_M等分组量化技术,可将7B级Vicuna模型压缩至3.2GB以内,在支持AVX2的i5/Ryzen 5等主流CPU上实现14+ tokens/s的流式响应。其原理是利用CPU高命中率L3缓存、双通道内存带宽及mmap按需加载机制,规避显存瓶颈与swap抖动。该方案广
大语言模型推理不再依赖GPU——CPU端部署已成为边缘计算、隐私敏感场景和轻量AI应用的关键路径。其核心原理在于通过张量量化(如INT4)、指令集加速(AVX-512/AMX)与内存映射(mmap)协同优化,突破传统PyTorch CPU后端的算子支持与带宽瓶颈。技术价值体现在零CUDA依赖、极低内存占用(Q4_K_M仅3.9GB)和稳定低延迟(2.8 token/s),适用于本地知识库问答、会议
大语言模型推理不再依赖GPU,CPU本地部署已成为轻量、安全、可控的主流方案。其核心原理是通过量化压缩(如Q4_K_M)、指令集加速(AVX2/AVX-512)与内存映射优化(GGUF格式),在有限硬件资源下实现高吞吐低延迟的推理。技术价值在于兼顾隐私合规、离线可用与工程可复现性,广泛适用于办公文档处理、教育辅导、嵌入式调试及开发者本地AI编程等真实场景。本文聚焦llama.cpp框架与Vicun
对话模型是大语言模型落地应用的核心形态,其技术本质是通过指令微调(SFT)实现人类意图与模型响应的对齐。Vicuna作为开源社区标杆,以Llama-13B为底座,验证了小数据(7万条高质量ShareGPT对话)、单阶段监督微调、QLoRA低秩适配等轻量化路径的有效性。它不依赖强化学习(RLHF)或海量语料,而是聚焦信息密度筛选、上下文感知格式构造与可复现训练配置,在消费级硬件(如双卡3090)上达
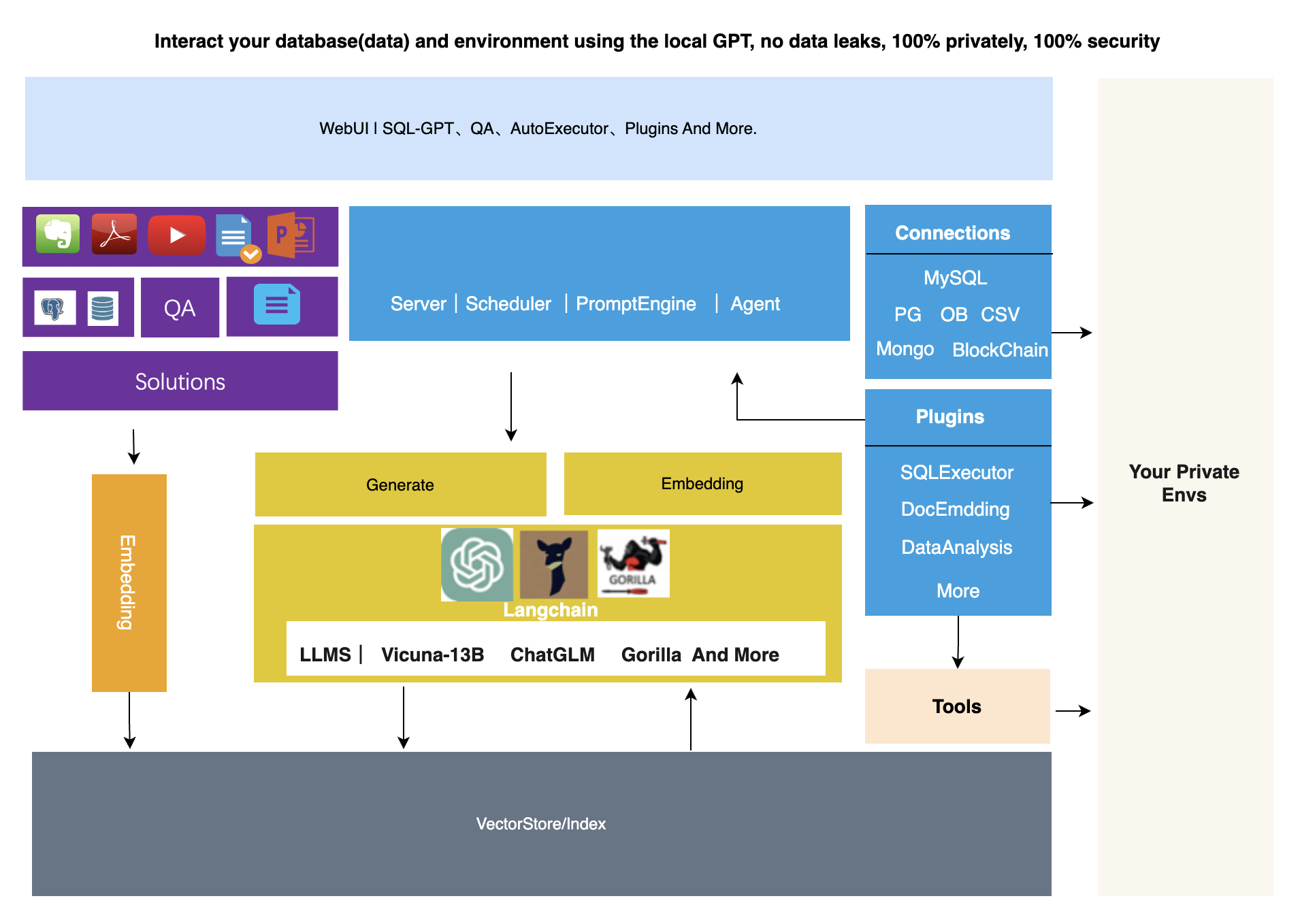
DB-GPT是一个实验性的开源项目,它使用本地化的GPT大型模型与数据和环境进行交互。使用此解决方案,没有数据泄露的风险,数据是100%私密和安全的。DB-GPT使用FastChat创建了一个庞大的模型操作系统,并提供了一个由Vicuna驱动的大型语言模型。此外,还提供了私有领域知识库问答功能、对其他插件的支持、支持Auto-GPT插件。DB-GPT愿景是使围绕数据库和llm构建应用程序变得更容易
本文探讨Vicuna开源模型在银行客服场景的应用,涵盖模型原理、数据预处理、微调优化及系统部署,强调其在提升服务效率与合规性方面的优势。
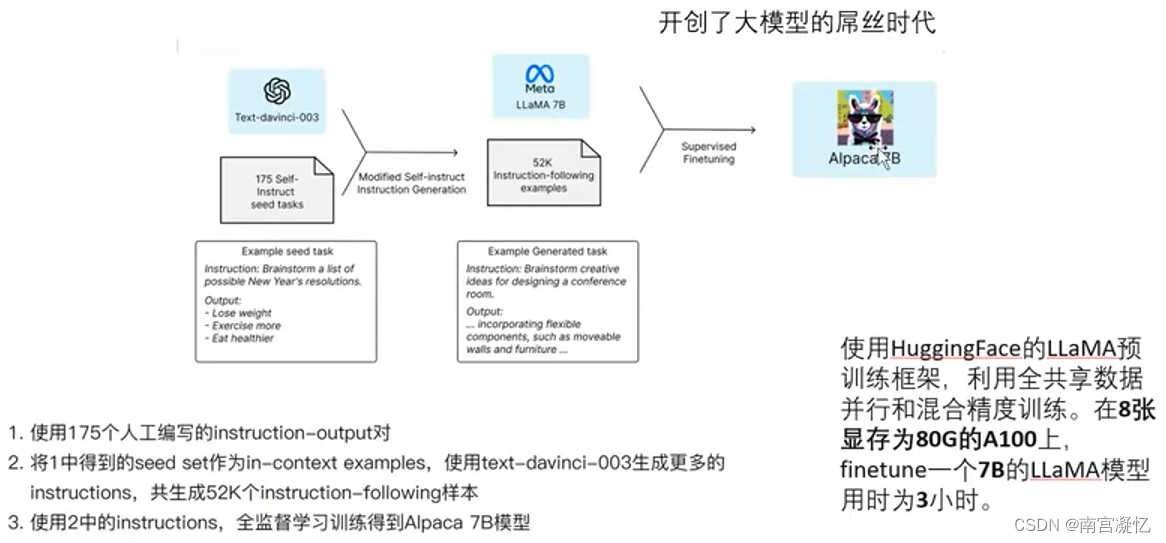
羊驼系列大模型LLaMa、Alpaca、Vicuna
这表明开源模型仍有很大的改进空间。通过在聊天机器人竞技场运行2个月收集的一部分用户数据的分析,团队确定了用户提示的8个主要类别: 写作、角色扮演、提取、推理、数学、编码、知识一(STEM)和知识二(人文社科)。图注:用户与LLaMA-13B和Vicuna-13B之间的多轮对话,开始是MMLU基准中的问题和后续指令,然后将GPT-4与上下文一起呈现,比较谁的答案更好。另外,团队还发布了更新的Vicu
Vicuna
——Vicuna
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 AMD开发者中国社区
AMD开发者中国社区

 智能体开发者社区
智能体开发者社区


 AI硬件创业社区
AI硬件创业社区

 腾讯云开发者社区
腾讯云开发者社区


 AI Agent技术社区
AI Agent技术社区

 2048 AI社区
2048 AI社区

