




- @penriver
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
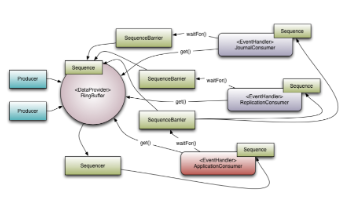
Disruptor一个提供并发环型缓冲区【RingBuffer】数据结构、高性能的Java线程间消息传递库库, 本文针对其核心概念进行介绍
**具身智能**作为人工智能发展的一个重要分支,正在迅速崭露头角,成为科技界和大众关注的热门话题,同时在各个领域中展现出巨大的潜力和吸引力**具身智能是由“本体”和“智能体”耦合而成且能够在复杂环境中执行任务的智能系统**。本文讲解具身智能(Embodied AI)的概念、核心要素、难点及突破性进展

随着社交、电商、金融、零售、物联网等行业的快速发展,现实社会织起了了一张庞大而复杂的关系网,亟需一种支持海量复杂数据关系运算的数据库即图数据库。本系列文章是学习知识图谱以及图数据库相关的知识梳理与总结本文会包含如下内容:如何快速导入10亿+数据本篇文章适合人群:架构师、技术专家、对知识图谱与图数据库感兴趣的高级工程师1. nebula cluster环境nubula版本2.0.0,后端存储使用的是
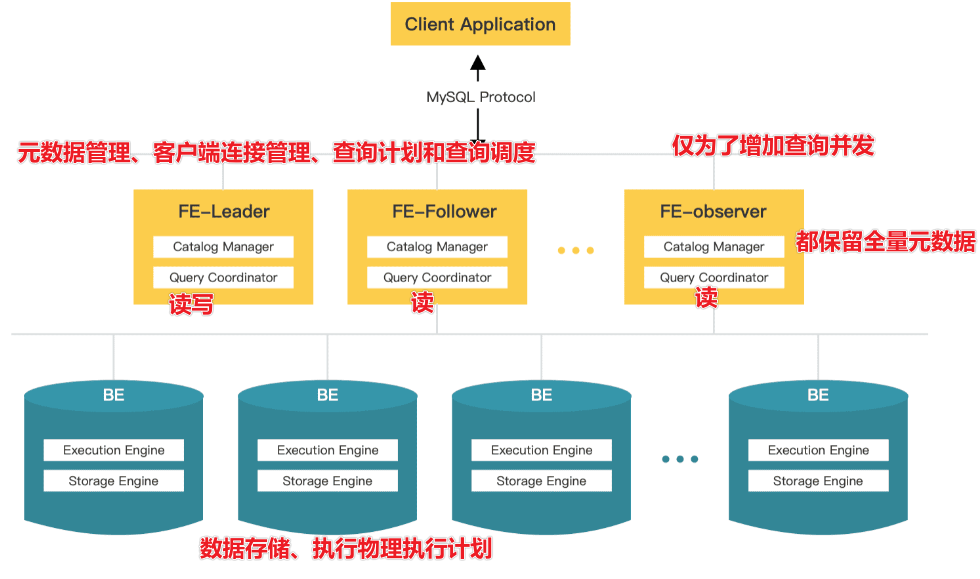
StarRocks 是一款MPP DB, 对标ClickHouse、Vertica、Teradata、Greenplum,在查询性能上远超当代最快的开源数据库 clickhouse,目前已经被一众互联网企业在生产环境中采用。本文是使用starrocks的入门培训教程
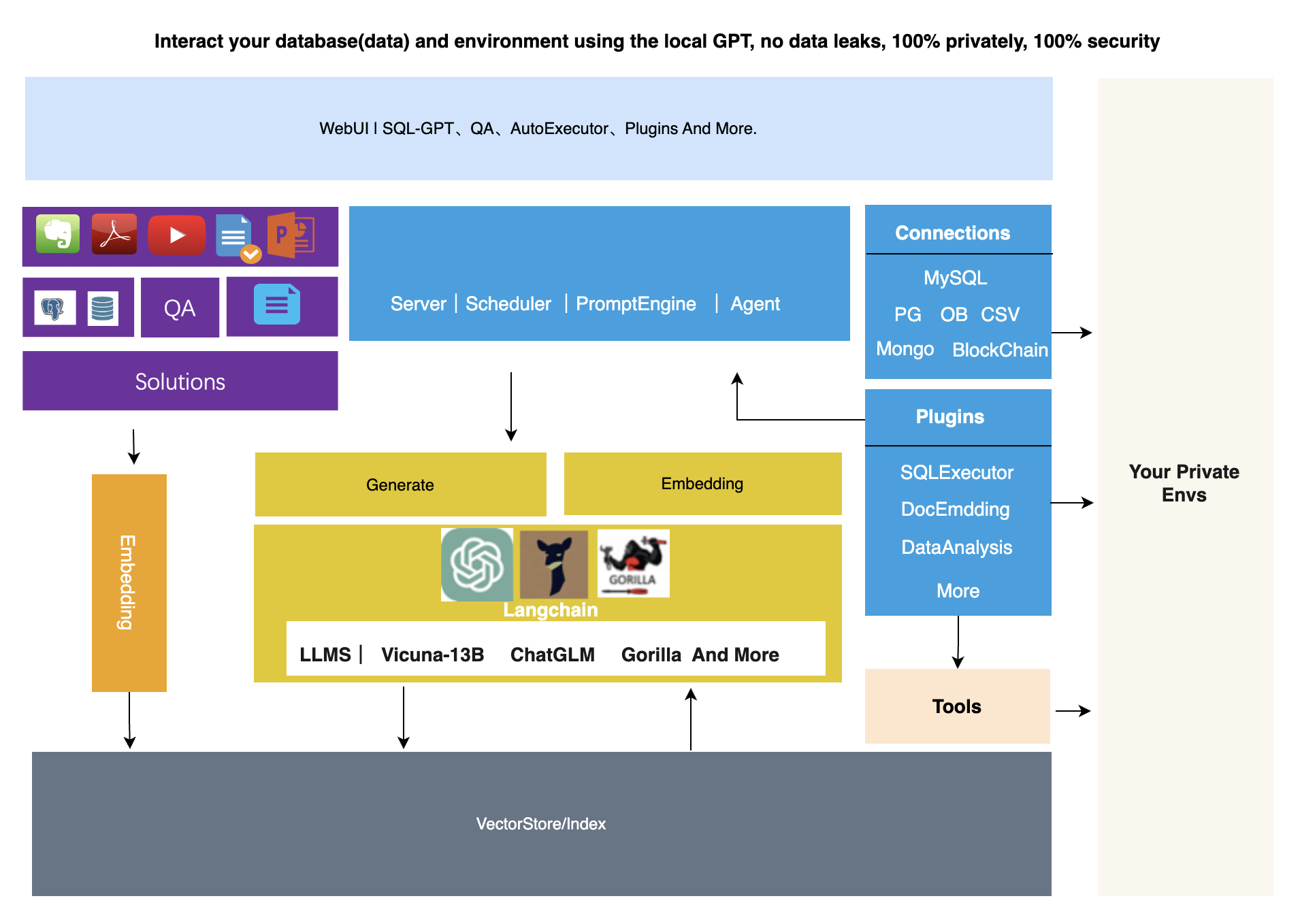
DB-GPT是一个实验性的开源项目,它使用本地化的GPT大型模型与数据和环境进行交互。使用此解决方案,没有数据泄露的风险,数据是100%私密和安全的。DB-GPT使用FastChat创建了一个庞大的模型操作系统,并提供了一个由Vicuna驱动的大型语言模型。此外,还提供了私有领域知识库问答功能、对其他插件的支持、支持Auto-GPT插件。DB-GPT愿景是使围绕数据库和llm构建应用程序变得更容易
TypeScript 正在经历一场由 AI 驱动的“爆发式”增长,甚至在活跃度上已经超越了 Python,成为 GitHub 上最活跃的编程语言。 作为JAVA 开发者,有必要了解并熟悉一下typescriptTypeScript 的设计者有意借鉴了 Java、C# 等语言的一些语法元素,降低了学习曲线,但底层机制与JAVA、C#有着本质的不同在 AI Agent 的“应用层”和“工具层”开发中,

一种用于`指导`人工智能(如聊天机器人或图像生成工具)`生成特定内容`的文字。**提示词**的设计旨在以一种`高效`、`精确`的方式向模型传达用户的`意图`或所需的`任务类型`,从而使模型想你所想。有关如何写好提示词,请学习[面向开发者的大模型手册 - LLM Cookbook](https://github.com/datawhalechina/llm-cookbook),设计高效 Prompt

docker配置文件使用经验

DB-GPT是一个实验性的开源项目,它使用本地化的GPT大型模型与数据和环境进行交互。使用此解决方案,没有数据泄露的风险,数据是100%私密和安全的。DB-GPT使用FastChat创建了一个庞大的模型操作系统,并提供了一个由Vicuna驱动的大型语言模型。此外,还提供了私有领域知识库问答功能、对其他插件的支持、支持Auto-GPT插件。DB-GPT愿景是使围绕数据库和llm构建应用程序变得更容易
StarRocks 是一款MPP DB, 对标ClickHouse、Vertica、Teradata、Greenplum,在查询性能上远超当代最快的开源数据库 clickhouse,目前已经被一众互联网企业在生产环境中采用。本文是使用starrocks的入门培训教程