




- @weixin_43409127
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对于标准深度学习模型,我们可以使用框架的预定义好的层。这使我们只需关注使用哪些层来构造模型,而不必关注层的实现细节。我们首先定义一个模型变量net,它是一个Sequential类的实例。Sequential类将多个层串联在一起。当给定输入数据时,Sequential实例将数据传入到第一层, 然后将第一层的输出作为第二层的输入,以此类推。在下面的例子中,我们的模型只包含一个层,因此实际上不需要Seq

KM缩放法则是由OpenAI的研究员Jared Kaplan和Sam McCandlish提出的,用于描述大型语言模型(LLMs)如何随着模型大小、数据量和计算资源的增加而提高性能。通过遵循这些法则,可以在有限的计算资源下实现更高的性能,同时也为未来大型模型的发展提供了理论基础。KM缩放法则的关键观点是,通过增加模型的大小和投入更多的计算资源,可以预测地改善模型的性能。此外,这些研究有助于推动人工
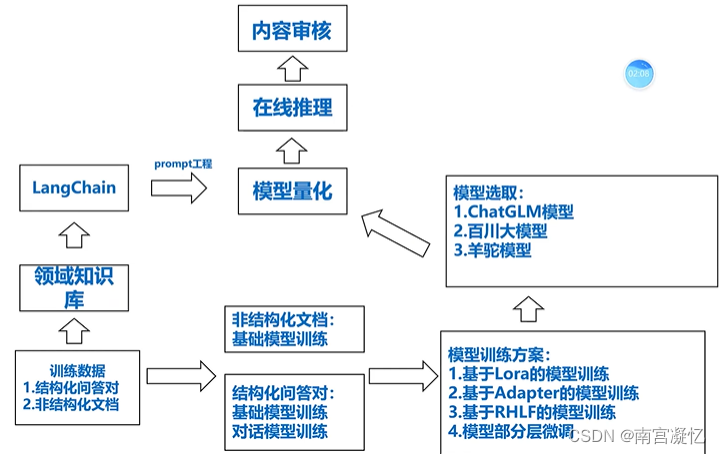
大模型微调经验
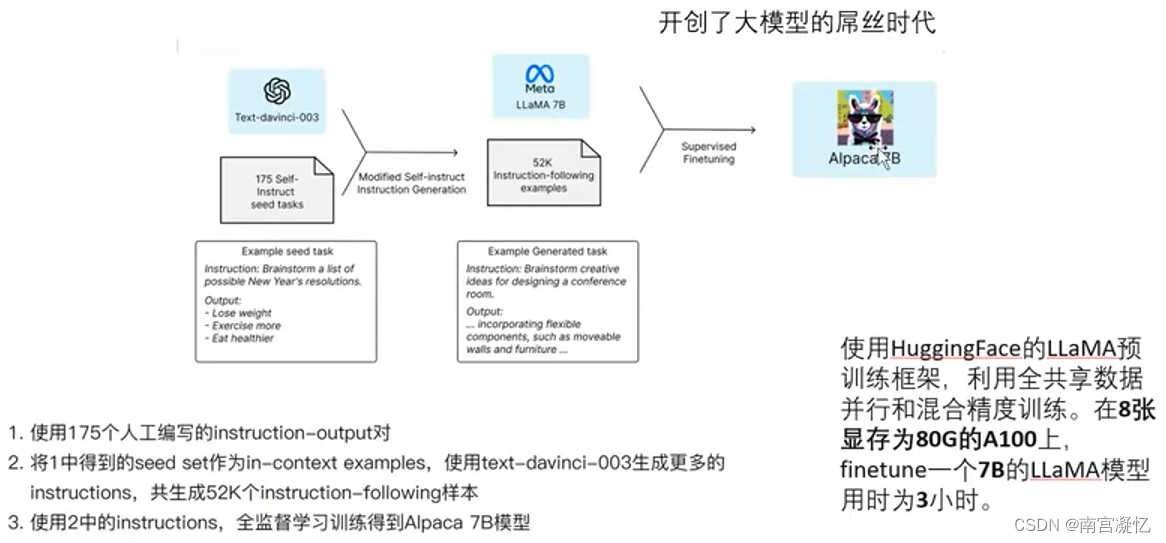
羊驼系列大模型LLaMa、Alpaca、Vicuna
如何用resnet50提取图片特征【咨询大厂大佬版】
KM缩放法则是由OpenAI的研究员Jared Kaplan和Sam McCandlish提出的,用于描述大型语言模型(LLMs)如何随着模型大小、数据量和计算资源的增加而提高性能。通过遵循这些法则,可以在有限的计算资源下实现更高的性能,同时也为未来大型模型的发展提供了理论基础。KM缩放法则的关键观点是,通过增加模型的大小和投入更多的计算资源,可以预测地改善模型的性能。此外,这些研究有助于推动人工
羊驼系列大模型LLaMa、Alpaca、Vicuna
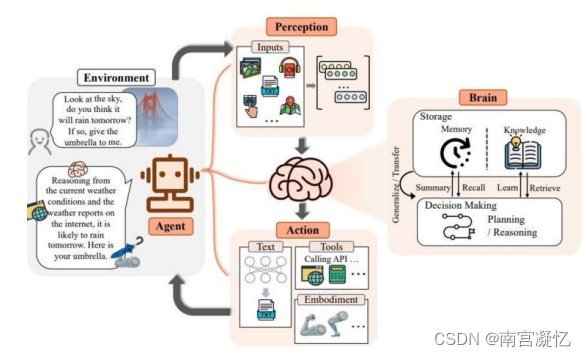
大模型Agent一、背景知识1.会产生幻觉。2.结果并不总是真实的。3.对时事的了解有限或一无所知。4.很难应对复杂的计算。•Google搜索:获取最新信息•Python REPL:执行代码•Wolfram:进行复杂的计算•外部API:获取特定信息大模型 + 插件 + 执行流程 = Agent二、Agent框架LLM-based Agent 框架包含三个组成部分:控制端(Brain)、感知端(Pe
大模型微调经验
KM缩放法则是由OpenAI的研究员Jared Kaplan和Sam McCandlish提出的,用于描述大型语言模型(LLMs)如何随着模型大小、数据量和计算资源的增加而提高性能。通过遵循这些法则,可以在有限的计算资源下实现更高的性能,同时也为未来大型模型的发展提供了理论基础。KM缩放法则的关键观点是,通过增加模型的大小和投入更多的计算资源,可以预测地改善模型的性能。此外,这些研究有助于推动人工