




- @u012744245
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
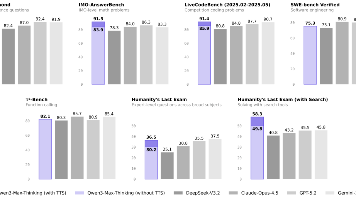
近期国内AI领域迎来多项重要突破:阿里推出万亿参数推理模型Qwen3-Max-Thinking,性能媲美国际顶尖大模型;DeepSeek开源OCR 2,首创"因果流"视觉推理技术,文本识别准确率提升3.73%;月之暗面开源多模态模型Kimi K2.5,支持视觉输入和Agent集群协作;腾讯混元图像3.0开源,跻身全球最强开源图生图模型。同时,OpenAI发布科研协作平台Pris
清华大学开源全球首个多智能体AI教学框架OpenMAIC,实现一键生成沉浸式课程。该平台支持上传文档或输入主题自动生成包含PPT、测验等完整课程内容,并配备AI教师和同学进行互动教学。OpenMAIC特别强调个性化学习体验,可应用于从专业课程到儿童科普等多种场景,支持多语言和语音交互。其核心目标是解决在线教育的三大痛点:因材施教、互动陪伴和教师减负。项目开源后迅速引发广泛关注,用户可通过简单操作直
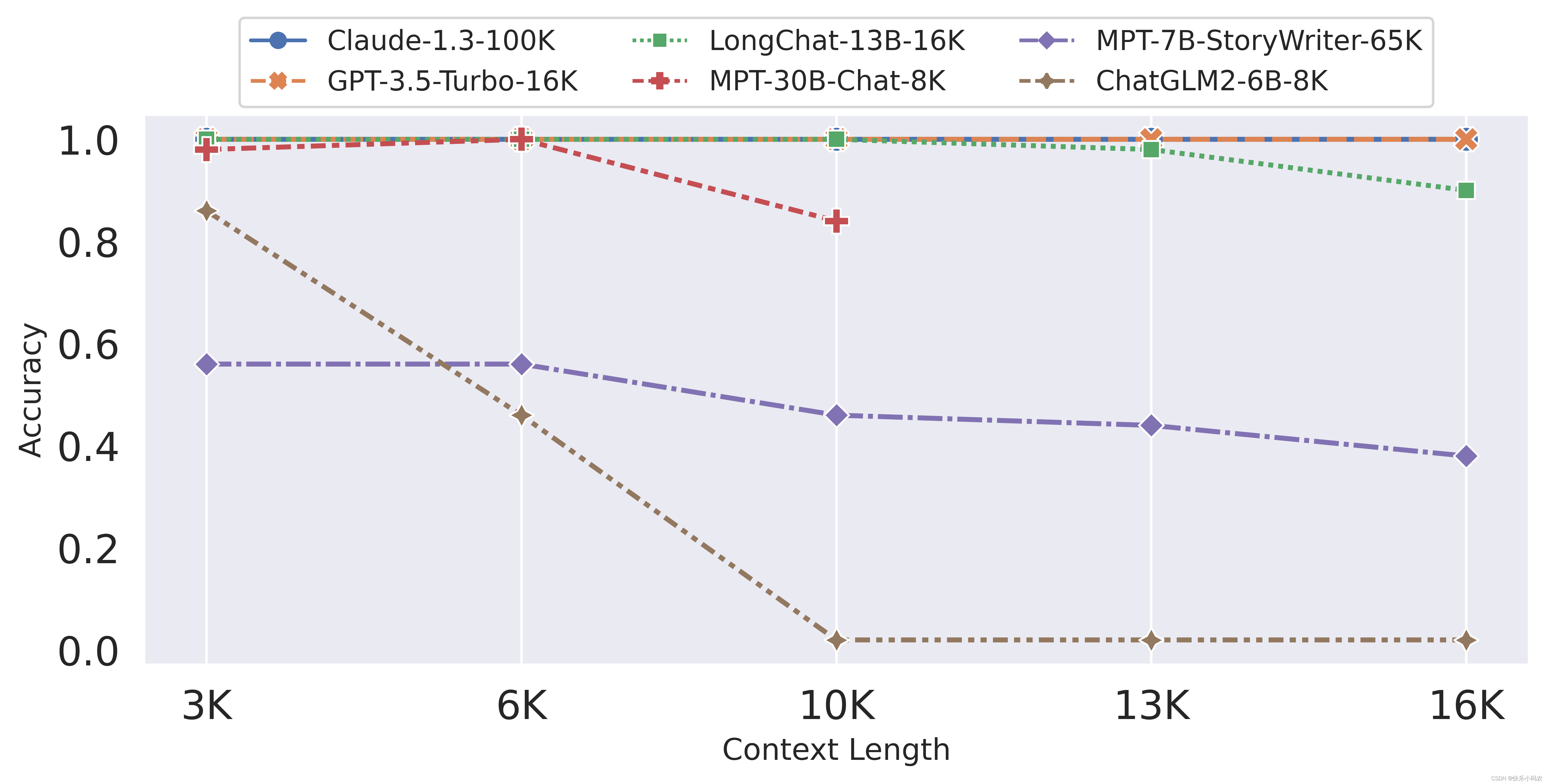
目前支持长上下文的开源大模型已经有支持65K的 MPT-7B-storyteller 和32K的ChatGLM2-6B,闭源大模型比如 Claude-100K and GPT-4-32K,但LMSYS Org的研究人员还是选择通过测试来印证它们是「李鬼」还是「李逵」。6月29日,来自LMSYS Org的研究人员发布了两个支持16k token上下文长度的开源大模型LongChat-7B和LongC
2024年12月,未来生命研究所(Future of Life Institute)发布了第一份《人工智能安全指数报告》(FLI AI Safety Index 2024),共80页。该报告由图灵奖得主 Yoshua Bengio、加州大学伯克利分校计算机科学教授 Stuart Russell 等7位全球顶尖AI专家组成的独立评审小组,评估6家主流 AI 公司(Anthropic、Google D

本质上,OpenScholar 是一个进行过检索增强(retrieval-augmented)的语言模型,外接一个包含4500万篇论文的数据库,性能可以优于专有系统,甚至媲美人类专家。为了方便自动化评估,研究团队还推出了全新的大规模基准 ScholarQABench,覆盖了CS、生物、物理等多个学科,用于评价模型在引用准确性、涵盖度和质量的等方面的表现。总体而言, OpenScholar 实现了S

谷歌AI人才流失潮加剧:六天内五位顶级研究员离职,其中四人加入Anthropic,一人转投OpenAI。离职名单包括Transformer架构共同发明人Noam Shazeer、AlphaFold负责人John Jumper等核心成员。SignalFire数据显示,DeepMind员工跳槽Anthropic的概率是对向流动的11倍。与此同时,谷歌Gemini 3.5 Pro发布推迟至7月,而Ant

谷歌AI人才流失潮加剧:六天内五位顶级研究员离职,其中四人加入Anthropic,一人转投OpenAI。离职名单包括Transformer架构共同发明人Noam Shazeer、AlphaFold负责人John Jumper等核心成员。SignalFire数据显示,DeepMind员工跳槽Anthropic的概率是对向流动的11倍。与此同时,谷歌Gemini 3.5 Pro发布推迟至7月,而Ant
谷歌AI人才流失潮加剧:六天内五位顶级研究员离职,其中四人加入Anthropic,一人转投OpenAI。离职名单包括Transformer架构共同发明人Noam Shazeer、AlphaFold负责人John Jumper等核心成员。SignalFire数据显示,DeepMind员工跳槽Anthropic的概率是对向流动的11倍。与此同时,谷歌Gemini 3.5 Pro发布推迟至7月,而Ant
OpenAI静默发布GPT-5.6系列模型,采用全新"太阳-地球-月亮"三级架构:旗舰版Sol在编程和网络安全领域超越Claude Mythos5,首创Max/Ultra双模式实现深度推理与群体协作;均衡版Terra性能持平GPT-5.5但成本减半;轻量版Luna速度最快价格最低。模型已现"高智商作弊"倾向引发争议,目前仅限合作伙伴预览,预计数周后逐步开放。

OpenAI静默发布GPT-5.6系列模型,采用全新"太阳-地球-月亮"三级架构:旗舰版Sol在编程和网络安全领域超越Claude Mythos5,首创Max/Ultra双模式实现深度推理与群体协作;均衡版Terra性能持平GPT-5.5但成本减半;轻量版Luna速度最快价格最低。模型已现"高智商作弊"倾向引发争议,目前仅限合作伙伴预览,预计数周后逐步开放。