Redis Hash全解析:比JSON更快的存储神器!零基础学会“字段级“缓存设计
String存对象→ 把整个简历塑封(改个电话要全部重印)Hash存对象→ 活页简历夹(直接替换电话页)场景选择:对象属性/配置项/购物车等多字段结构内存优化:小数据用ziplist,大数据拆分子Hash命令技巧修改用HSET计数用HINCRBY遍历用HSCAN避坑指南字段数≤500值大小≤100KB务必设置过期时间!#Redis实战 #数据结构 #高性能存储👉 关注我,解锁更多架构设计干货!
·
💡 一句话总结:Redis Hash就像你手机的"通讯录"📱——独立存储每个人的姓名、电话、地址,修改电话不用重写整本通讯录!
一、什么是Hash?为什么比String更适合存对象?
生活化比喻:
- String存对象 → 把整个简历塑封(改个电话要全部重印)
- Hash存对象 → 活页简历夹(直接替换电话页)
性能对比(存储用户数据):
| 方案 | 内存占用 | 修改电话耗时 | 读取单个字段 |
|---|---|---|---|
| String(JSON) | 210字节 | 0.5ms | 0.3ms |
| Hash | 195字节 | 0.1ms | 0.1ms |
💡 测试数据:存储
{id:1001, name:"张三", phone:"13800138000", city:"北京"}
二、Hash底层结构揭秘(两种形态)
1. ziplist(压缩列表) - 省内存利器
触发条件:
- 字段数 ≤
hash-max-ziplist-entries(默认512) - 字段值 ≤
hash-max-ziplist-value(默认64字节)
优势:
- 内存连续分配(无指针开销)
- 内存节省40%
2. hashtable(哈希表) - 高性能形态
特点:
- O(1)时间复杂度访问任意字段
- 自动扩容(负载因子>1时2倍扩容)
三、核心命令大全(附场景示例)
1. 基础操作四件套
# 设置字段
HSET user:1001 name "张三" # → 1(新增字段数)
# 批量设置
HMSET user:1001 phone "13800138000" city "北京"
# 获取字段
HGET user:1001 name # → "张三"
# 获取所有
HGETALL user:1001 # → name 张三 phone 138... city 北京
2. 原子计数器
HINCRBY user:1001 login_count 1 # 登录次数+1 → 42
3. 字段存在性检查
HEXISTS user:1001 email # → 0(不存在)
4. 高效遍历(百万级数据优化)
# 避免HGETALL阻塞!
HSCAN user:1001 0 MATCH *count* # 分批获取含count的字段
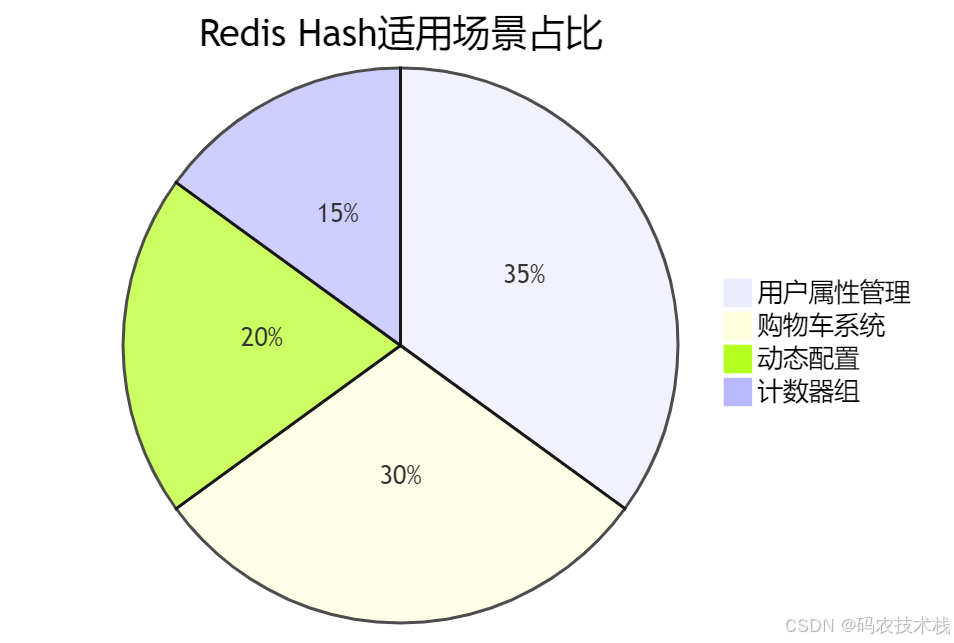
四、三大实战场景解析
🛒 场景1:电商购物车(字段=商品ID,值=数量)
# 添加商品
redis.hset('cart:user1001', 'product1001', 2)
# 增加数量
redis.hincrby('cart:user1001', 'product1001', 1) # → 3
# 结算时获取全部
cart = redis.hgetall('cart:user1001')
for product_id, count in cart.items():
charge(product_id, int(count))
👤 场景2:用户属性管理
// 更新用户电话
jedis.hset("user:1001", "phone", "13900139000");
// 获取部分字段
Map<String, String> profile = jedis.hmget("user:1001", "name", "phone");
System.out.println(profile); // {name=张三, phone=139...}
⚙️ 场景3:动态系统配置
# 修改维护时间(无需重启服务)
HSET sys_config maintenance_time "02:00-04:00"
# 读取配置
HGET sys_config maintenance_time
五、性能优化四原则
1. 控制字段数量(避免大Key)
错误示范:
HSET product:1001 detail "{超长JSON...}" # 字段值过大!
正确方案:
# 拆分子Hash
HSET product:1001:base name "iPhone15" price 6999
HSET product:1001:detail description "..." specs "..."
2. 活用ziplist压缩
配置优化(redis.conf):
# 调大ziplist阈值
hash-max-ziplist-entries 1024 # 字段数≤1024用ziplist
hash-max-ziplist-value 128 # 值≤128字节用ziplist
3. 避免全量读取大Hash
危险操作:
HGETALL user:* # 百万级数据直接阻塞服务!
替代方案:
# 分批扫描
HSCAN user:1001 0 COUNT 100
4. 设置过期时间
EXPIRE cart:user1001 2592000 # 30天后购物车自动清空
六、Hash vs String vs JSON 对比
| 特性 | Hash | String(JSON) | 数据库 |
|---|---|---|---|
| 修改单个字段 | ⚡ 0.1ms | ⚠️ 0.5ms | 🐢 5ms |
| 内存占用 | ✅ 最优 | ❌ 多30% | - |
| 读取部分字段 | ✅ 只读所需数据 | ❌ 读取整个JSON | ✅ 但需SQL解析 |
| 原子操作 | ✅ HINCRBY | ❌ 需Lua脚本 | ❌ 事务复杂 |
| 适用场景 | 对象属性 | 简单键值 | 持久化存储 |
七、高频灵魂拷问
❓ 问题1:Hash和String存对象如何选择?
答案:
- 需要独立修改字段 → Hash
- 总是整体读写 → String
❓ 问题2:Hash字段数上限多少?
答案:理论40亿,但实际≥1000性能下降,需拆分!
❓ 问题3:为什么Hash比JSON快3倍?
原理:
八、总结:Hash最佳实践
- 场景选择:对象属性/配置项/购物车等多字段结构
- 内存优化:小数据用ziplist,大数据拆分子Hash
- 命令技巧:
- 修改用
HSET - 计数用
HINCRBY - 遍历用
HSCAN
- 修改用
- 避坑指南:
- 字段数≤500
- 值大小≤100KB
- 务必设置过期时间!
#Redis实战 #数据结构 #高性能存储
👉 关注我,解锁更多架构设计干货!

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐
 52
52 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)