




- @zhengzhaoyang122
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文探讨了AI Agent的核心概念与应用场景。AI Agent是一种能够自主感知环境、收集数据并执行任务的软件程序,其核心在于大语言模型(LLM)提供的推理能力。文章重点介绍了ReAct框架,该框架通过结合LLM推理与行动执行能力,提升复杂任务的处理效果。并以机票预订为例,展示了Agent如何通过"思考-行动"循环完成航班查询、价格计算等业务流程。最后提供了基于LangGraph的技术实现方案,
不同类型的模型具有不同的特点,所以结合各种模型的预测结果也能有效降低过拟合的风险,提升预测精度。大部分ML模型的学习过程中都运用了类似梯度下降法的迭代优化算法,过多的迭代次数会出现过度训练(Overtraining),让模型最终的参数过度适应训练集,加重过拟合。以决策树模型为例,令树的深度越大、叶子节点数越少,模型就越复杂,对训练集的数据分类更精细,会更容易导致模型过拟合。其次在特征工程阶段,“暴

OPENAI_API_KEY:OpenClaw 中用于调用 OpenAI 的 DALL-E 等图像生成模型的技能,配置 API Key 后,AI 就可以根据你的描述生成图片。ELEVENLABS_API_KEY:是 OpenClaw 中用于语音合成的技能,配置 ElevenLabs 的 API Key 后,AI 就可以生成高质量的语音输出。Web 搜索:选择一个你有 API Key 的提供商,按提
本文探讨了AI Agent的核心概念与应用场景。AI Agent是一种能够自主感知环境、收集数据并执行任务的软件程序,其核心在于大语言模型(LLM)提供的推理能力。文章重点介绍了ReAct框架,该框架通过结合LLM推理与行动执行能力,提升复杂任务的处理效果。并以机票预订为例,展示了Agent如何通过"思考-行动"循环完成航班查询、价格计算等业务流程。最后提供了基于LangGraph的技术实现方案,
确保使用的是最新版本的 Git。旧版本的 Windows 版 Git 可能与 curl 存在兼容性问题。如果您使用的是旧版本,请考虑通过从官方网站下载最新安装程序来手动更新 Git。如果上述解决方案不起作用,请从系统中卸载 Windows 版 Git,重新启动,然后下载并安装最新版本。命令,提示运行命令时出现以下错误,即使尝试以管理员身份运行命令提示符也出现相同的错误输出。

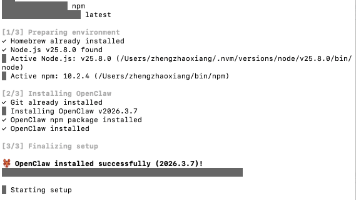
安装新项目时,出现如下升级错误。

根据提示输入密码,成功后会展示你本机的ssh密钥地址;时,提示需要输入密码。命令则无需输入密码了。
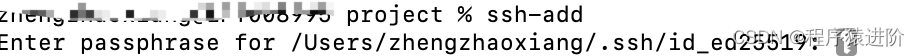
安装依赖时,终端却提示。

软件自身使用的虚拟机是分开的(也就是独立的进程)中增加编译器使用的虚拟机内存[
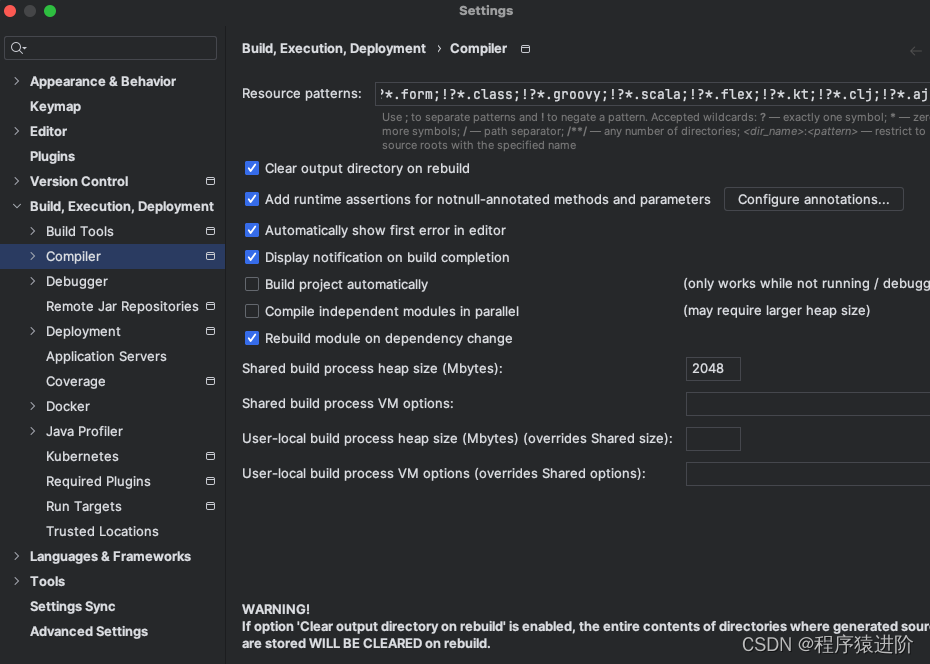
安装依赖时,终端却提示。