




- @yin2567588841
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Batch Normalization(批归一化,BN)是一种加速深度神经网络训练的技术,它通过对每个 mini-batch 计算均值和方差来归一化输入特征,从而稳定训练过程,减少梯度消失/梯度爆炸问题。

在Transformer模型中,梯度消失和梯度爆炸是深度学习中常见的问题,尤其是在处理长序列数据时。

方法适用场景复杂度适用于深度学习数学运算数值型特征低❌多项式特征数值型特征中❌One-Hot 交叉类别型特征高❌哈希交叉大规模类别型低❌Embedding 交叉类别型特征高✅树模型交叉类别 & 数值中✅自动化交叉所有特征高✅。
DeepFM 是一种结合 深度学习 (Deep Learning) 和 因子分解机 (Factorization Machine, FM) 的推荐系统模型。它能够同时学习 低阶特征交互(FM 部分) 和 高阶特征交互(DNN 部分)。在 召回阶段,UserCF(User-Based Collaborative Filtering,基于用户的协同过滤)需要计算用户相似度,以便推荐相似用户喜欢的物品。
最近实习步入正轨,也终于闲下来了,就想着总结一下上半年参与的比赛。今年上半年参加了不少的比赛也拿了些奖金,也靠着比赛经历获得了第一份实习,还算过的比较充实的,后续会陆续更新其他的比赛的代码。主要是总结总结,感觉每次比赛中会尝试很多方法但是比赛完又不总结,浪费太多时间了。

今天为了更新一下显卡驱动,下载使用一下了鲁大师,然后卸载。悲催的发现打开google浏览器却会弹出360的导航页。解决办法:打开Google浏览器设置,找到启动时,点击删除【打开特定网页】
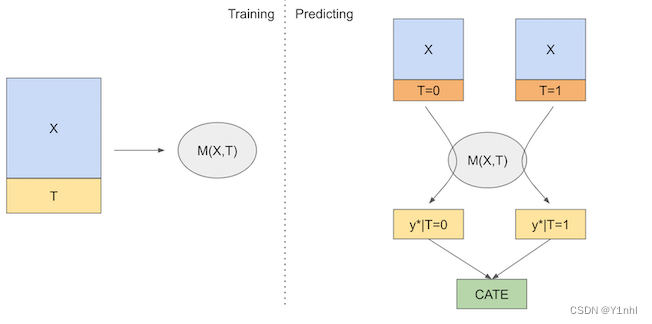
元学习器是利用一些现成的机器学习方法来进行因果推断的方法。也是相对来说最简单的进行因果推断的模型,在econml和causalml都有实现,调用也相对比较方便。
项目NCELoss本质分类任务(正 vs 负)Softmax 近似是否校正偏差❌ 否(拟合二分类目标)✅ 是(log 采样概率校正)推理一致性❌ 不一致✅ 一致(训练/推理)采样分布要求灵活需明确估计qyq(y)qyNCELoss 多用于 word2vec、representation learning 等 embedding 学习场景Sampled Softmax 多用于大规模分类任务、推荐系统
Triplet Loss 用于强化 anchor 和 positive 的距离比 anchor 和 negative 的距离更近,通常用于 embedding 学习。BPR Loss 是推荐召回中非常经典的pairwise ranking loss,目的是让正样本得分比负样本得分高。model.eval()# 设置为推理模式,使用moving统计量。model.train()# 设置为训练模式,使
