




- @weixin_64338372
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
SVM的英文全称是Support Vector Machines,我们叫它支持向量机。支持向量机是我们用于分类的一种算法。让我们以一个小故事的形式,开启我们的SVM之旅吧。

该文会讲解一些大家比较熟悉却又经常混淆的统计图形,掌握这些统计图形可以对数据可视化有一个深入理解,并正确使用。

《动手学深度学习》PyTorch版本和TendorFlow版本(内有所有代码和PDF版下载地址)

动手学深度学习(李沐)的pytorch版本(包含代码和PDF版本),《动手学深度学习》PyTorch版本TendorFlow版本(内有所有代码和PDF版下载地址)

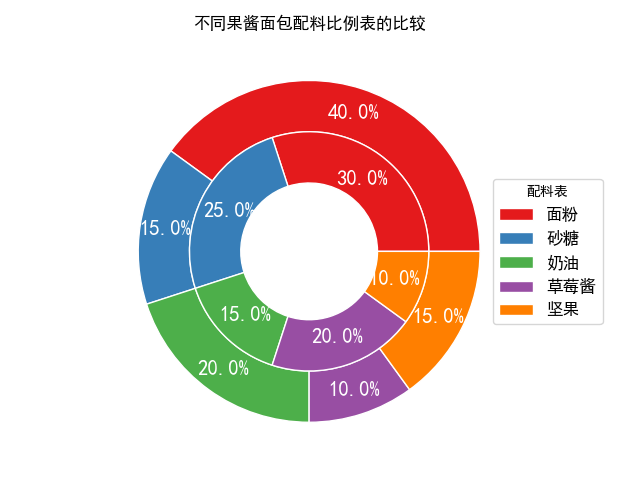
Python数据可视化(三)绘制统计图形大全
动手学深度学习(李沐)的pytorch版本(包含代码和PDF版本),《动手学深度学习》PyTorch版本TendorFlow版本(内有所有代码和PDF版下载地址)
数据清洗是对一些没有用的数据进行处理的过程。很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。在这个教程中,我们将利用 Pandas包来进行数据清洗。

PyQt5安装详细教程,安装步骤很详细
PyQt5 是Digia的⼀套Qt5应⽤框架与python的结合,同时⽀持2.x和3.x。本教程使⽤的是3.x。Qt库 由Riverbank Computing开发,是最强⼤的GUI库之⼀ ,官⽅⽹站www.riverbankcomputing.co.uk/news。

该文将介绍感知机A(perceptron)这一算法。感知机是由美国学者Frank Rosenblatt在1957年提出来的。为何我们现在还要学习这一很久以前就有的 算 法 呢 ? 因 为 感 知 机 也 是 作 为 神 经 网 络(深 度 学 习)的起源的算法 。 因此 ,学习感知机的构造也就是学习通向神经网络和深度学习的一种重要思想。该文我们将简单介绍一下感知机,并用感知机解决一些简单的问题。希
