




- @weixin_53344209
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们可以用普通的机器学习来完成很多任务,但是对于一些人工智能应用它是无法完成的(比如图像识别,语音识别,自然语言处理等)。原因如下:1、维度灾难,我们知道,当输入向量增加时,他们的不同配置数量是指数增长的。比如一维的10个单位,就是10,二维的,就是100,三维的就是1000.在高维空间,计算机付出的计算代价是巨大的。2、统计挑战,正如我们所说,我们的不同配置数量指数增加,同时,我们就需要更多的训
如果完全是一个计算密集的任务,IO消耗可忽略,多进程充分利用CPU核数的计算力更重要,多线程的重要目的就是在IO阻塞时挂起线程让CPU执行别的任务,充分利用CPU,不让他闲置。redis因为是基于内存的,CPU不是瓶颈(也就是说逻辑处理很快,相对就是简单),瓶颈可能是网络带宽等,一个CPU完全有足够的算力去实现所有客户端连接的请求处理,单个的请求处理过程很快,不需要让客户端等待很久,反而是创建切换
文件系统的意义之前说的都是在进程在物理内存保存的数据,内存就像一个纸箱子,。如果我们想要进程结束之后,数据依然能够保存下来,就不能只保存在内存里,而是应该保存在外部存储中。我们最常用的外部存储就是硬盘,数据是以文件的形式保存在硬盘上的。为了管理这些文件,我们在规划文件系统的时候,需要考虑如下几点。文件系统的几个要点:1、严格的组织形式。以单位进行存储,比如图书馆的书架分成很多小格子;2、要有索引,
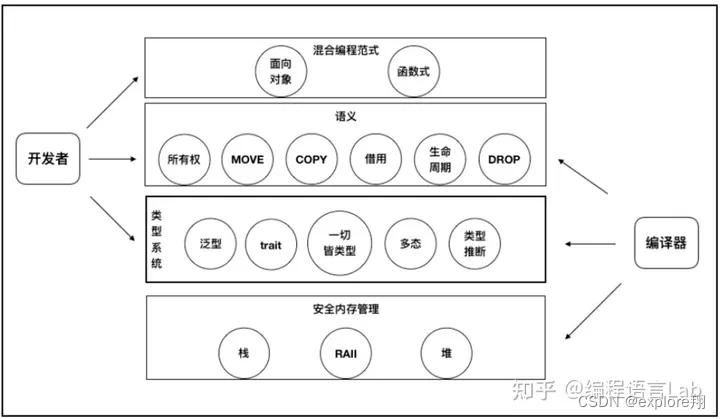
1、第一层,首先从语言本身来说,难度大,特性多是客观事实,但是这也表示rust是博采众长的,吸收了C,C++等其他语言的精华,当然你可能会说没有必要这么做,每种语言利用自己的特性做自己擅长的事情就可以了。现在的语言是无法兼顾两者的,比如C++高性能,但是内存安全问题是很难避免的,全靠经验,而且很多stl库和其他库涉及的内存操作我们并不知晓,具体的内存安全问题可以看前几篇介绍。接下来剩下一些非必须的
理解了数据模型,你就会明白,为什么在有些场景下,原先使用关系型数据库保存的数据,也可以用键值数据库保存。对于 Redis 而言,很有意思的一点是,它的 value 支持多种类型,当我们通过索引找到一个 key 所对应的 value 后,仍然需要从 value 的复杂结构(例如集合和列表)中进一步找到我们实际需要的数据,这个操作的效率本身就依赖于它们的实现结构。通过网络框架提供键值存储服务,一方面扩
所以针对于此,所有的数据库供应商和工具开发商都认为,如果Java能够为SQL访问提供一套“纯”JavaAPI,同时提供一个驱动器管理器来允许第三方驱动程序可以连接到特定的数据库,如此一来数据库供应商可以提供自己的驱动器程序来插入注册到驱动器管理器中;4、接下来就是标准流程:注册驱动-获取数据库连接对象-定义sql语句-获取执行SQL语句的对象 Statement-执行SQL,接收返回的结果,处理返
找到的是原来堆顶所在的vm_area_struct的下一个vm_area_struct,看当前的堆顶和下一个vm_area_struct之间还能不能分配一个完整的页(其实也就是堆和内存映射区之间还有多少剩余空间)如果不能,没办法只好直接退出返回,内存空间都被占满了。另外,内核也有内核栈的空间,前面说了,当系统调用进入内核态就需要内核栈,内核栈的特色就是thread_info是为了存储体系结构相关的
如今,inux 服务器也随之变得越来越强大了。无论是计算、网络、存储,都越来越牛。但是也出现一些问题。1、资源大小申请不灵活。比如想尝试新业务,只需要单独的4核8G的服务器资源,但是不可能采购这么小规格的机器;以及,每次申请这个资源都需要重新采购,周期长;2、资源复用不灵活。别人的操作会导致冲突。必须要有自己单独的资源。为了解决这些问题,可以在物理机上创建虚拟机。。每次创建都是新的操作系统,很好的
