- @weixin_53197693
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Cursor 是由美国初创公司 Anysphere 开发的 AI 原生代码编辑器,其发展历程是从 MIT 学生项目到全球增长最快的 AI 编程工具,最终在 2026 年与 SpaceX 达成重大战略合作的演变过程。创立与早期探索(2022 年 -2023 年初)团队组建:2022 年,由麻省理工学院(MIT)校友 Michael Truell、Sualeh Asif、Arvid Lunnemark
Cursor 是由美国初创公司 Anysphere 开发的 AI 原生代码编辑器,其发展历程是从 MIT 学生项目到全球增长最快的 AI 编程工具,最终在 2026 年与 SpaceX 达成重大战略合作的演变过程。创立与早期探索(2022 年 -2023 年初)团队组建:2022 年,由麻省理工学院(MIT)校友 Michael Truell、Sualeh Asif、Arvid Lunnemark
Cursor 是由美国初创公司 Anysphere 开发的 AI 原生代码编辑器,其发展历程是从 MIT 学生项目到全球增长最快的 AI 编程工具,最终在 2026 年与 SpaceX 达成重大战略合作的演变过程。创立与早期探索(2022 年 -2023 年初)团队组建:2022 年,由麻省理工学院(MIT)校友 Michael Truell、Sualeh Asif、Arvid Lunnemark
以百度百科的解释为例:Skills,一种标准扩展规范,是可以让Agent变得可靠、可控、可复用的技能包。“Skills”这个概念最早由Anthropic公司提出,作为其大模型Claude的一种能力扩展机制,并于2025年10月16日正式推出。随着这套做法越来越成熟,并被社区广泛接受,Skills如今已成为大多数Agent开发工具和IDE都支持的一种标准扩展规范,并已获得微软Azure、GitHub
以百度百科的解释为例:Skills,一种标准扩展规范,是可以让Agent变得可靠、可控、可复用的技能包。“Skills”这个概念最早由Anthropic公司提出,作为其大模型Claude的一种能力扩展机制,并于2025年10月16日正式推出。随着这套做法越来越成熟,并被社区广泛接受,Skills如今已成为大多数Agent开发工具和IDE都支持的一种标准扩展规范,并已获得微软Azure、GitHub
以百度百科的解释为例:Skills,一种标准扩展规范,是可以让Agent变得可靠、可控、可复用的技能包。“Skills”这个概念最早由Anthropic公司提出,作为其大模型Claude的一种能力扩展机制,并于2025年10月16日正式推出。随着这套做法越来越成熟,并被社区广泛接受,Skills如今已成为大多数Agent开发工具和IDE都支持的一种标准扩展规范,并已获得微软Azure、GitHub
一共完成了三次任务,使用模型分别是deepseek-v3-2-volc、deepseek-v3-2-volc、minimax-m2.7;这是最后一次任务,大致完成了以下工作内容,之后本人自行结束了对话。用量分别是4.72、12.08、6.60积分。
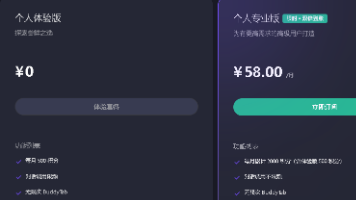
Qoder CN (原通义灵码) 是由阿里云提供的智能编码辅助工具,提供代码智能生成、智能问答、多文件修改、编程智能体等能力,为开发者带来高效、流畅的编码体验。官网:https://platform.deepseek.com/sign_in。插件登录后会有免费的300积分的额度。我是用的是Qoder CN插件。大家可以自行在插件市场中安装。选择供应商,并填写API秘钥。

Qoder CN (原通义灵码) 是由阿里云提供的智能编码辅助工具,提供代码智能生成、智能问答、多文件修改、编程智能体等能力,为开发者带来高效、流畅的编码体验。官网:https://platform.deepseek.com/sign_in。插件登录后会有免费的300积分的额度。我是用的是Qoder CN插件。大家可以自行在插件市场中安装。选择供应商,并填写API秘钥。
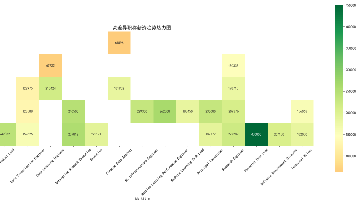
该数据集收录了2020-2025年全球数据科学、人工智能及机器学习领域的真实薪资数据,共133,349条记录,11个维度属性。数据涵盖职位名称、经验水平、远程工作比例等关键信息,可用于分析薪资趋势、地域差异及职场环境对薪酬的影响。