




- @weixin_52185313
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文首先介绍了 shapley 值的概念,通过一个LoL比赛的例子,拆解了 shapley 值的计算方法,并介绍了其中的数学方法。本文将对使用 Shapley 值解释机器学习模型的介绍, 主要举例讲解了Shapley用于各种机器学习算法的解释方法。研究已经严格证明,有且仅有一个ψ\psiψ方程同时满足上面三个性质,这就是shapley value。ψiNv1∣N∣!∑S∈N╲i∣S∣!∣N∣−∣S

"nodes": ["data": { "type": "start", "title": "开始" }},"data": {"title": "生成草稿","prompt": "请根据主题{{#start_node.topic#}}生成一篇草稿"},"data": { "type": "if-else", "title": "风险判断" }},"data": { "type": "human-i

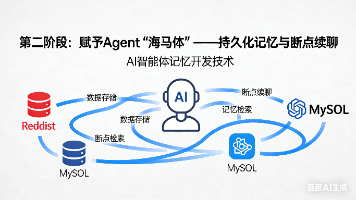
文章摘要: 本文介绍了如何为AI Agent添加持久化记忆功能,实现会话的断点续聊。通过LangGraph框架的Checkpointer机制,可将对话状态自动保存到数据库,下次运行时通过thread_id恢复上下文。文章详细演示了使用MemorySaver实现本地内存存储的步骤,包括引入检查点模块、修改编译配置和运行时传入thread_id等关键代码实现。同时预留了切换到Redis存储的接口,为后
MCP协议:AI系统连接外部世界的标准化方案 MCP(Model Context Protocol)是解决大模型与外部系统连接的核心协议,它超越了简单的函数调用,提供了一套完整的标准化交互框架。该协议主要解决三个关键问题:如何安全访问业务系统、如何发现可用工具、如何规范调用流程。 MCP协议包含三大核心能力: Tools(可执行动作) Resources(可读取资源) Prompts(可复用模板)

本文介绍了在Docker环境中构建基础AI Agent的开发流程。首先强调理解底层数据流的重要性,提出Agent本质是一个包含观察、思考、行动、结果的循环过程。详细说明了Docker网络配置要点,包括服务名作为内部域名的使用方式。提供了虚拟环境配置指南,推荐使用pyproject.toml管理依赖。实战部分展示了如何定义工具集(如获取日期时间函数)并与LLM交互,通过纯Python实现一个能调用本

LangGraph 是一个面向有状态 Agent 的低层编排框架,它通过 state、node、edge、reducer 和 checkpoint 来驱动复杂流程执行。到这里,前面的问题其实都已经融在正文里讲完了。如果你想最后快速复习,可以直接看这张表。问题简洁回答什么是 LangChain?一个面向 LLM 应用和 Agent 开发的高层框架,不只是“链式调用库”LangChain 的核心组件有

本文探讨了大模型从"问答系统"向"智能体(Agent)"演进的关键转变。文章指出,Agent系统通过引入目标导向、工具调用、状态管理和环境交互四大能力,使大模型能够持续完成任务而非仅生成一次性回答。文中重点分析了LangChain Agent的运行机制和ReAct范式,强调Agent不是简单的工具调用封装,而是包含模型、工具、状态、反馈循环、记忆和安全控制等

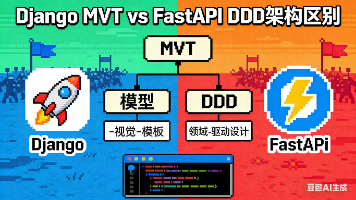
Django MVT与FastAPI DDD架构的核心区别在于设计哲学与组件结构。Django采用全功能集成式的MVT(Model-View-Template)模式,内置ORM、模板引擎等组件,适合快速构建全栈应用;而FastAPI基于路由和依赖注入,强调模块化与高性能,默认支持异步和API优先开发,适合微服务和高并发场景。关键差异包括:Django隐式处理依赖(如request对象),FastA
本文介绍了在Docker环境中构建基础AI Agent的开发流程。首先强调理解底层数据流的重要性,提出Agent本质是一个包含观察、思考、行动、结果的循环过程。详细说明了Docker网络配置要点,包括服务名作为内部域名的使用方式。提供了虚拟环境配置指南,推荐使用pyproject.toml管理依赖。实战部分展示了如何定义工具集(如获取日期时间函数)并与LLM交互,通过纯Python实现一个能调用本
摘要:Tortoise-ORM是一个异步Python ORM框架,基于Django ORM设计,适合FastAPI等异步应用。文章介绍了ORM的基本概念、Tortoise-ORM的配置方法(包括MySQL连接设置),以及使用Aerich进行数据库迁移的完整流程(初始化、生成迁移脚本、应用迁移等)。同时提供了详细的用户模型示例,展示字段类型定义和常用配置选项。
