




- @weixin_51331359
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一、Kaggle介绍Kaggle是在AI行业领域内,一个国内外都比较出名的网站,国内的阿里天池就是对标这个网站。上面有着丰富的数据集,包括计算机视觉CV领域的(包括:图像识别、目标检测、语义分割等)数据集,也有像波士顿房价预测这样的数据集,还有语音识别方面的数据集等等,上面不定时会举办一些比赛,任何注册成员都可以参加,Kaggle不但免费提供数据集,每周还有一定的免费GPU和TPU使用额度(GPU
一、初始环境配置1.ubuntu20.04配置显卡驱动以我的这篇文章为例子,显卡RTX2060及以下的都可以使用我的方法快速完成配置,RTX2060以上的我尚未进行尝试,请自行斟酌尝试。联想拯救者R7000P2020版ubuntu20.04快速配置显卡驱动(RTX2060)_Leonard2021的博客-CSDN博客2.在ubuntu20.04上安装anaconda3这里我不详细说,在网上有众多教

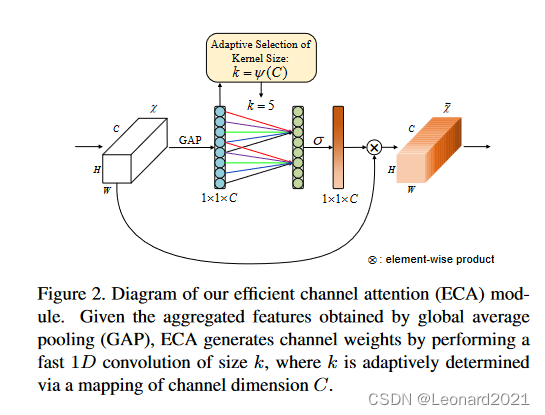
一、前言ECA-NET(CVPR 2020)简介:论文名:ECA-Net: Effificient Channel Attention for Deep Convolutional Neural Networks论文地址:https://arxiv.org/abs/1910.03151开源代码:https://github.com/BangguWu/ECANet作为一种轻量级的注意力机制,ECA-
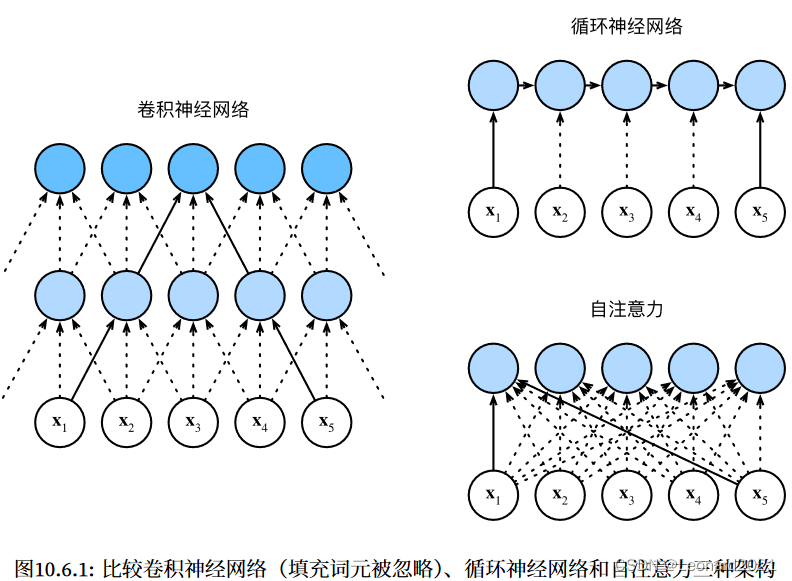
一、Vision Transformer介绍Transformer的核心是 “自注意力” 机制。论文地址:https://arxiv.org/pdf/2010.11929.pdf自注意力(self-attention)相比 卷积神经网络 和 循环神经网络 同时具有并行计算和最短的最大路径⻓度这两个优势。因此,使用自注意力来设计深度架构是很有吸引力的。对比之前仍然依赖循环神经网络实现输入表示的自注意
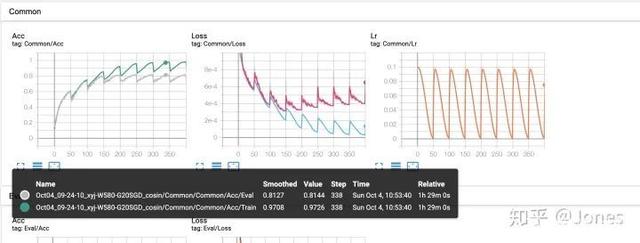
一、前言正当本人在纠结如何组合使用 优化器和学习率 调整方法时,看到了这篇文章,属实让我豁然开朗。口说无凭,实验数据比对更能说明问题。看似玄学,炼丹(训练)也有门路。膜拜大佬!二、正文本文作者模拟复现了自己在深度学习训练过程中可能遇到的多种情况,并尝试解决这些问题,文章围绕学习率、动量、学习率调整策略、L2正则、优化器展开。“深度模型是黑盒,而且本次并没有尝试超深和超宽的网络,所以结论只能提供一个
一、前言ECA-NET(CVPR 2020)简介:论文名:ECA-Net: Effificient Channel Attention for Deep Convolutional Neural Networks论文地址:https://arxiv.org/abs/1910.03151开源代码:https://github.com/BangguWu/ECANet作为一种轻量级的注意力机制,ECA-
一、前言正当本人在纠结如何组合使用 优化器和学习率 调整方法时,看到了这篇文章,属实让我豁然开朗。口说无凭,实验数据比对更能说明问题。看似玄学,炼丹(训练)也有门路。膜拜大佬!二、正文本文作者模拟复现了自己在深度学习训练过程中可能遇到的多种情况,并尝试解决这些问题,文章围绕学习率、动量、学习率调整策略、L2正则、优化器展开。“深度模型是黑盒,而且本次并没有尝试超深和超宽的网络,所以结论只能提供一个
一、前言正当本人在纠结如何组合使用 优化器和学习率 调整方法时,看到了这篇文章,属实让我豁然开朗。口说无凭,实验数据比对更能说明问题。看似玄学,炼丹(训练)也有门路。膜拜大佬!二、正文本文作者模拟复现了自己在深度学习训练过程中可能遇到的多种情况,并尝试解决这些问题,文章围绕学习率、动量、学习率调整策略、L2正则、优化器展开。“深度模型是黑盒,而且本次并没有尝试超深和超宽的网络,所以结论只能提供一个
一、环境的搭建1.tensorflow2.4和pytorch1.7环境的搭建参考:树莓派4B32位官方系统配置tensorflow2.4以及pytorch1.7_Leonard2021的博客-CSDN博客2.opencv4.5.3环境的搭建参考:树莓派32位官方系统配置opencv(whl)无需编译_Leonard2021的博客-CSDN博客3.其他python包的安装pip install pa

首先参考https://blog.csdn.net/dujuancao11/article/details/114002979这篇文章,把python的默认版本改为3.7然后利用WinSCP传输工具把相应的whl文件传输到树莓派的某个文件夹中,所需的whl文件在本人的上传资源中可以获取。首先,配置tensorflow2.4安装相关系统依赖sudo apt-get install -y libhdf
