
写文章




- @weixin_48052161
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
大模型工具--04--Trae IDE入门
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档。
大模型工具--03--Claude Code知识点
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档。
大模型工具--02--Claude Code上手案例
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档。
大模型工具--02--Claude Code上手案例
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档。
大模型工具--03--Claude Code知识点
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档。
大模型工具--01--ClaudeCode简介安装
Claude在不同平台中安装命令如下:
大模型工具--01--ClaudeCode简介安装
Claude在不同平台中安装命令如下:
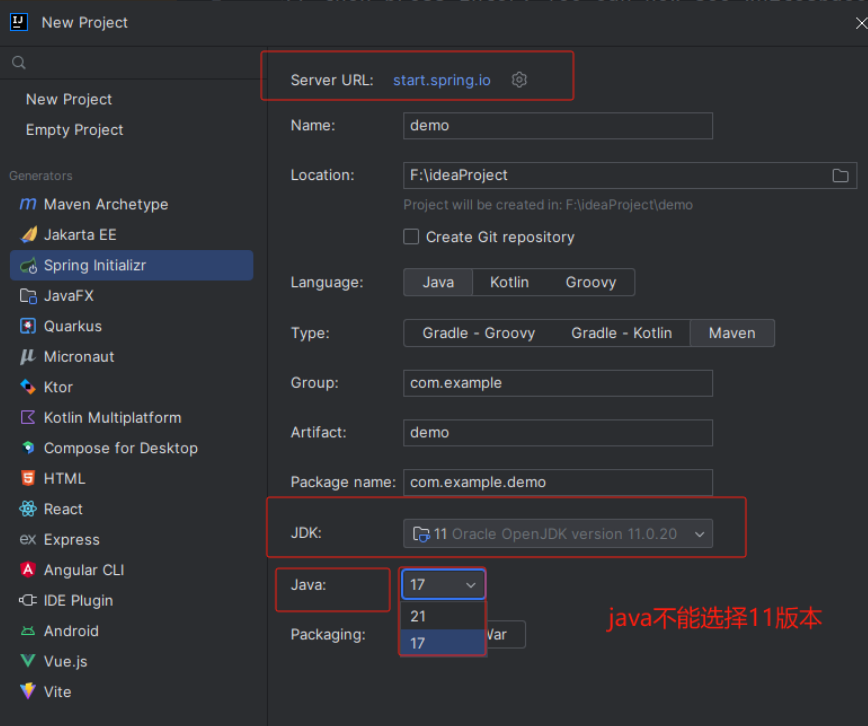
SpringBoot注解--09--idea创建spring boot项目,java版本只能选择17和21
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档。

sql函数--03---mysql--LPAD()函数、RPAD()函数----trim()函数
lpad函数lpad:即left padding的简称,意思是左边填充格式lpad(str,len,padstr)参数说明:str: 要处理的对象len: 处理完后的str长度为lenpadstr: 如果str的长度小于len指定的值,那么长度差由padstr在左边填充;如果str的长度大于len指定的值,则截取str到len指定的长度。返回值说明:lpad函数返回的是处理后的str案例:SELE
