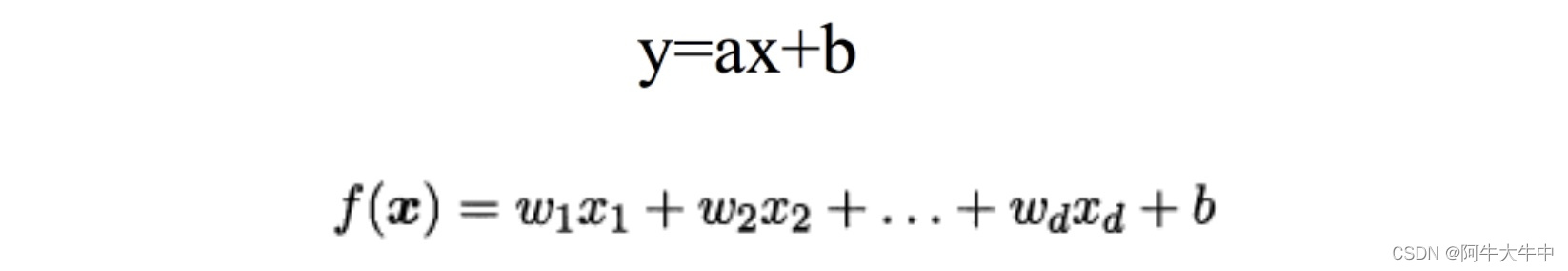- @weixin_46351593
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了阿里淘宝天猫集团在SIGIR 2026发表的论文《RecGPT-Mobile: On-Device Large Language Models for User Intent Understanding in Taobao Feed Recommendation》。该研究提出将轻量化LLM部署到移动端,实时分析用户行为序列并预测搜索意图,以解决云端推荐系统延迟问题。系统采用端侧意图理解+
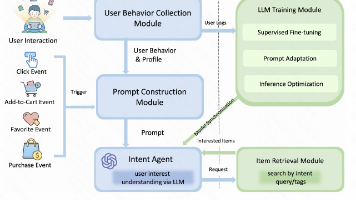
本文介绍了阿里淘宝天猫集团在SIGIR 2026发表的论文《RecGPT-Mobile: On-Device Large Language Models for User Intent Understanding in Taobao Feed Recommendation》。该研究提出将轻量化LLM部署到移动端,实时分析用户行为序列并预测搜索意图,以解决云端推荐系统延迟问题。系统采用端侧意图理解+
文章目录介绍day011. 项目开发准备2. 启动项目开发3. git管理项目4. 创建项目的基本结构5 引入antd6. 引入路由7. Login的静态组件8. 收集表单数据和表单的前台验证9. 高阶函数与高阶组件day021. 后台应用2. 编写ajax代码3. 实现登陆(包含自动登陆)4. 搭建admin的整体界面结构5. LeftNav组件day031. Header组件2. jsonp解
图神经网络中还有一个重要概念,即图采样。如果数据量过大,则是否可以仿照传统深度学习的小批量训练方式呢?答案是不可以,因为普通深度学习中的训练样本之间并不依赖,但是图结构的数据中,节点与节点之间有依赖关系,如下图:普通深度学习的训练样本在空间中是一些散点,可以随意小批量采样,无论如何采样得到的训练样本并不会丢失什么信息。而图神经网络训练样本之间存在边的依赖,也正是因为有边的依赖,也正是因为有边的依赖
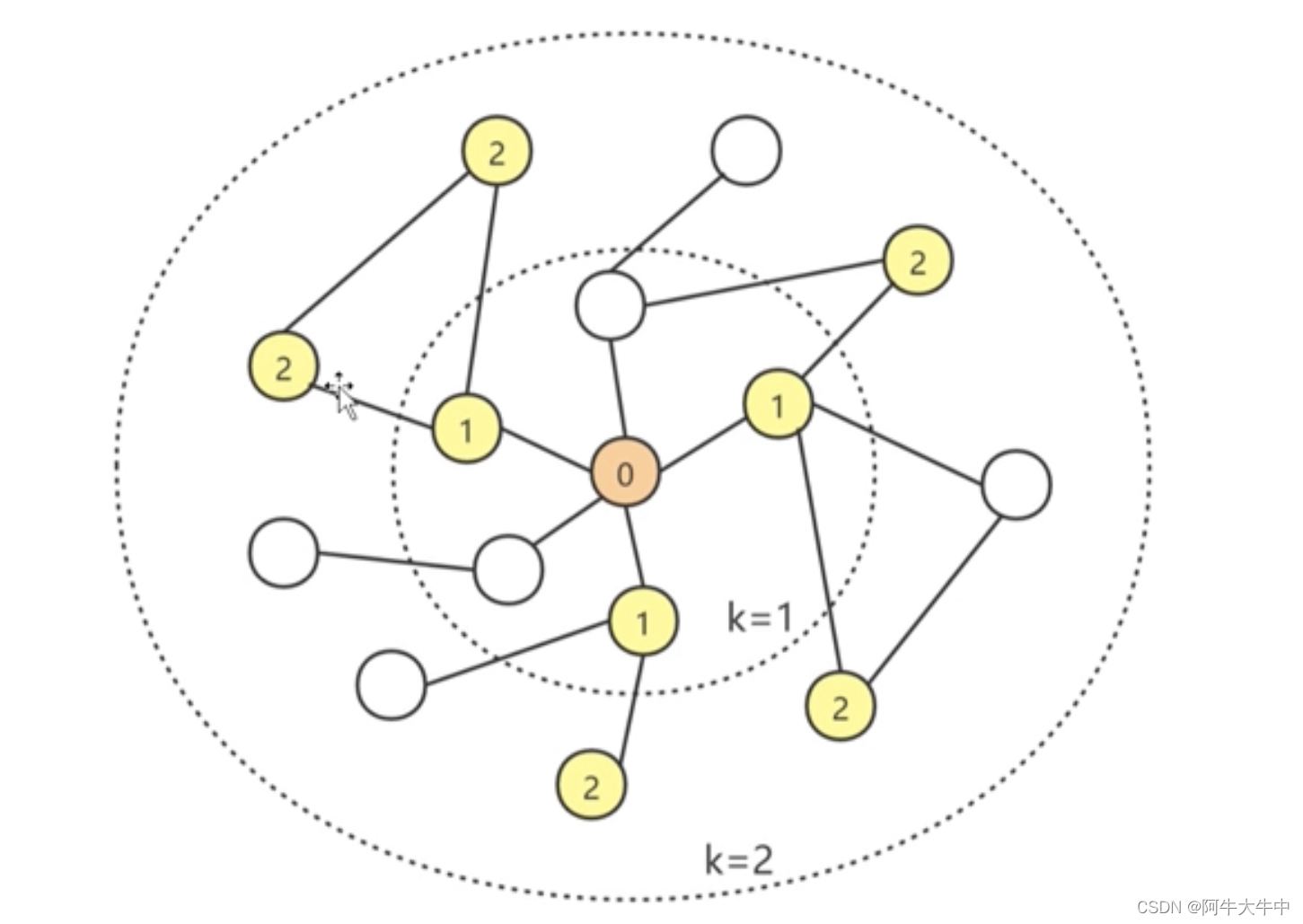
图神经网络中还有一个重要概念,即图采样。如果数据量过大,则是否可以仿照传统深度学习的小批量训练方式呢?答案是不可以,因为普通深度学习中的训练样本之间并不依赖,但是图结构的数据中,节点与节点之间有依赖关系,如下图:普通深度学习的训练样本在空间中是一些散点,可以随意小批量采样,无论如何采样得到的训练样本并不会丢失什么信息。而图神经网络训练样本之间存在边的依赖,也正是因为有边的依赖,也正是因为有边的依赖
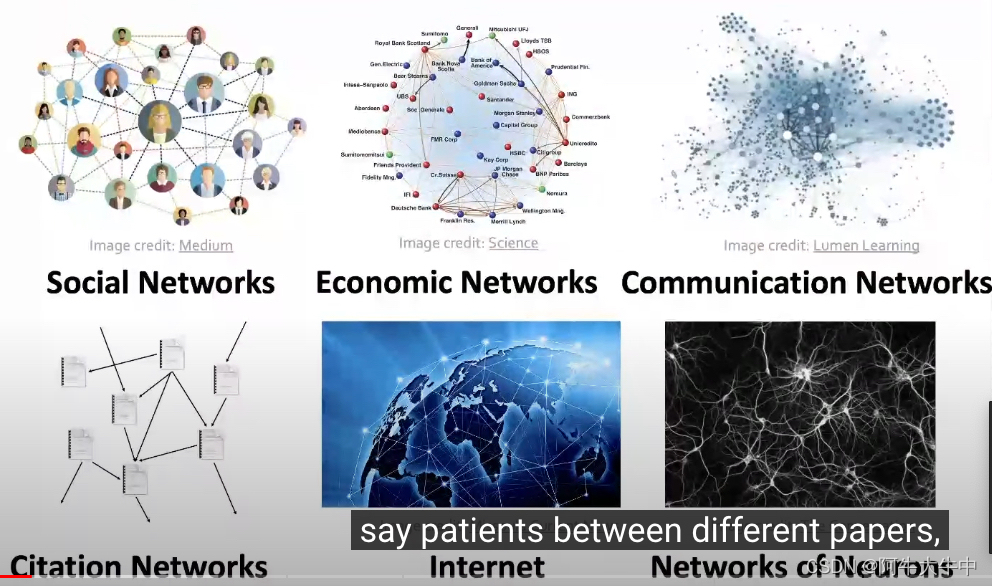
首先,介绍一下什么是图:简单来说,图是一种描述和分析实体之间关系的通用表达形式。图的种类也有很多,比如:事件图、计算机网络图、疾病传播图、食物链图、分子图、地铁路线图。社交网络图、金融图、沟通图、论文引用图、因特网、神经元网络。知识图谱、监管网络图、场景图、代码结构图、分子结构图、3D图形。
CIFAR-10数据集包含60000张32x32彩色图像,分为10个类,每类6000张。有50000张训练图片和10000张测试图片。数据集分为五个训练batches和一个测试batch,每个batch有10000张图像。测试batch包含从每个类中随机选择的1000个图像。训练batches以随机顺序包含剩余的图像,但有些训练batches可能包含一个类的图像多于另一个类的图像。在它们之间,训练

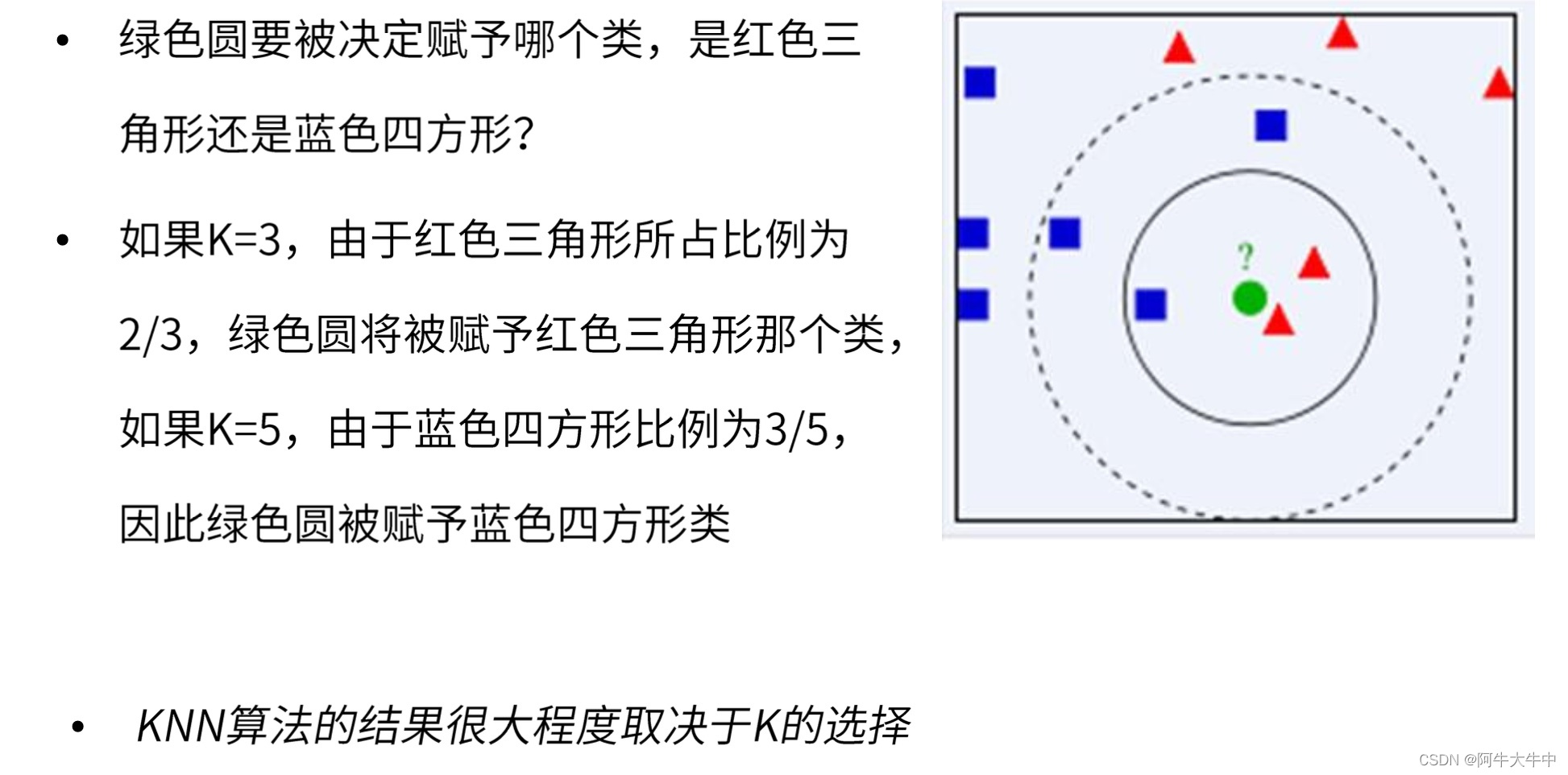
决策树是一种简单高效并且具有强解释性的模型,广泛应用于数据分析领域。其本质上是一颗自上而下的由多个判断节点组成的树。条件熵-conditional entropy。都压缩到[0,1]区间内。
损失函数是系数的函数,另外还要传入数据的x,y def compute_cost(w , b , points) : total_cost = 0 M = len(points) # 逐点计算平方损失误差,然后求平均数 for i in range(M) : x = points [ i , 0 ] y = points [ i , 1 ] total_cost +=(y - w * x - b)