




- @weixin_45955039
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
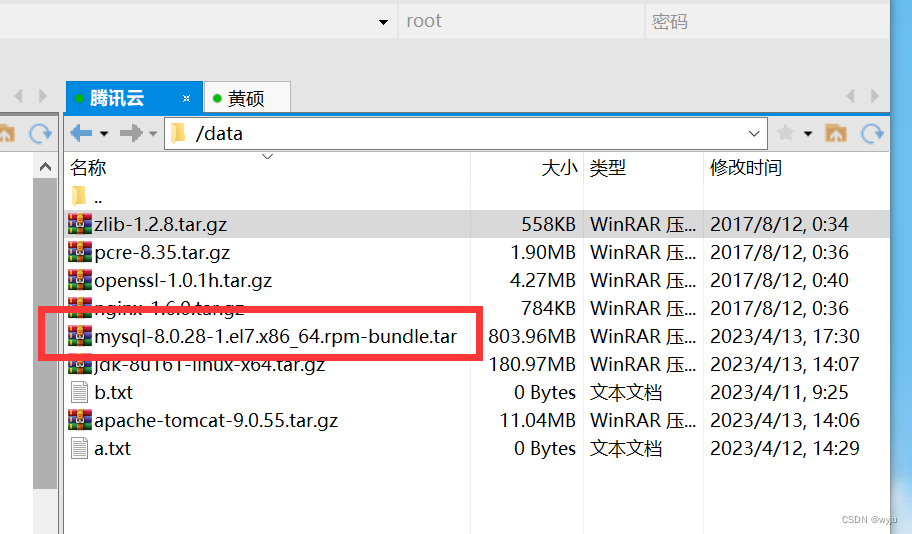
解压是获取了mysql各个安装包,并不只是直接安装成功了。
1.解压Spark压缩包到D盘,如下图所示:2.在环境变量中配置SPARK_HOME,如下图所示:SPARK_HOME自己的路径D:\axc\spark-2.4.6-bin-hadoop2.73.把SPARK_HOME 设置为python的exe文件PYSPARK_PYTHON自己的路径C:\Users\wyj\AppData\Local\Programs\Python\Python37\pyth
Failed on local exception: org.apache.hadoop.ipc.RpcException: RPC response exceeds maximum data length; Host Details : local host is: "node04/192.168.56.104"; destination host is: "node01":9870;遇到这个错
关闭防火墙** 查看防火墙状态命令**systemctl status firewalld** 关闭防火墙**systemctl stop firewalld** 开机禁用防火墙**systemctl disable firewalld修改静态ip每台虚拟机都要修改静态ip,不要忘了重启网络哦== *==重启网络的命令service network restart修改主机名字hostnamectl
拍摄快照带有静态ip,克隆三台虚拟机,一共四台虚拟机。也可以克隆两台虚拟机,一共三台虚拟机。以下用的是四台虚拟机。拍摄快照的步骤:右键—快照–拍摄快照克隆虚拟机点击右键----快照—快照管理修改静态ip每台虚拟机都要修改静态ip,不要忘了重启网络哦== *==重启网络的命令service network restart修改主机名字hostnamectl set-hostname bigdata10
【代码】pycharm连接虚拟机中的spark。
新建虚拟机1.点击创建新的虚拟机2.典型,下一步3.镜像稍后安装4.浏览可以自己设置路径,可以随意安装到任何盘中5.点击DVD 。把自己的镜像放上去6.浏览是放自己的安装路径的7.点击启动虚拟机,等待安装8.选择语言9.分别配置软件选择,安装位置,网络配置9.1 软件选择9.2配置网络9.3安装位置达到这个效果就证明配置好了10配置用户、创建密码TiBAd3lqdQ==,size_20,color
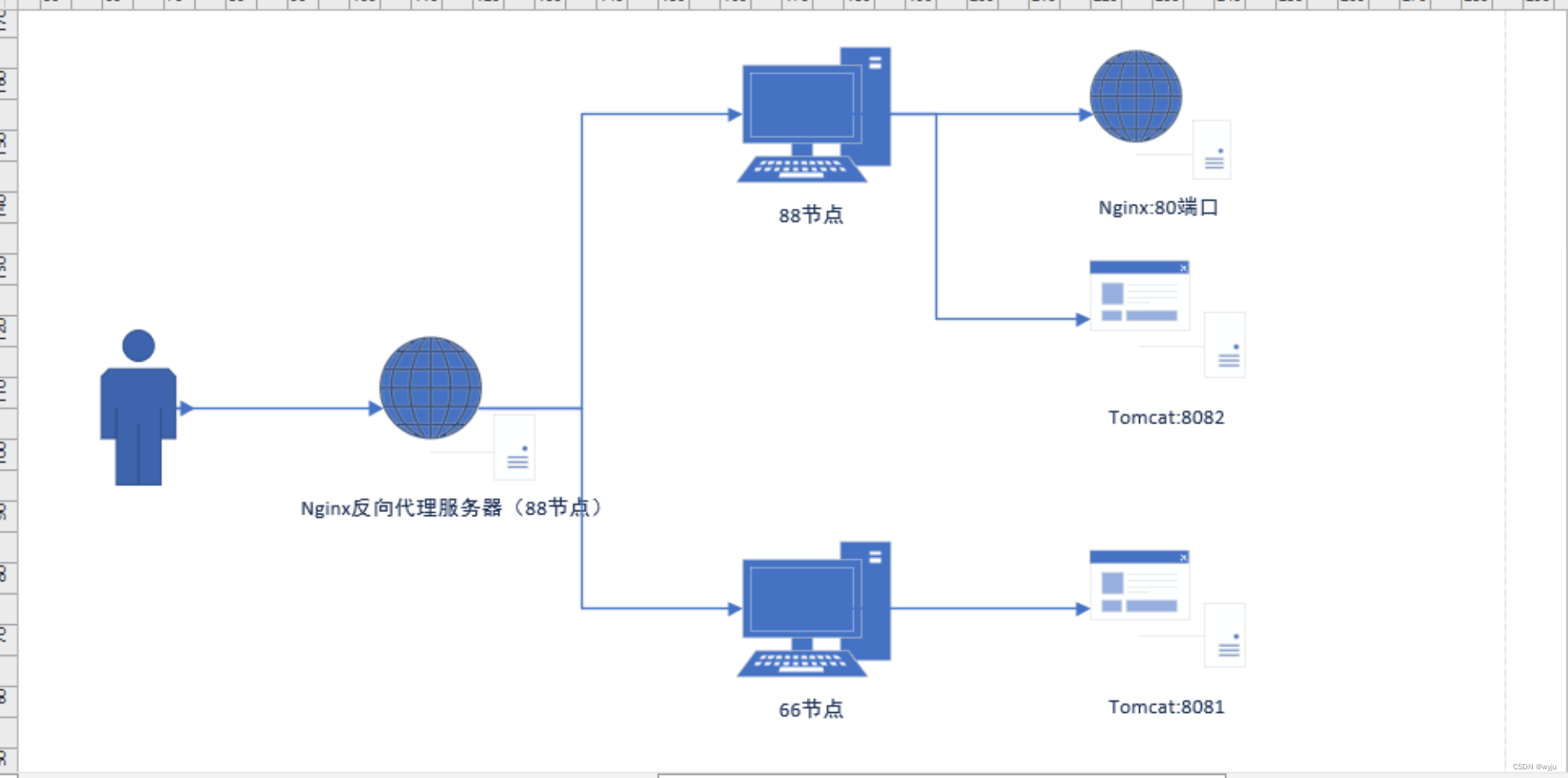
两台虚拟机:88节点是自己的虚拟机66节点是小组成员的虚拟机,我们暂且叫同学机tomcat端口,分别为8081和8082总结就是:自己虚拟机上面安装nginx和tomcat8082同学机上安装tomcat8081。
关闭防火墙** 查看防火墙状态命令**systemctl status firewalld** 关闭防火墙**systemctl stop firewalld** 开机禁用防火墙**systemctl disable firewalld修改静态ip每台虚拟机都要修改静态ip,不要忘了重启网络哦== *==重启网络的命令service network restart修改主机名字hostnamectl
1.什么是spark?Spark 是一个用来实现快速而通用的集群计算的平台。2.Spark生态系统?spark core:spark 核心计算spark sql: 对历史数据的交互式查询spark streaming : 近实时计算spark ml : 机器学习spark graphx : 图计算3.常见的 分布式文件系统?hdfsfastdfsTachyonTFS(...