




- @weixin_45312236
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
启动一个 Ngrok 容器,用来创建一个 HTTP 隧道,把本地的服务暴露在互联网上。这在开发和测试时非常有用,比如当你需要外部用户测试你的本地服务或者需要与远程客户端进行集成测试时。端口,你希望外部用户可以访问这个服务。通过运行上述命令,Ngrok 会提供一个类似于。的 URL,外部用户可以通过这个 URL 访问你的本地服务。假设你在本地运行了一个 Web 服务,该服务监听。

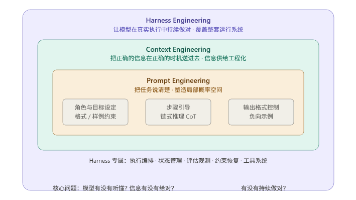
《LLM训练全流程解析:从预训练到应用实践》系统阐述了大语言模型的三阶段开发过程:预训练阶段通过海量数据(如44TB文本)构建知识基底;监督微调阶段通过人工标注塑造对话人格;强化学习阶段培养推理能力。文章揭示了提示工程技巧(如思维链、RAG)如何弥补模型短板,并强调LLM不是替代工具而是效率倍增器,指出其能力存在"瑞士奶酪式"的不规则缺陷,建议使用者保持验证意识。最后提出深刻思

系统梳理 AI 工程三次认知升级,揭秘同样的模型为何差距悬殊——真正决定 Agent 落地成败的,是模型之外的那套运行系统。
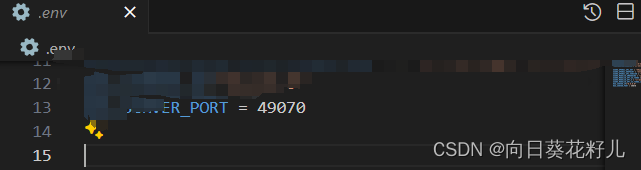
必须保证原始启动端口(server启动端口或者通过环境变量设置的端口)、dockerfile expose的端口、docker-compose.yml被映射的端口(如果不需要使用docker-compose.yml、请忽略)三口一致。
安装验证安装是否成功。

安装验证安装是否成功。
TextRank算法基于PageRank,用于为文本生成关键字和摘要。

显存,也被称作帧缓存。独立显卡拥有独立显存,而集成显卡通常是没有的,需要占用部分主内存来达到缓存的目的是集成在主板上的,与主处理器共享系统内存。一般会在很多轻便薄型的笔记本与低端的台式电脑上得到广泛的应用性能较低,适合一般办公和基本图形任务。一块独立的图形处理器,有自己的显存,并且不与主处理器共享内存。独立显卡通常性能更强大,适合处理复杂的图形和游戏。在一些专业应用和高性能需求的场景中,独立显卡往

上一章讨论了文档标准化加载,现在转向文档的细分,这虽简单却对后续工作有重大影响。

显存,也被称作帧缓存。独立显卡拥有独立显存,而集成显卡通常是没有的,需要占用部分主内存来达到缓存的目的是集成在主板上的,与主处理器共享系统内存。一般会在很多轻便薄型的笔记本与低端的台式电脑上得到广泛的应用性能较低,适合一般办公和基本图形任务。一块独立的图形处理器,有自己的显存,并且不与主处理器共享内存。独立显卡通常性能更强大,适合处理复杂的图形和游戏。在一些专业应用和高性能需求的场景中,独立显卡往