




- @weixin_44966641
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用yolov5训练自己的目标检测数据集yolov4出来后不久,又出现了yolov5,没有论文。虽然作者没有放上和yolov4的直接测试对比,但在COCO数据集的测试效果还是很可观的。很多人考虑到YOLOv5的创新性不足,对算法是否能够进化,因此yolov5的名头仍有争议。但是既然github上有如此多的star,说明还是受到大多数人认可的一个工程。并且yolov5是十分容易上手使用的一个目标检测
使用百度云智能SDK和树莓派搭建简易的人脸识别系统 Python语言版硬件树莓派4B一个CSI摄像头一个笔者使用的是树莓派4B和CSI摄像头,但是树莓派3和USB摄像头等相似设备均可。百度云智能设置Step 1 登录百度云智能 网址https://cloud.baidu.com/首先登录百度账号,与百度云、百度贴吧等互通,可直接扫码登录。如果没有百度账号请先自行注册。Step 2 实名认证百度的产
本文为[b站@bryanyzhu](https://space.bilibili.com/511378644)老师四期视频理解相关论文解读的汇总图文笔记。
深度学习编译MLIR初步深度模型的推理引擎目前深度模型的推理引擎按照实现方式大体分为两类:解释型推理引擎和编译型推理引擎。解释型推理引擎一般包含模型解析器,模型解释器,模型优化器。模型解析器负责读取和解析模型文件,转换为适用于解释器处理的内存格式;模型优化器负责将原始模型变换为等价的、但具有更快的推理速度的模型;模型解释器分析内存格式的模型并接受模型的输入数据,然后根据模型的结构依次执行相应的模型
机器学习理论——优雅的模型:变分自编码器(VAE)
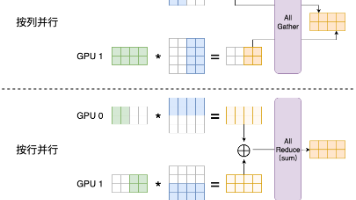
Tensor Parallel 是目前大模型训练和推理中最常用的并行方式之一,主要针对 Transformer 类模型。本文首先介绍了 GEMM 切分的按列并行和按行并行两种方式,然后在 Transformer 的各个组件,包括 MLP、Attention、input embedding、LM head + cross entropy loss 中根据实际情况设计具体的切分方案。
本文我们先介绍了强化学习中的价值函数,然后介绍如何训练价值网络来拟合价值函数,以及 Q-learning/DQN 中如何不断地优化 policy,最后介绍了 Q-learning 在实际实现中常用的几个技巧。

深度学习编译MLIR初步深度模型的推理引擎目前深度模型的推理引擎按照实现方式大体分为两类:解释型推理引擎和编译型推理引擎。解释型推理引擎一般包含模型解析器,模型解释器,模型优化器。模型解析器负责读取和解析模型文件,转换为适用于解释器处理的内存格式;模型优化器负责将原始模型变换为等价的、但具有更快的推理速度的模型;模型解释器分析内存格式的模型并接受模型的输入数据,然后根据模型的结构依次执行相应的模型
Docker容器中使用Nvidia GPU报错 docker: Error response from daemon: could not select device driver “” with capabilities: [[gpu]].问题出现我们知道,想要在 docker19 及之后的版本中使用 nvidia gpu 已经不需要单独安装 nvidia-docker 了,这已经被集成到了 d
深度学习三大谜团:集成、知识蒸馏和自蒸馏