- @weixin_44275820
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
前言:我们要悄悄努力,不用惊艳所有人,只需要惊艳自己就好,因为人生是对自己负责!本篇文章将讲述,github Pull Request合入后,原仓库的commit log如何显示为一条线?之前也写过类似的两篇文章:1、github的pull Request使用2、github上fork原项目,如何将本地仓库代码更新到最新版本?不同之处在于合入方式,之前写的是按照"merge pull reques
1、pytest的安装pip install pytest2、查看pytest版本号pytest -V3、pytestkuk框架的简介4、pip install pytest-sugar(对运行过程进行界面美化)pip install pytest-rerunfailures(重新运行出错的测试用例)pip install pytest-xdist(多任务同时并发的执行测试用例)...
前言:前段时间,压测遇到一个问题,在压测的时候,tps波动很频繁。使用xshell远程连接到应用服务器,通过top命令看了下服务器资源情况,cpu波动也很频繁,其它服务器都正常。打开JvisualVM,双击对应的应用进程然后进入Sampler,在cpu波动的时候点击cpu进行抽样抽样进行一段时间后(一般1-2分钟即可),点击“stop”,然后点击“snapshot”生成快照接着按照“Total T
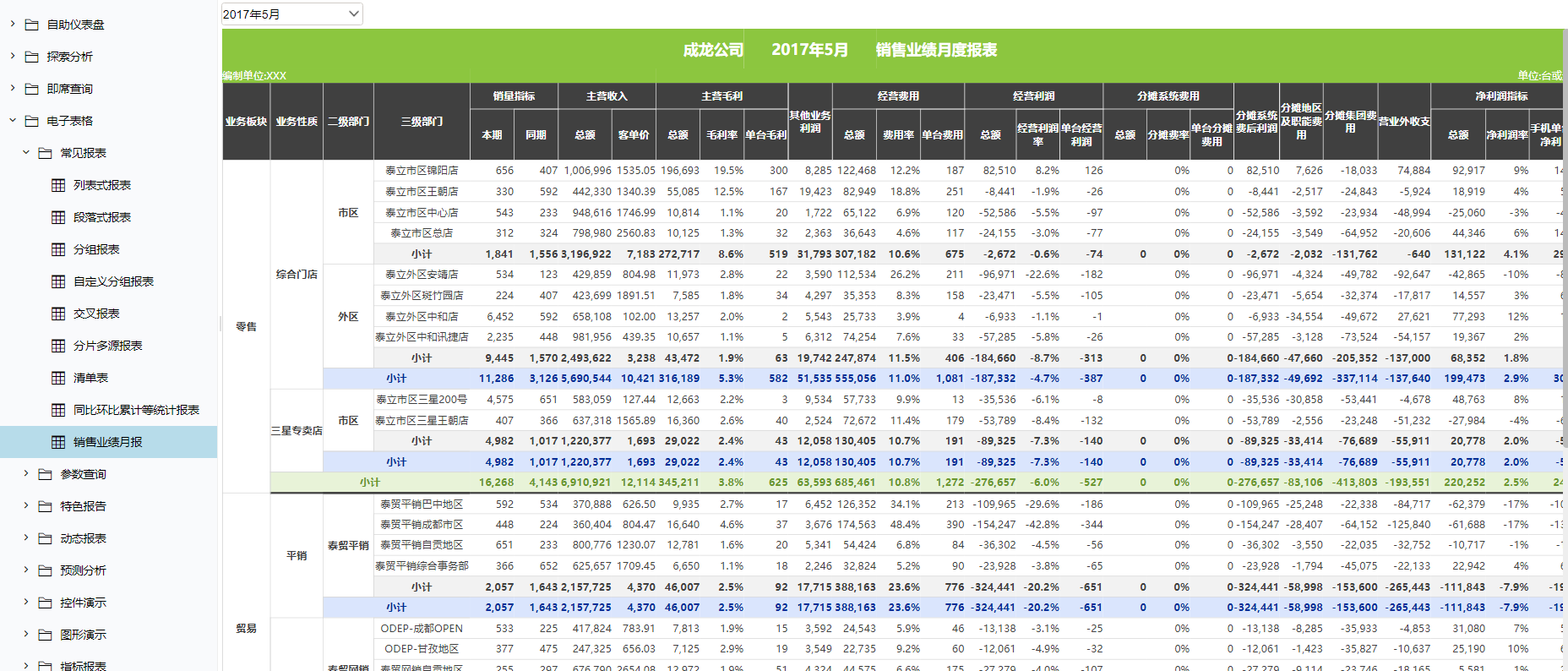
前言:BI报表测试是一项重要的测试内容,因为面对的使用群体一般是公司高层或者用户中的重要群体。出现问题影响较大,所以必须仔细且谨慎对待。本文根据自己之前的测试经验,结合其它相关资料,做个简单的总结汇总,如有其它建议,可以留言或者私聊,期待沟通交流。针对BI报表测试,一般情况下,我们需要自己准备数据,来验证报表统计的准确性。由于系统的构成不一样,简单把报表测试过程分解为两个层次:数据收集汇总、数据统
1、allure 的介绍2、allure 的报告概览3、allure的安装4、使用allure2生成更加精美的测试报告pip install allure-pytest(安装这个辅助allure生成测试报告)pytest --alluredir=指定路径(指定allure报告数据生成路径)allure serve 报告路径(生成HTML报告,这个会直接在线打开报告)allur...
前言:我们在写程序过程中通常都会要求程序运行时间最短,那么我们怎么来统计程序的耗时情况呢?这里有几个方法供大家参考!方法一#!/usr/bin/env python# _*_ coding: utf-8 _*_# @project : xmindtotable# @File: test.py# @Date: 2021/4/6 9:35 上午# @Author: 李文良import datetime
前言:目前很多公司用的是企业微信或者钉钉,对于服务的可用性都会有一个人告警通知,方面我们及时了解消息,这里我做了一个简单的封装,方便大家使用!#!/usr/bin/env python# _*_ coding: utf-8 _*_# @project : dadi-api-platform# @File: send_notify.py# @Date: 2021/2/23 11:28 上午# @Au
大家都知道Kafka是一个高吞吐的消息队列,是大数据场景首选的消息队列,这种场景就意味着发送单位时间消息的量会特别的大,那既然如此巨大的数据量,kafka是如何支撑起如此庞大的数据量的分发的呢?今天我们从kafka架构以如何优化GC两个方面讲解.kafka架构既然要说kafka是如何通过内存缓冲池设计来优化JVM的GC问题,那么,如果不清楚kafka 的架构设计,又怎么更好的调优呢?起码的我们要知
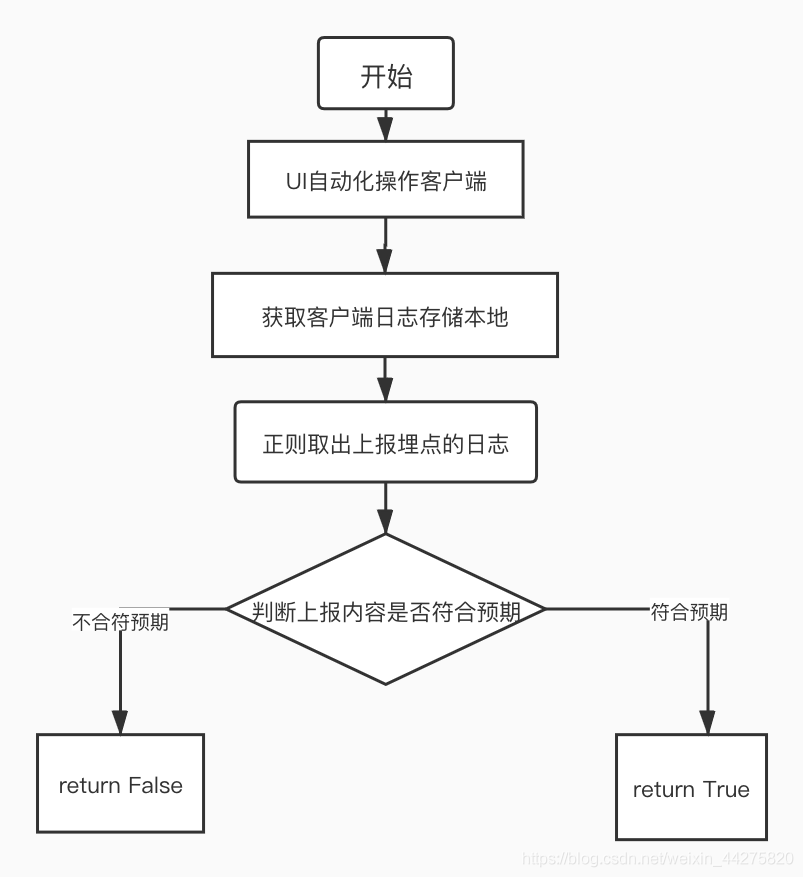
前言:今天我们来学习下App埋点测试用例如何做自动化回归!一、背景和目的线上存在埋点数量总数大于1000个,主流程case大于300个,在对功能迭代过程中经常会有对已有的埋点进行回归的述求,以往都是消耗大量的时间去手工回归,同时覆盖2端还容易出现漏测的现象。为了改善现状,内部调研可做成UI自动化回归,经过实践后约能提效50%,且只要及时补充场景,就可以大大降低漏测的场景。二、断言方法如何获取客户端