




- @weixin_44026026
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
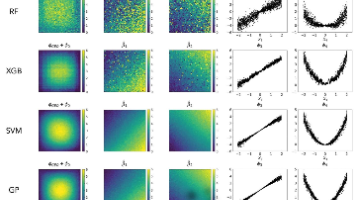
原文:GeoShapley: A Game Theory Approach to Measuring Spatial Effects in Machine Learning Models随着机器学习(ML)和人工智能(AI)在地理空间现象建模中的广泛应用,其在处理海量异质数据、捕捉复杂结构方面的优势日益凸显。然而,机器学习模型的“黑箱”特性严重阻碍了其在科学发现中的应用——地理学家更关注模型的可解
在城市数据分析领域,研究对象的空间分布通常呈现出不均匀性,具有明显的空间异质性。密度较高的点数据往往代表着区域内事件的热点。因此,城市区域内热点的探测成为了城市研究的一个焦点话题,对于规划者、研究人员以及管理部门具有重要的价值。以犯罪热点的探测为例,通过对城市犯罪历史数据的分析可以揭示出犯罪活动发生的原因,进而有助于相关管理部门制定更加有效的犯罪预防策略。在过去的研究中,已经有多种经典的聚类算法或

在基础阶段我们已经学习了,了解了的概念。Q-Learning的思想就是根据值迭代得到的。但要前面的值迭代每次都对所有状态和动作的Q值更新一遍,这在现实中可行性并不高。Q-Learning只使用进行操作。那么,怎么处理?Q Learning提出了一种更新Q值(在某个时刻在状态s下采取动作a的长期回报。)的办法:上面的公式含义就是:现在的Q值=原来的Q值+学习率*(立即回报+Lambda*后继状态的最
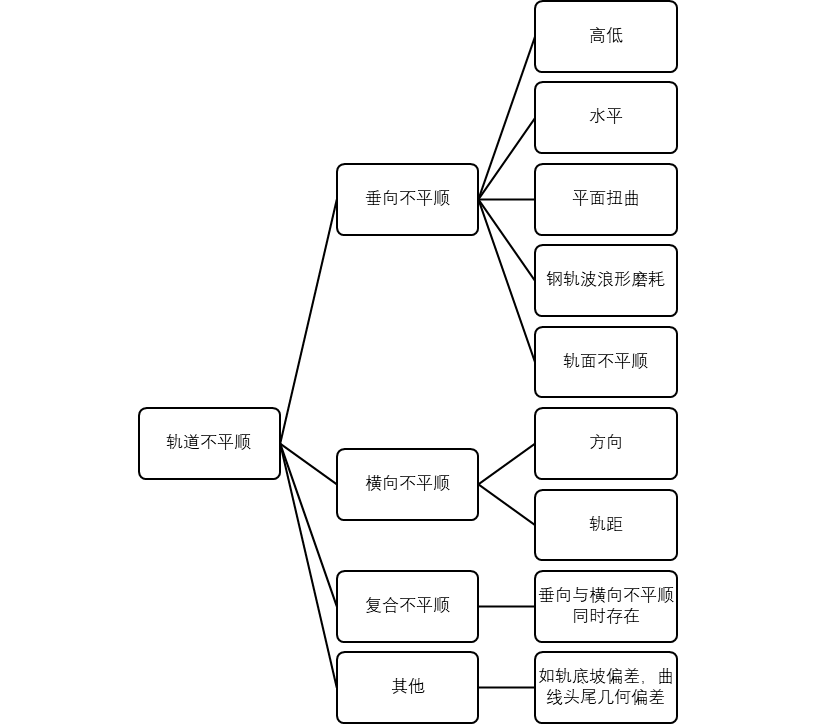
铁路轨道作为铁行车的基础设施,是铁路线路的重要组成部分。随着经济和交通运输业的发展,我国的铁路运输正朝着高速和重载方向迅速发展,与此同时,轨道结构承受来自列车荷载、运行速度的冲击和列车的振动等各方面的作用力不断增大,不仅加速了铁路轨道设备的损坏,由此产生的轨道不平顺问题会严重影响车辆行,乘客的舒适度以及设备的使用寿命等,存在非常严重的安全隐患。在铁路运营过程中,轨道在列车不稳定荷载的反复作用下容易
Apriori是一种常用的数据关联规则挖掘方法,它可以用来找出数据集中频繁出现的数据集合。找出这样的一些频繁集合有利于决策,例如通过找出超市购物车数据的频繁项集,可以更好地设计货架的摆放。Apriori算法的目标是找到最大的K项频繁集。这里有两层意思,首先,我们要找到符合支持度标准(置信度or提升度)的频繁集。但是这样的频繁集可能有很多。第二层意思就是我们要找到最大个数的频繁集。比如我们找到符合支
基于MindSpore实现二次函数的拟合参考:https://blog.csdn.net/baidu_37157624/article/details/117315897注:此为本人智能控制课程作业,可能存在不对的地方请多多指教,搬运的同学请适当修改并表明出处# by YYC#2021.10.05import matplotlib.pyplot as pltfrom mindspore impor
近地面臭氧(O₃)是我国东部经济发达地区最核心的二次大气污染物之一,其形成受气象条件、前体物排放、区域传输等多因素的非线性耦合影响,传统统计模型和化学传输模型(CTMs)分别存在非线性拟合能力不足、计算成本高、不确定性大的痛点。构建了一套「自动化建模-特征解释-因果推断」的完整分析框架。
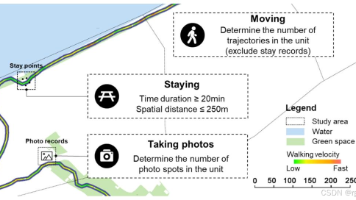
论文摘要用极简的逻辑覆盖了研究缺口-方法路径-核心发现-应用价值研究缺口:现有研究未能基于GPS等高分辨率地理数据,深入挖掘河流廊道内休闲步行的具体行为特征,也未能厘清细分步行行为与建成环境的关联机制。方法创新:基于GIS领域的轨迹语义概念模型,从轨迹数据中挖掘移动、停留、拍照三类核心行为,以广州市中心城区河流廊道为案例,分析其空间分布规律与建成环境影响因素。核心发现河流廊道内休闲步行的移动、停留
在万维网的连接图背后似乎隐藏着大量的随机性。然而,仔细观察就会发现,万维网地图和随机网络之间存在一些令人费解的差异。实际上,在随机网络中,高度连接的节点——枢纽节点,是几乎不可能出现的。相比之下,万维网中同时存在大量度很小的节点和少数几个枢纽节点——拥有链接数异常多的节点。
机器学习(四) 逻辑回归1.什么是逻辑回归逻辑回归(logistic regression)是用于分类的机器学习算法。线性回归的输出是一个数值,而不是一个标签,显然不能直接解决二分类问题。一个最直观的办法就是设定一个阈值,比如0,如果我们预测的数值 y > 0 ,那么属于标签A,反之属于标签B。另一种方法,我们不去直接预测标签,而是去预测标签为A概率,我们知道概率是一个[0,1]区间的连续数