




- @weixin_44018458
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
markdown 存储图片的几种方式方式一:使用base64编码图片转Base64:https://www.beejson.com/encryption/imagebase64.htmlmarkdown 格式如下# 格式![avatar][base64str]# 例如:try:r = requests.get(url)r.raise_for_status()r
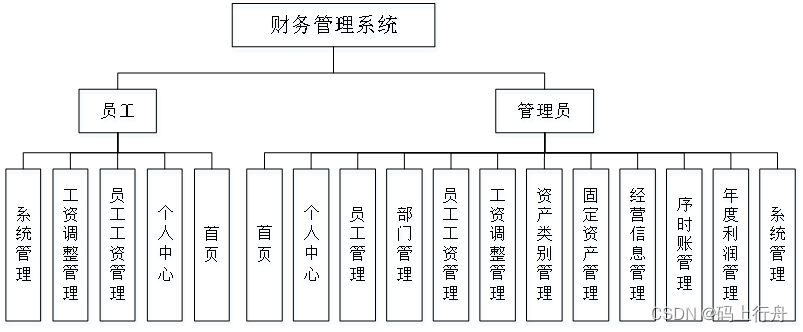
财务管理系统的开发运用java技术、springboot框架,MIS的总体思想,以及Mysql等技术的支持下共同完成了该系统的开发,实现了财务管理的信息化,使员工体验到更优秀的财务管理,管理员管理操作将更加方便,实现目标。主要对首页,个人中心,员工管理,部门管理,员工工资管理,工资调整管理,资产类别管理,固定资产管理,经营信息管理,序时账管理,年度利润管理,系统管理的实现。
通过编写Spark程序清洗酒店数据里的缺失数据、非法数据、重复数据。
从Spark 2.0开始,DataFrame与Dataset合并,每个Dataset也有一个被称为一个DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。Dataset是在Spark1.6中添加的新的接口,是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。DataFrame 其实是
数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。
本人使用的虚拟机未遇到此问题版本为:VMware 15安装 VMware Tools点击虚拟机选择 安装 VMware Tools把压缩包复制到桌面或其它位置解压文件得到 vmware-tools-distrib 文件夹cd ~/Desktopsudo tar -zxvf VMwareTools-10.0.6-3595377.tar.gz执行 vmware-install.pl 文件sudo ./
文章目录Hadoop 相关软件及版本虚拟机参数配置准备工作分布式模式配置错误Hadoop 相关软件及版本软件版本Linux OSubuntu-20.04.1JDKjdk-8u261-linux-x64VMware15.5.6Hadoophadoop-2.7.7虚拟机参数配置master:1.5G ~ 4G 内存、20G 硬盘、NAT、1 ~ 4 核slave1 ~ slave2:1G 内存、20G