




- @weixin_43869610
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
博主今天遇到下面这个问题,也是苦恼了很久,最后总算是找到解决方法了。把hander-chain.xml复制到对应项目到targrt下面所对应的包,这样将能运行了,不会报错误了,可能是编译器不会去解析xml文件,而解析了java文件。因此缺失了xml文件。...
摘要: 聚类是针对给定的样本,依据它们特征的相似度或距离,将其归并到若干个“类”或“簇”的数据分析问题。一个类是样本的一个子集。直观上,相似的样本聚集在相同的类,不相似的样本分散在不同的类。这里,样本之间的相似度或距离起着重要作用。聚类的基本概念首先定义一个矩阵X用来表示n个样本的m个属性。X=[xij]m×n=[x11x12⋯x1nx21x22⋯x2n⋮⋮⋮xm1xm2⋯xmn]X = [x_{
11.1 概率无向图模型11.1.1 模型定义式子(11.3)推导补充P(Yv,YO∣YW)=P(Yv∣YW,YO)P(YO∣YW)=P(Yv∣YW)P(YO∣YW)\begin{aligned}P(Y_v,Y_O|Y_W)&=P(Y_v|Y_W,Y_O)P(Y_O|Y_W)\\&=P(Y_v|Y_W)P(Y_O|Y_W)\end{aligned}P(Yv,YO∣YW)=P
第一章 特征工程01 特征归一化Q:为什么需要对数值类型的特征做归一化?A:对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下两种。线性函数归一化Xnorm=X−XminXmax−XminX_{norm} = \frac{X-X_{min}}{X_{max}-X_{min}}Xnorm=Xmax−XminX−Xmin其中X为原始数据,Xm
title: 统计学习方法——EM算法及其推广mathjax: truedate: 2020-09-02 16:38:15tags: 统计学习方法categories: 算法1、摘要EM算法是一种迭代算法,1977年由Dempster等人总结提出,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计。EM算法的每次迭代由两步组成:E步,求期望(expec
式子(16.3)和(16.4)的推导由式子(16.2)和Σ=cov(x,x)=E[(x−μ)(x−μ)T]\Sigma=\operatorname{cov}(\boldsymbol{x}, \boldsymbol{x})=E\left[(\boldsymbol{x}-\boldsymbol{\mu})(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}}\r
摘要: 条件随机场(Conditional Random Field,CRF)是自然语言处理的基础模型,广泛应用于中文分词、命名实体识别、词性标注等标注场景。下面通过一个小问题来引入: 假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上
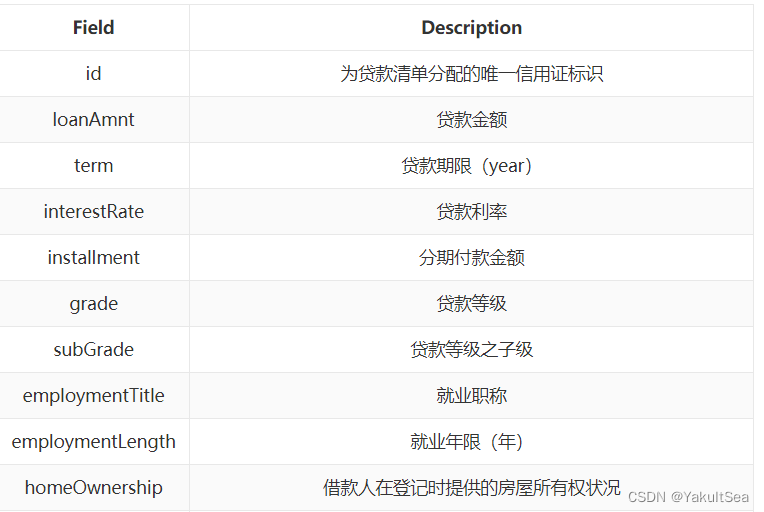
**摘要:**赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。赛题以预测用户贷款是否违约为任务,数据集报名后可见并可下载,该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测
摘要: 隐马尔可夫模型(hidden Markov model,HMM)是可用于标注问题的统计学习模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。隐马尔可夫模型在语音识别,自然语言处理,生物信息,模式识别等领域有着广泛的应用。1、马尔科夫模型与HMM 要讲隐马尔科夫模型,需要先从马尔科夫模型讲起。已知N个有序随机变量,根据贝叶斯定理,他们的联合分布可以写成条件分布的连乘积:P(