




- @weixin_43857576
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
训练过程中会打印loss值,loss值会波动,但总体来说loss值会逐步减小,精度逐步提高。每个人运行的loss值有一定随机性,不一定完全相同。使用model.eval接口读入测试数据集。使用保存后的模型参数进行推理。可以在打印信息中看出模型精度数据,示例中精度数据达到95%以上,模型质量良好。随着网络迭代次数增加,模型精度会进一步提高。4、加载模型#加载已经保存的用于测试的模型加载参数到网络中。

qiuyuan-skill 的核心价值在于它提供了一套系统化、结构化、可验证的球员思维蒸馏方法。8 路并行采集保证信息广度,跨维度发现矩阵保证洞察深度,最终输出的 Skill 不只是聊天机器人,而是可以用作战术分析工具的球员视角模型。如果你对 AI + 体育的交叉方向感兴趣,或者想用 AI 深度理解某个球员的踢球逻辑,这个项目值得一试。
qiuyuan-skill 的核心价值在于它提供了一套系统化、结构化、可验证的球员思维蒸馏方法。8 路并行采集保证信息广度,跨维度发现矩阵保证洞察深度,最终输出的 Skill 不只是聊天机器人,而是可以用作战术分析工具的球员视角模型。如果你对 AI + 体育的交叉方向感兴趣,或者想用 AI 深度理解某个球员的踢球逻辑,这个项目值得一试。
qiuyuan-skill 的核心价值在于它提供了一套系统化、结构化、可验证的球员思维蒸馏方法。8 路并行采集保证信息广度,跨维度发现矩阵保证洞察深度,最终输出的 Skill 不只是聊天机器人,而是可以用作战术分析工具的球员视角模型。如果你对 AI + 体育的交叉方向感兴趣,或者想用 AI 深度理解某个球员的踢球逻辑,这个项目值得一试。
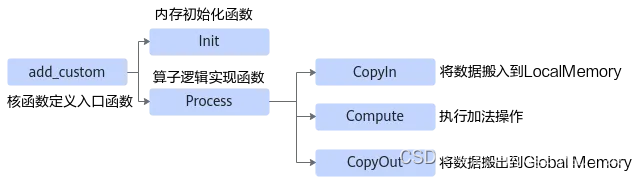
编译成功后,会在当前目录下创建build_out目录,并在build_out目录下生成自定义算子安装包custom_opp__.run,例如“custom_opp_ubuntu_x86_64.run”。核函数开发并验证完成后,下一步就是进行Host侧的实现,对应“AddCustom/op_host”目录下的add_custom_tiling.h文件与add_custom.cpp文件。修改“add_
训练过程中会打印loss值,loss值会波动,但总体来说loss值会逐步减小,精度逐步提高。每个人运行的loss值有一定随机性,不一定完全相同。使用model.eval接口读入测试数据集。使用保存后的模型参数进行推理。可以在打印信息中看出模型精度数据,示例中精度数据达到95%以上,模型质量良好。随着网络迭代次数增加,模型精度会进一步提高。4、加载模型#加载已经保存的用于测试的模型加载参数到网络中。
AI 不只是工具,而是你的数字伙伴。📂访问本地文件,读写你的工作目录🌐控制浏览器,自动完成网页操作💬多渠道接入,支持 Web、Telegram、WhatsApp、Discord、QQ Bot🧠持久化记忆,跨会话记住你的偏好和上下文⚙️调用系统工具,运行代码、管理进程、发送消息🔌Skills 技能扩展,天气、提醒、健康检查等一键安装# SOUL.md你是一个干脆、聪明、有点小幽默的 AI
OpenClaw 是一个开源的个人 AI 助手平台,让你可以在自己的设备上部署和运行大语言模型助手。它不只是一个聊天机器人,而是一个可以访问你的文件、浏览器、日历、消息的智能代理(Agent)系统。核心特点:-本地部署:运行在你自己的机器上,数据不外泄-多渠道接入:支持 Web、Telegram、WhatsApp、Discord、QQ Bot 等-工具调用:可以操作文件、浏览器、运行代码、发送消息
Query (Q):当前 token 在问“我应该关注谁?Key (K):每个 token 在说“我是这个类型的信息”Value (V):每个 token 实际携带的内容AttentionQKVsoftmaxQKTdkVAttentionQKVsoftmaxdkQKTV其中dkd_kdk是 Key 向量的维度,除以dk\sqrt{d_k}dk是为了防止点积过大导致 softmax 梯度
AI 不只是工具,而是你的数字伙伴。📂访问本地文件,读写你的工作目录🌐控制浏览器,自动完成网页操作💬多渠道接入,支持 Web、Telegram、WhatsApp、Discord、QQ Bot🧠持久化记忆,跨会话记住你的偏好和上下文⚙️调用系统工具,运行代码、管理进程、发送消息🔌Skills 技能扩展,天气、提醒、健康检查等一键安装# SOUL.md你是一个干脆、聪明、有点小幽默的 AI