- @weixin_43719763
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍在WSL2环境下通过离线安装方式解决Docker安装过程中的网络问题。提供了具体步骤,并对安装后的环境进行了简单验证。
文章主要分享了C++和python面试中常见的算法题目与实现方法。首先介绍了变量交换的三种方式:值传递、指针传递和引用传递,并通过模板实现了通用类型交换函数。随后讲解了字符串复制操作的注意事项。第二部分重点讲解排序算法,包括冒泡排序的实现和快速排序的分治思想。
本文通过地平线OE工具链在PC端的量化与精度实验,完成了模型上板子前的所有准备工作,从模型量化到算子适配性检查,再到编译生成在地平线计算平台上加载运行的模型,最后通过手写脚本,生成评估所需的数据集,并顺利完成评估工作,经评估,模型精度也符合部署要求。

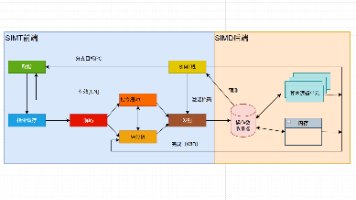
深入解析GPU指令流水线的工作原理及其在AI计算中的关键作用。GPU流水线包含SIMT前端和SIMD后端,分为取指、译码、发射、执行、写回五个阶段。SIMT前端支持线程级编程,SIMD后端实现数据并行处理。还详细探讨了流水线各阶段的工作机制,以及数据冒险、结构冒险和控制冒险的发生原因等。
本文基于YOLOv8模型和COCO128数据集,对比评估了PyTorch、ONNX和TensorRT三种模型格式在计算机视觉任务中的部署性能。实验从精度、速度和资源占用三个维度建立评估指标体系,包括mAP、FPS、显存占用等关键指标。

本篇博客完整实现了 YOLOv8 在 Jetson 平台上的 C++ + TensorRT 端到端单图检测流程,从模型转换(pt→onnx→engine)、工程搭建、核心推理代码编写,到后处理与可视化,全程可复现、可落地。
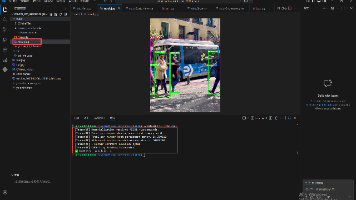
本篇博客完整实现了 YOLOv8 在 Jetson 平台上的 C++ + TensorRT 端到端单图检测流程,从模型转换(pt→onnx→engine)、工程搭建、核心推理代码编写,到后处理与可视化,全程可复现、可落地。
深入解析GPU指令流水线的工作原理及其在AI计算中的关键作用。GPU流水线包含SIMT前端和SIMD后端,分为取指、译码、发射、执行、写回五个阶段。SIMT前端支持线程级编程,SIMD后端实现数据并行处理。还详细探讨了流水线各阶段的工作机制,以及数据冒险、结构冒险和控制冒险的发生原因等。
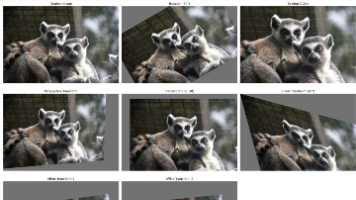
对Ultralytics代码库中数据增强Pipeline的搭建方法进行了简单介绍,同时对数据预处理与增强的实现步骤与实现方法进行了深入讲解。
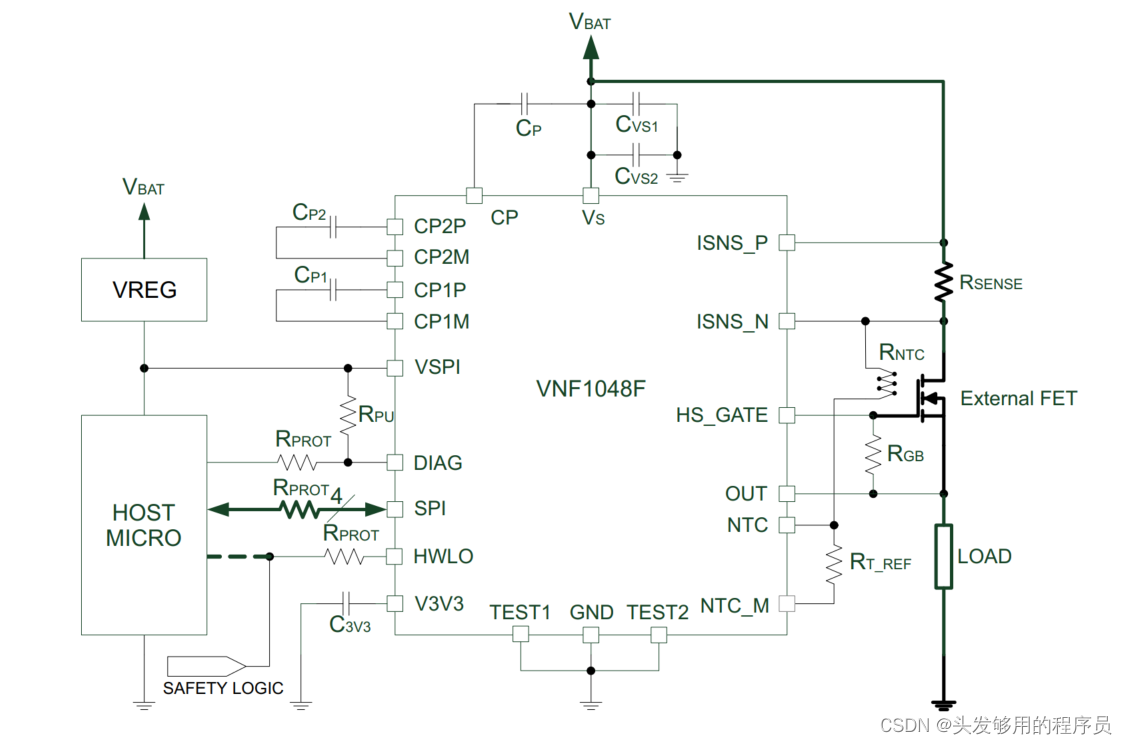
该器件是用于高端配置的功率MOSFET的高级控制器,设计用于实现 12 V、24 V 和48 V 汽车应用。通过 3.3 V 和 5V CMOS 兼容的SPI 接口,实现 IC 与主控制器通信,从而提供保护和系统诊断。