




- @weixin_43712047
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这篇文章探讨了现代智能代理(Agent)的核心架构和工作原理。作者从对话循环(Conversation Loop)的角度,系统性地解释了MCP、Skill和RAG等技术如何协同工作。文章要点如下: Conversation Loop是Agent的核心执行引擎,负责持续执行"LLM决策→工具调用→结果反馈→再决策"的循环过程。 现代Agent架构包含四层:用户层、消息网关层、Agent核心层(含Co
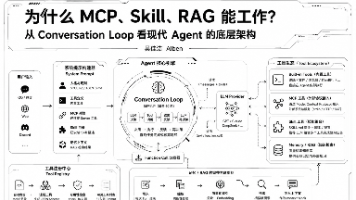
这篇文章探讨了现代智能代理(Agent)的核心架构和工作原理。作者从对话循环(Conversation Loop)的角度,系统性地解释了MCP、Skill和RAG等技术如何协同工作。文章要点如下: Conversation Loop是Agent的核心执行引擎,负责持续执行"LLM决策→工具调用→结果反馈→再决策"的循环过程。 现代Agent架构包含四层:用户层、消息网关层、Agent核心层(含Co
摘要(147字): 2026年3月,Claude Code因npm包中意外包含.map文件导致512,000行TypeScript源码泄露。该文件完整映射了1906个源文件,暴露了其四层架构体系:用户层(CLI/IDE插件)、46,000行的核心编排层、40+工具的门控系统,以及创新的"autoDream"记忆整理引擎。泄露内容显示该系统采用动态拼装的110+条system p

文章摘要: 近年来关于Rust取代Go的讨论愈演愈烈,尤其在AI基础设施领域涌现大量Rust项目。但深入观察会发现,Rust实际抢占的是C++的市场份额,而非Go的基本盘。AI时代已形成清晰的技术分层:Python主导应用层,Go掌控云原生控制面,Rust接管高性能数据面,C++专注GPU计算,C语言坚守底层驱动。Rust以其内存安全和并发优势,正逐步替代C++在系统编程中的传统地位,而Go凭借开

这篇文章记录了作者为cc-switch工具添加Ollama本地模型支持的过程。通过分析现有架构,作者发现只需少量改动即可实现Codex CLI请求从云端转向本地Ollama服务。主要改动包括:在类型系统中新增local分类、添加Ollama预设配置、修复URL端点问题、增加防御机制等。最终仅用5个commit就实现了功能,使本地模型调用延迟降至5ms以下,同时避免了API费用。文章详细展示了请求流
DeepSeek DSpark 提出了一种基于置信度调度的投机解码框架,通过半自回归生成和并行验证机制加速大模型推理。核心技术包括:(1) 并行主干生成所有位置特征,结合 Markov Head 进行局部自回归修正,平衡生成速度与准确性;(2) 置信度调度器动态调整验证窗口大小,避免后缀退化问题;(3) 目标模型一次性并行验证候选序列,显著减少前向计算次数。实验表明,DSpark 在保持输出质量一

摘要: GPU计算能力(Compute Capability)是影响AI模型性能的关键因素,尤其是Ampere架构(8.0)成为行业分水岭。8.0及以上版本支持TF32数据类型、异步内存拷贝(cp.async)和更大的Shared Memory,显著提升Transformer模型的矩阵计算效率,并支持FlashAttention等高性能优化。对比Tesla T4(7.5)、A100(8.0)和RT

文章摘要 本文记录了Hermes系统因消息历史中的非标准字段导致400错误的排查过程。问题根源在于Hermes内部维护的消息历史携带了Codex Responses API专用字段(如call_id、response_item_id)和内部字段(如function.parameters=None),这些字段在转发到严格兼容OpenAI API的网关时触发校验失败。修复方案包括:1)在非Codex

中国AI技术取得重大突破:Kimi发布"注意力残差"(Attention Residuals)创新技术,通过改进传统Transformer架构中的注意力机制,在48B参数模型上实现1.25倍训练效率提升和7.5%科学推理能力提升。该技术通过跨层注意力直连和Softmax加权机制,解决了传统残差连接中的信息衰减问题,使模型能更智能地筛选和利用历史层信息。这一突破不仅提升了Kimi

这篇文章记录了作者为cc-switch工具添加Ollama本地模型支持的过程。通过分析现有架构,作者发现只需少量改动即可实现Codex CLI请求从云端转向本地Ollama服务。主要改动包括:在类型系统中新增local分类、添加Ollama预设配置、修复URL端点问题、增加防御机制等。最终仅用5个commit就实现了功能,使本地模型调用延迟降至5ms以下,同时避免了API费用。文章详细展示了请求流