




- @weixin_43509698
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
根据错误信息,表示 Token 完全无效,无法通过验证。
本文介绍了在Gitee上提交代码的完整流程:首先安装Git工具,然后登录Gitee创建新仓库。创建完成后,根据页面提示在Git Bash中执行相应命令。若遇到认证错误,需在Gitee设置中生成个人访问令牌(需勾选projects权限),并将令牌配置到Git中。最后还提到可以通过分支设置来保护特定分支。文中包含详细的步骤截图和命令行操作指南,帮助用户顺利完成代码提交。
wandb 是一款用于记录机器学习训练数据的工具,通过跟踪可视化从数据集处理到训练输出模型整个流程的各个方面,来帮助用户更快速的优化输出模型。

被adb连接折腾了一晚,使用重装adb、删除5037端口等操作都不行,手机与电脑adb连接常见问题。

wandb 是一款用于记录机器学习训练数据的工具,通过跟踪可视化从数据集处理到训练输出模型整个流程的各个方面,来帮助用户更快速的优化输出模型。
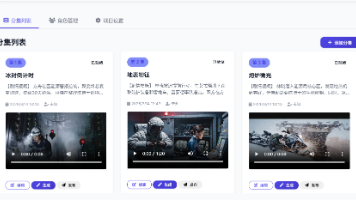
是一个基于AI的短视频智能制作平台,集成了剧本创作、角色管理、场景生成、镜头制作等完整的工作流,帮助创作者快速生成高质量的短视频内容。
随着文本到图 像 (TTI )自动生成的成功 [31-33], 许 多研究人员采用与 前 者类 似的 技术 , 也成 功地 进行了 文 本 到音 频 (TT A )生 成[17,18, 43]。这 样 的 模型 在 媒 体制 作 中 可能 有 很强 的 潜 在价值,因 为 创作者 总是 在 寻找 适 合他 们创 作 的新 颖声 音。这 在 原型 制作 或 小规 模项 目 中尤 其 有用 ,因 为
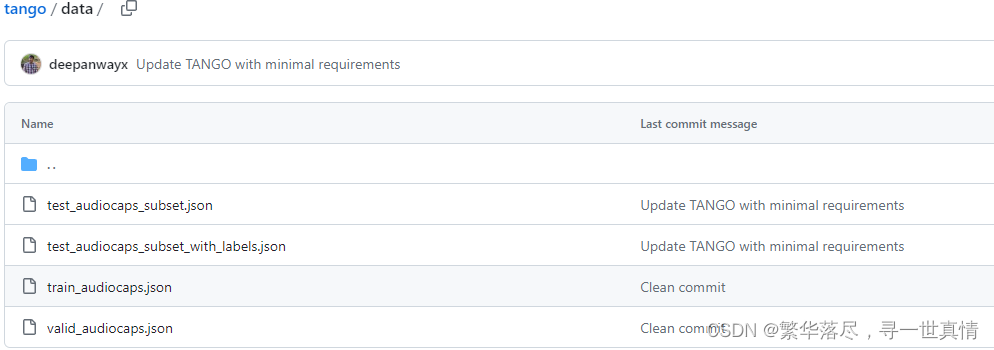
使用制作好的数据集,可以跳过1~3步:https://blog.csdn.net/qq_41941900/article/details/142366183https://github.com/SoccerNet/sn-tracking代码下载:pip install SoccerNet2.提取sn-tracking数据集中只有足球的图片,生成YOLO格式的数据3.将提取的只含有足球的数据集划分训

COCO数据集可视化。
CLUENER2020数据集在。
