




- @u013305783
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OfficeAI 助手是一项专为 Microsoft Office 和 WPS 用户打造的智能办公工具软件,旨在解决多种常见办公问题。无论是在寻找输入“打勾(√)符号”的简便方法,还是要在插入表格前添加文字、选择公式时遇到困难,AI办公助手都能以最便捷的方式提供解决方案。

spark常用的启动方式一、Local(本地模式) Spark单机运行,一般用于开发测试。可以通过Local[N]来设置,其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。spark-submit 和 spark-submit --master local 效果是一样的,同理spark-shell 和 spark-shell --..
一、hive环境准备1、安装hive 按照hive安装步骤安装好hiveCREATE USER 'spark'@'%' IDENTIFIED BY '123456';GRANT all privileges ON hive.* TO 'spark'@'%';flush privileges;2、环境配置 将配置好的hive-site.xml放入$SPARK-HOME/...
使用 Docker Compose 搭建 Redis 集群是一种便捷高效的方法,可以快速地在本地或者测试环境中搭建一个 Redis 集群。以下是详细的步骤,在 Docker 环境中使用 docker-compose 来搭建 Redis 集群。通过上述步骤,我们已经使用 Docker Compose 成功搭建了一个 Redis 集群。这种方式特别适合用于开发和测试环境,因为它的配置简单、部署快速,非

OfficeAI 助手是一项专为 Microsoft Office 和 WPS 用户打造的智能办公工具软件,旨在解决多种常见办公问题。无论是在寻找输入“打勾(√)符号”的简便方法,还是要在插入表格前添加文字、选择公式时遇到困难,AI办公助手都能以最便捷的方式提供解决方案。
使用 Docker Compose 搭建 Redis 集群是一种便捷高效的方法,可以快速地在本地或者测试环境中搭建一个 Redis 集群。以下是详细的步骤,在 Docker 环境中使用 docker-compose 来搭建 Redis 集群。通过上述步骤,我们已经使用 Docker Compose 成功搭建了一个 Redis 集群。这种方式特别适合用于开发和测试环境,因为它的配置简单、部署快速,非
OfficeAI 助手是一项专为 Microsoft Office 和 WPS 用户打造的智能办公工具软件,旨在解决多种常见办公问题。无论是在寻找输入“打勾(√)符号”的简便方法,还是要在插入表格前添加文字、选择公式时遇到困难,AI办公助手都能以最便捷的方式提供解决方案。
DeepSeek模型微调训练

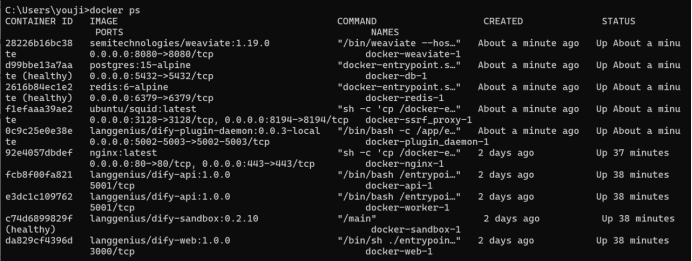
dify 通过本地源码的方式启动
(一)、对象的创建 虚拟机遇到一条new指令时,首先检查这个指令的参数是否有能在常量池中定位到一个类的符号引用,并检查这个符号引用代表的类是否已被加载、解析和初始化过,如果没有,那必须先执行相应得类加载过程 类加载检查通过后,接下来虚拟机将为新生对象分配内存,对象所需内存大小在类加载完成后便可以确定。两种方式:指针碰撞和空闲列表。使用Serial、ParNew等带Compact过程...