- @u012723183
简介
资深技术经理 & AI大模型全栈工程师 9年Java技术纵深 | 2年AI工程化落地 | 大型项目管理专家
擅长的技术栈
可提供的服务
大模型应用开发,大模型训练或微调,Agent 开发,软件研发
DeepSeek-V4 在 2026 年 4 月的一个普通周五低调发布,体现了“率道而行”的理念。其核心特点如下:• 双版本发布:V4-Pro 对标顶级闭源模型,V4-Flash 主打高性价比,均支持百万上下文及可调节的思考模式。• 性能突破:在 Agent 能力、世界知识、推理性能等方面达到开源模型顶尖水平,内部已替代 Claude 作为日常编码助手。• 技术创新:通过全新的注意力机制显著降低了

本文聚焦AICoding工具在企业应用中的安全风险与应对策略,提出在安全可控前提下最大化AI编程提效价值。报告将工具生态分为五类,指出代码上传云端是核心风险来源,并针对源码泄露、恶意代码生成等风险提出分级解决方案:新项目推荐直接采用企业版CodingPlan,老项目采取有限接入策略,堡垒机环境则需私有化部署或专线方案。强调AI生成代码须经严格审查流程,建议分三阶段推进:先试点验证、再评估扩展、最终

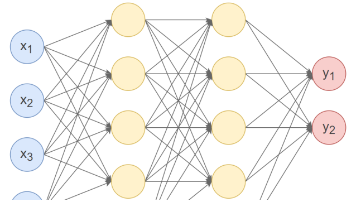
本文通过一个三层神经网络示例(3输入、2输出、2隐藏层)演示了模型参数量的计算方法。第一层包含3×4=12权重和4偏置,共16参数;第二层4×4=16权重加4偏置,共20参数;输出层4×2=8权重加2偏置,共10参数,总计46个参数。参数数量由各层神经元连接数(权重)和偏置项决定,其中权重数量=输入维度×输出维度,偏置数量=输出维度。文中还展示了使用PyTorch查看参数的具体代码,包括权重初始化
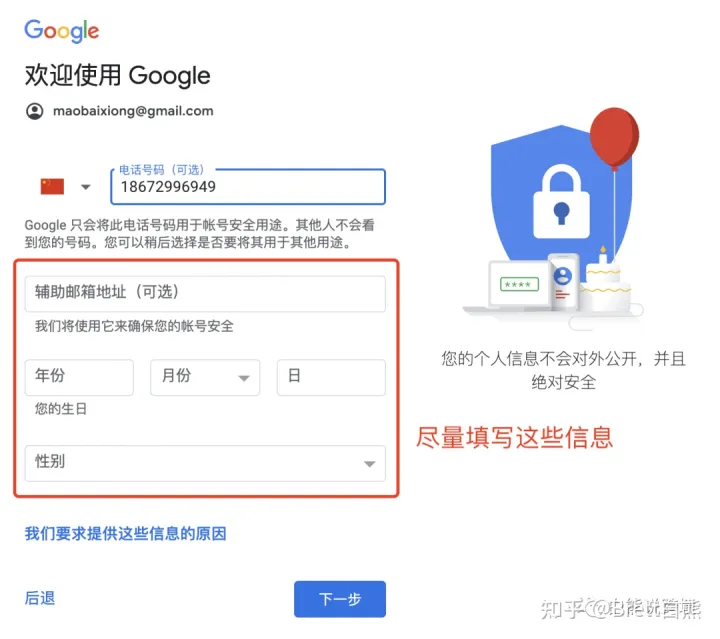
超详细步骤,教你一次就成功注册Gmail邮箱(同时可以用于申请谷歌广告账户)
用 AI 5分钟搞定Java EasyExcel 针对 WPS Excel 单元格嵌入图片的读取。

Application Web 的 Java EE 插件法,但是现在已经没有这个选项了,大家如果有老版本 IDEA 可以试试。2、项目根目录处右键,然后点击 EasyWSDL-Add web service。3、首次使用,会提示登录,就是第一步咱们注册的账号密码,输入点击 ok 即可。然后选中你要生成的 wsdl(也可以默认项目根生成全部)注册完,先等等,我们先准备 wsdl 配置文件到项目中。1

本文详细介绍了LangChain框架及其在大模型应用开发中的核心功能。主要内容包括: LangChain概述:介绍1.0版本的重要更新,定位为连接大模型与外部组件的开发框架,支持Agent、RAG等应用开发。 核心组件: Model I/O:标准化模型输入输出,包含提示模板、模型调用和输出解析 Chains:通过LCEL表达式语言组合工作流 Retrieval:实现RAG流程,包括文档加载、切分、

1. 报错背景tomcat + Oracle + Druid连接池后台报错(java.sql.SQLException: 违反协议),很奇怪的是只有某种特殊情况下才报错,项目其他功能都运转正常,报错信息看最后面代码示例。2. 可能原因(OALL8-jdbc与Oracle驱动版本不一致)1、jdbc配置出错(驱动配置):oracle.jdbc.OracleDriver...
摘要:传统知识管理工具因维护成本高而难以持续,LLMWiki通过AI自动化解决了这一痛点。该模式由Andrej Karpathy提出,采用三层架构:原始资料层、AI维护的知识层和配置层。AI负责内容整理、交叉引用等繁琐工作,用户只需专注知识筛选和提问。国内开发者已将其封装为可复用的llm-wiki技能,支持快速部署。这一方案实现了知识的复利积累,适用于个人学习、团队协作等多种场景,让知识管理真正可

这篇报告覆盖了 8 大类、30+ 款AI 编程相关工具,包括:日常 Chat 工具:豆包、DeepSeek、Kimi、通义千问怎么选?IDE/插件:Cursor、Trae、CodeBuddy、Qoder、Lingma各有什么坑?CLI:Claude Code 真的值得用吗?编程大模型:选模型到底怎么选?Coding Plan:怎么花最少的钱,用最强的模型?AI Coding 实战与成本 ROI 计