- @u011047968
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
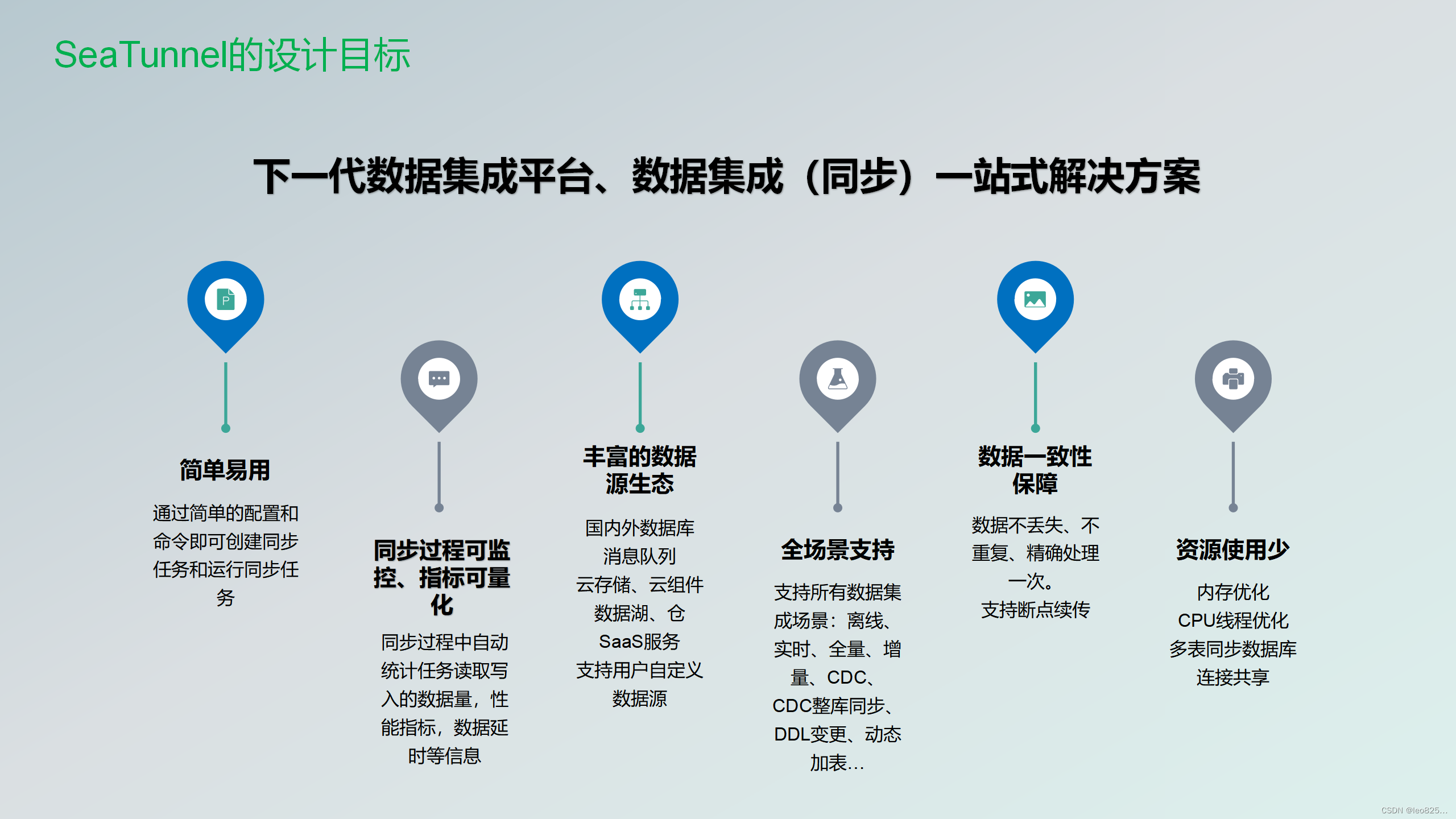
Apache SeaTunnel作为下一代数据集成平台。同时也是数据集成一站式的解决方案,有下面这么几个特点。丰富且可扩展的Connector:SeaTunnel提供了不依赖于特定执行引擎的Connector API。基于该API开发的Connector(Source、Transform、Sink)可以运行在很多不同的引擎上,例如目前支持的SeaTunnel Engine、Flink、Spark等
当需要对一组数据库表(或函数等)的并发数进行单独控制时,需要对这些表(或函数等)放入一个新建的 database 中,PostgreSQL 对最大并发访问会话进行单独控制的最小单元是 database。其中的层级关系是:数据库-模式-对象。需要注意的是,虽然能创建多个数据库实例,但不能同时访问不同数据库中的对象,当需要访问另一个数据库中的表或其他对象时,需要重新连接到这个数据库,而模式却没有此限制

本文介绍了Claude code的热门快捷指令分类清单,包含上下文控制、回退与实验、质量审查、模型与成本控制、自动化与远程协作五大类指令。每类指令配有对应的图示说明,并提供了官方热门指令清单的参考截图。文末附有Claude Code官网地址和相关攻略文章的参考链接,为用户提供更全面的使用指南。这些快捷指令可以帮助开发者更高效地使用Claude code进行开发工作。
公司最小的信息颗粒是 Token;老板 AI大模型 通过 Prompt 听汇报做决策;公司规定所有业务系统必须按 MCP 标准接入;HR 给员工发 Skill 手册;单个 Agent 员工领命干活;遇到大项目就组个 多智能体 团队;OpenClaw 是统一办公平台,Claude Code 是驻场码农;公司终极目标是让这些数字员工拥有身体,变成 具身智能 走进现实世界。
Claude Code Skills 摘要 Claude Code Skills 是一个包含90多项技能的开发工具集,主要分为八大类: 流程类:涵盖完整开发工作流,包括头脑风暴、计划编写、代码审查等15项核心技能 语言/框架类:支持Python、Go、Rust、Java/Kotlin、C++、C#、PHP、Dart等主流语言的编码模式和测试技能 前端/设计类:包含前端开发、UI/UX设计、算法艺术
当需要对一组数据库表(或函数等)的并发数进行单独控制时,需要对这些表(或函数等)放入一个新建的 database 中,PostgreSQL 对最大并发访问会话进行单独控制的最小单元是 database。其中的层级关系是:数据库-模式-对象。需要注意的是,虽然能创建多个数据库实例,但不能同时访问不同数据库中的对象,当需要访问另一个数据库中的表或其他对象时,需要重新连接到这个数据库,而模式却没有此限制
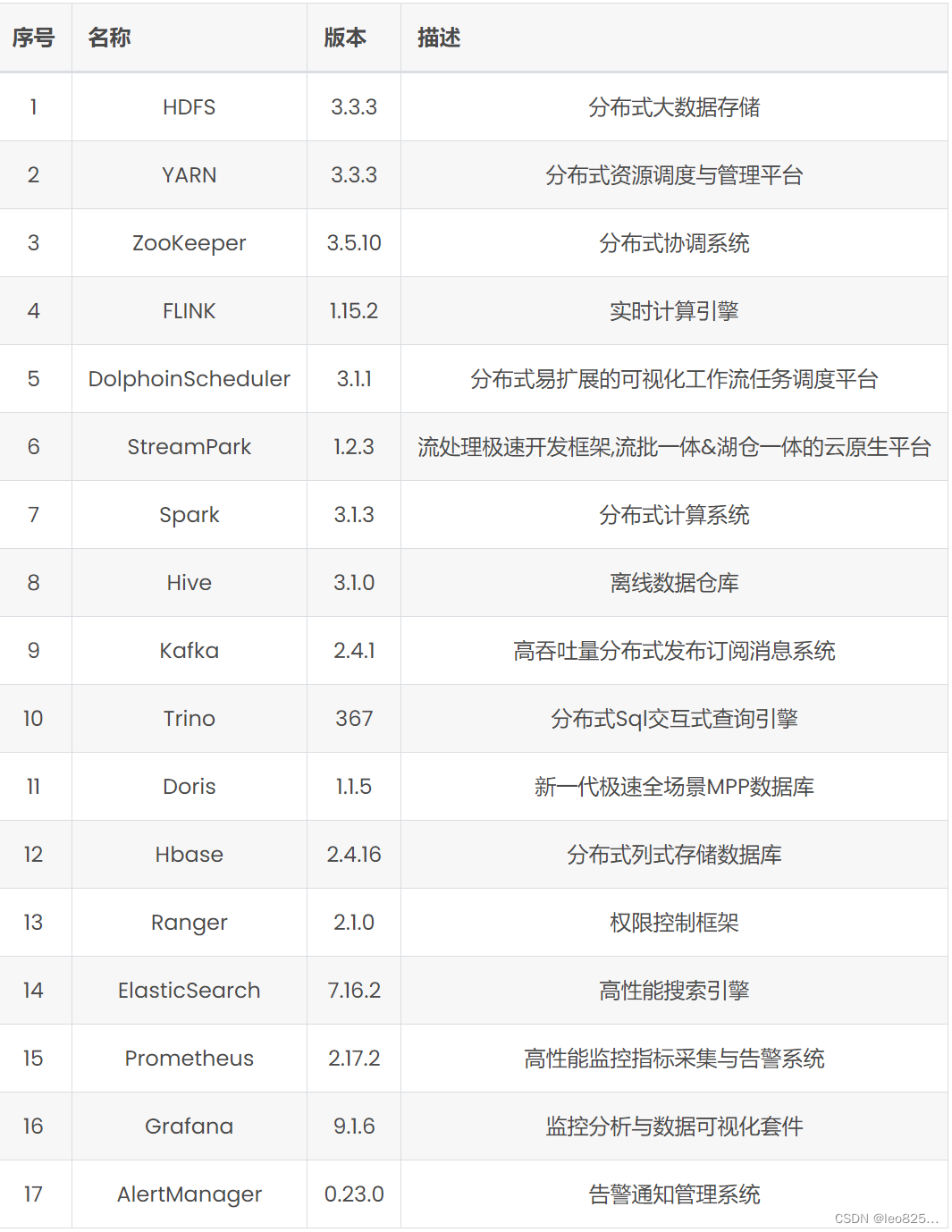
文章目录1、概念1.1、主从结构1.2、Hadoop集群角色名称2、安装前准备2.1、安装软件准备2.2、Hadoop集群服务器规划3、安装3.1 解压文件3.2 修改配置文件3.2.1.修改`hadoop-env.sh`配置3.2.2.修改`core-site.xml`配置3.2.3.修改`hdfs-site.xml`配置3.2.4.修改`mapred-site.xml`配置3.2.5.修改`y
公司最小的信息颗粒是 Token;老板 AI大模型 通过 Prompt 听汇报做决策;公司规定所有业务系统必须按 MCP 标准接入;HR 给员工发 Skill 手册;单个 Agent 员工领命干活;遇到大项目就组个 多智能体 团队;OpenClaw 是统一办公平台,Claude Code 是驻场码农;公司终极目标是让这些数字员工拥有身体,变成 具身智能 走进现实世界。
DataSophon也是个类似的管理平台,只不过与智子不同的是,智子的目的是锁死人类的基础科学阻碍人类技术爆炸,而DataSophon是致力于自动化监控、运维、管理大数据基础组件和节点的,帮助您快速构建起稳定,高效的大数据集群服务。
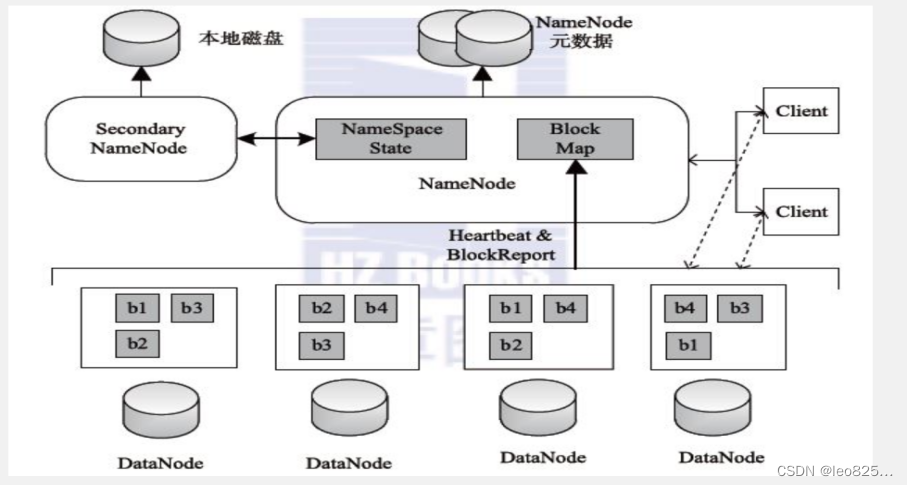
HDFS 全称是 Hadoop Distribute File System,翻译过来就是 Hadoop 分布式文件系统