




- @ting4937
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近改了下依赖包版本,编译启动没啥问题,但调接口的时候报错了遇到这种问题一般都是依赖包版本冲突造成的。

有时候,我们想比对两个word文档,标记出两个文档之间的差异,这样一眼就能看出来修改了哪些地方,如下图,左边文档中的扩招2000人删除了,辞呈改成了说明,新增了并且加重处罚等文字,是否一目了然了。

登录校验功能是每个项目都必须的功能,常见的登陆校验方式有JWT和session.JWT的优点是无状态,缺点很多,明文传输,无法提前终止,字段过长。所以我们采用JWT加session的方式。JWT中只存放随机生成的token,再通过token去redis中找用户信息。当然也可以直接传token,就是安全性比放JWT中差一点。第一步,登录完成随机生成token,把用户信息放入redis中public
要比较word文档内容,我们需要先读取word文档,这里使用poi库,至于比较内容,可以使用apache的commons-text库。
需要用到json_contains函数,第一个参数是表的字段名,第二个参数是要查询的值,如果是字符串需要用双引号,第三个参数是path路径。查询语句跟普通的sql语句差不多,也就是字段名要用到path表达式。

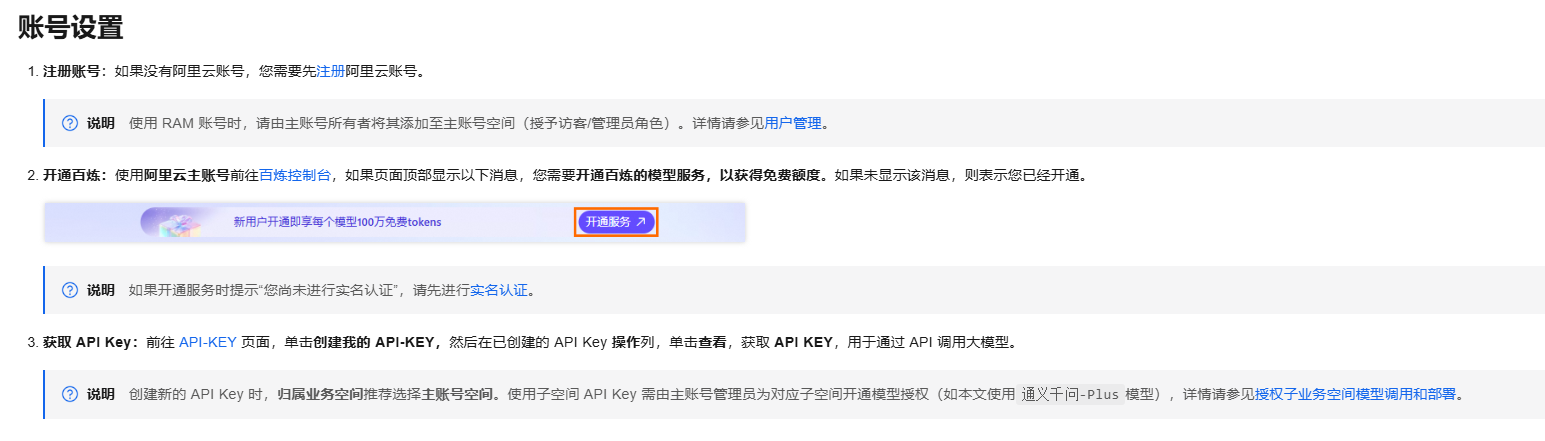
阿里云百炼文档地址: 百炼控制台 首先跟着文档设置账号,新建一个api key文档地址: 百炼控制台你可以使用sdk来对接,但没有必要,因为所有接口对接都是http形式的,直接使用http库来对接就行了,使用http库还有一个好处是所有大模型的调用方式是想通的,你想换一个模型调用会非常方便,这里我使用okhttp库,下面的okhttp-sse库是非必须的,只有使用流式传输的时候需要我们来对接一个最
摘要: OnlyOffice是一款开源办公套件,支持Word、Excel等文档的在线编辑与实时协作,具备AI辅助、跨平台协同及三级加密等功能。其优势在于开源定制、高效集成(40+平台)、字符级协同及全场景覆盖,适合企业私有化部署。通过Docker可快速部署OnlyOffice文档服务,仅需拉取镜像并配置端口即可运行。与SpringBoot集成时,需实现文档配置、下载及回调接口,前端通过JavaSc
现在开发的软件要进入国有机构,需要进行信创适配,我们先来了解下什么叫信创适配是 “信息技术应用创新适配” 的简称,是指在信息技术领域(IT 领域)中,通过对等各个层面的产品进行兼容性测试和优化调整,确保不同厂商的产品能够协同工作,形成完整、安全、可控的信息技术生态体系。信创适配是一项系统性工程,需要政策引导、技术创新、生态协同和行业实践共同推进。随着信创产业的快速发展,国产化适配将成为各行业数字化
本文介绍了如何在达梦数据库中实现MySQL的GROUP_CONCAT函数。由于达梦数据库原生不支持该函数但提供类似功能的LISTAGG,当项目需要同时兼容两种数据库时,可以通过创建自定义聚合函数来解决。具体实现步骤包括:1)创建GROUP_CONCAT_TYPE聚合类型;2)实现类型体完成初始化、迭代、终止和合并操作;3)创建GROUP_CONCAT聚合函数;4)建立公共匿名函数以便其他用户使用。
前言上一篇中介绍了决策树模型的基本使用,这篇来讲解下如何调参。首先我们来谈谈如何提升预测的准确性,第一步当然是选择正确的模型了,在学习机器学习算法的过程中,我们需要知道每个模型的特点,它擅长什么样的数据集,不擅长什么样的数据集,但有时候我们对数据集的分布并不是很清楚,这个时候就需要一个个尝试了。第二步就是特征工程,sklearn当中的数据集往往很完美,没有缺失数据,但现实中的数据集有很多的问题,需
