




- @syu_acm
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Transformer 结构和 LSTM 的区别和优势,Transformer 怎么体现时序信息?Bert 用的什么位置编码,为什么要用正弦余弦来做位置编码?还知道其他哪些位置编码?Transformer Encoder 和 Decoder 的输入输出和结构。Attention 和 self-attention 有什么区别?为什么现在的大模型大多是 decoder-only 的架构?简单介绍一下

对于所有的相关经历,都是跟面试官聊技术(举例,提供参考方向)从数据规模、特征、指标、目前使用的模型方法、项目难点详细介绍。
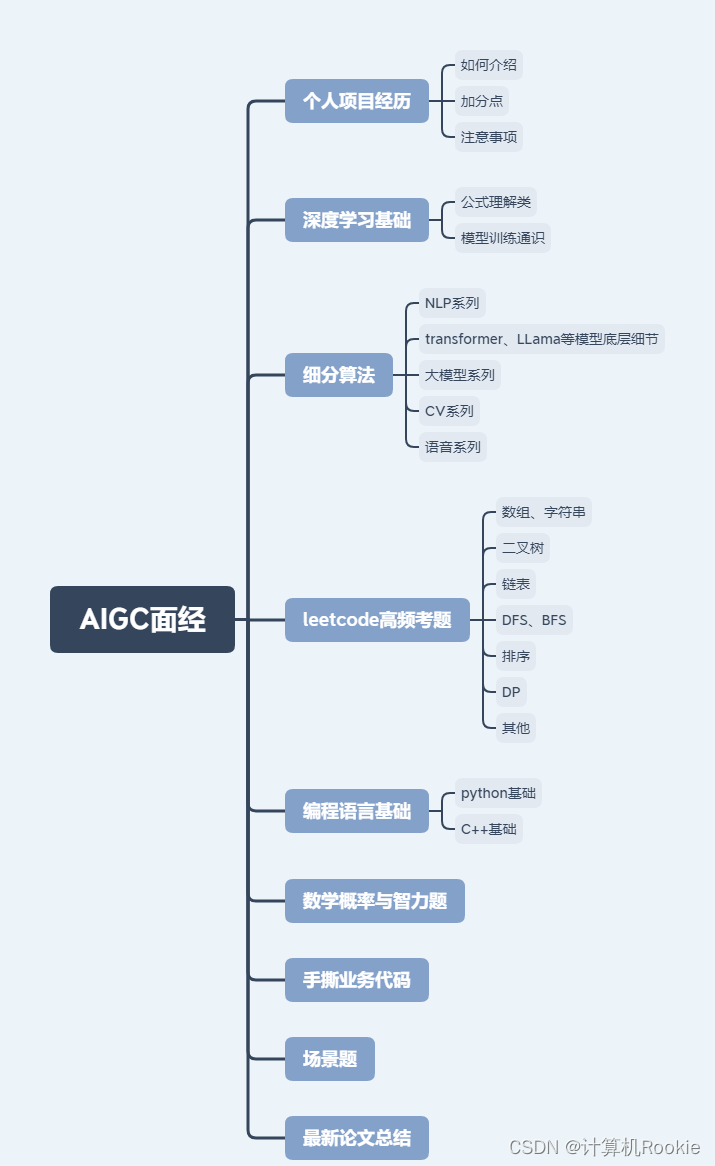
本教程内含YOLOv11网络结构图+训练教程+推理教程+数据集获取等有关的内容~

Transformer 结构和 LSTM 的区别和优势,Transformer 怎么体现时序信息?Bert 用的什么位置编码,为什么要用正弦余弦来做位置编码?还知道其他哪些位置编码?Transformer Encoder 和 Decoder 的输入输出和结构。Attention 和 self-attention 有什么区别?为什么现在的大模型大多是 decoder-only 的架构?简单介绍一下
在将已有项目提交到线上远程仓库时,报错[rejected] master -> master (fetch first) error: failed to push some refs

报错信息:报错原因:writer.add_scalar要加“S”
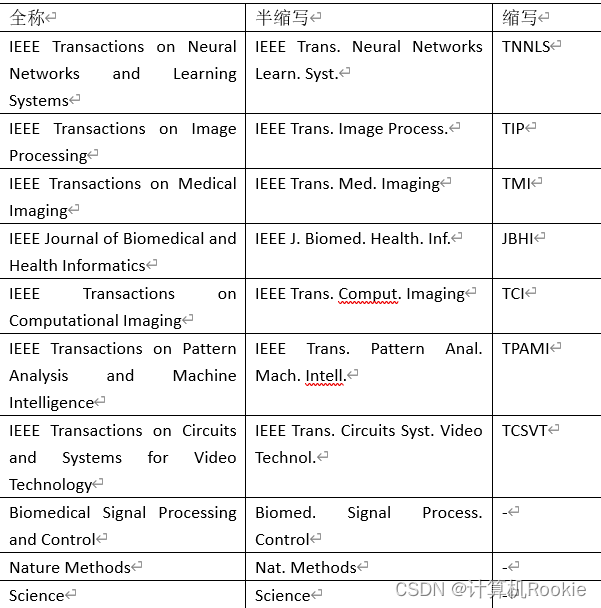
计算机常见期刊半缩写和缩写(投稿)
Transformer 结构和 LSTM 的区别和优势,Transformer 怎么体现时序信息?Bert 用的什么位置编码,为什么要用正弦余弦来做位置编码?还知道其他哪些位置编码?Transformer Encoder 和 Decoder 的输入输出和结构。Attention 和 self-attention 有什么区别?为什么现在的大模型大多是 decoder-only 的架构?简单介绍一下
【代码】最新版anaconda的activate命令激活环境报错 usage: conda-script.py [-h] [--no-plugins] [-V] COMMAND ...
