




- @saynaihe
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本次操作通过创建快照、创建新硬盘和使用rclone同步数据三个步骤,成功地解决了腾讯云CentOS 6中的/data目录硬盘空间不足的问题。现在您不仅拥有了更大的存储空间,还学会了使用rclone维持软链接的方法。根据上述方法,您可以安全地扩展您的服务器存储,并确保业务的连续性和数据的安全性。
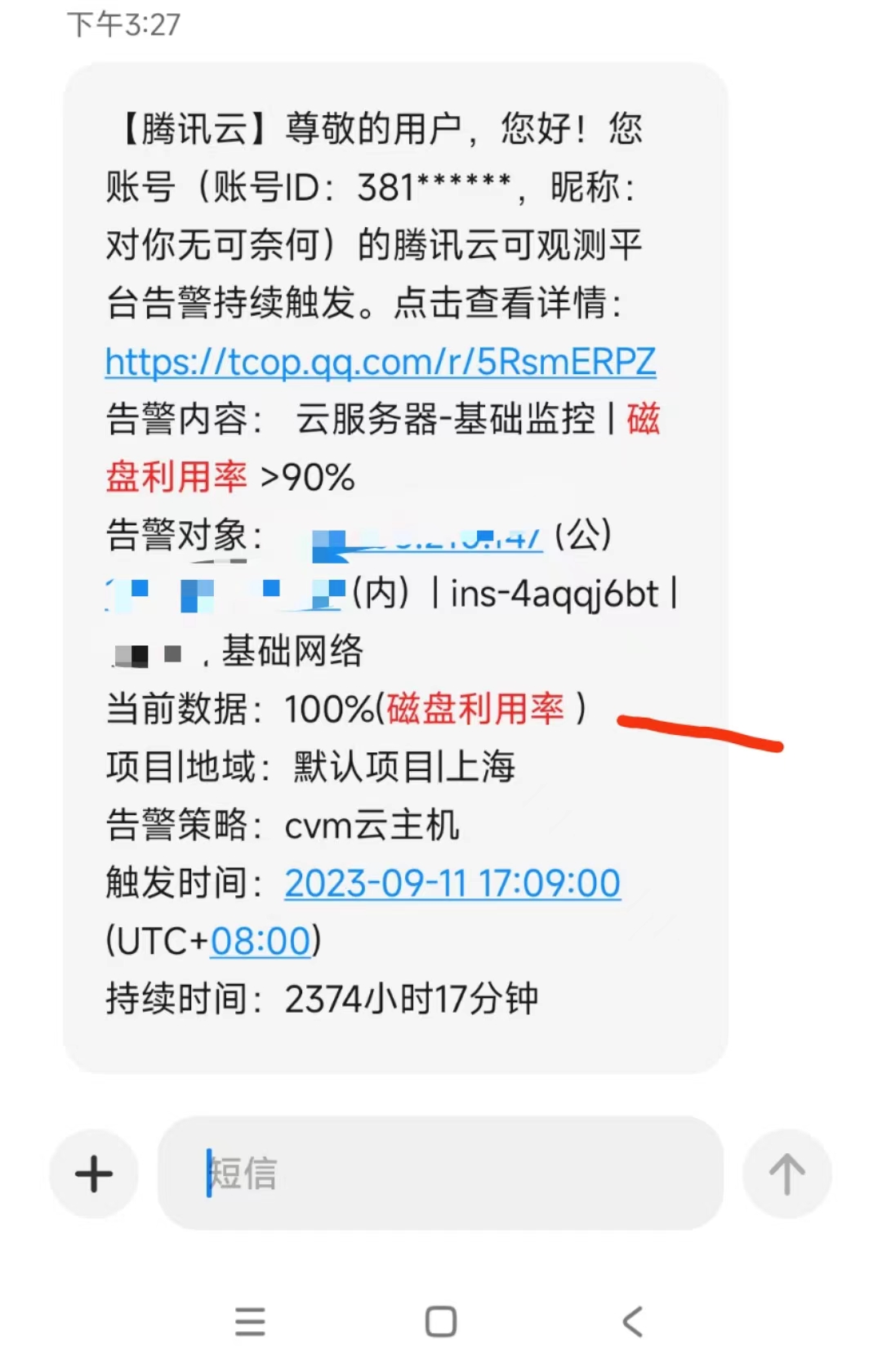
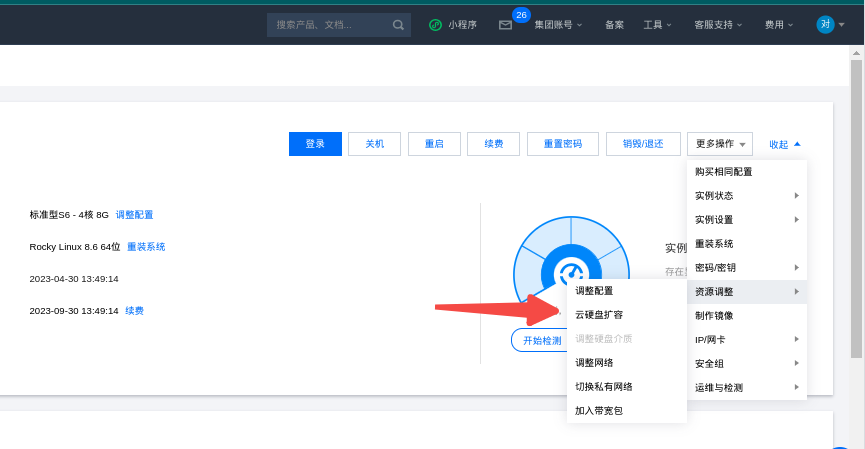
过去一直记得腾讯云的系统盘扩容,关于系统盘的扩容直接点资源调整-云硬盘扩容系统盘扩容后就可以直接使用的?但是现在操作了发现vda 200G 但是现在vda1不能自动扩容了?
基础镜像还是使用官方镜像…升级过程以官方推荐路线为准要经常更新升级版本,起码跟着大版本,不要落后主线版本太多,像是为这升级各种流程操作差不多用了两天时间。其他关于本版本gitlab操作可以参考。

背景:是这样的一个事情:服务运行于kubernetes集群(腾讯云tke1.20.6)。日志采集到了elasticsearch集群and腾讯的cls日志服务中。小伙伴看日志觉得还是不太方便,还是想看控制台输出的。给他们分配过一台服务器(加入到集群中,但是有污点标签的节点)。为了方便他们测试一下东西。现在想让他们通过此work节点可以在控制台查看日志。正常的就是把master节点的/root/.ku
背景:作为腾讯云的老用户我大概是2018年开始使用腾讯云的tke服务的。当时是1.10,现在线上还有一个tke1.12的集群,鉴于早期更新迭代较慢。我选择了在腾讯云上面kubeadm的方式自建kubernetes集群的方式。参见:https://duiniwukenaihe.github.io/2019/09/02/k8s-install/。后面持续升级,现在是1.17.17版本。最近看腾讯云云原
背景:参见Kubernetes 1.20.5 安装gitlab,搭建了gitlab也都是自己玩的,也没有添加什么新的用户。线上跑的有个老的8.5.8的版本貌似?一直也没有升级,跑了好些年了。昨天有个新的项目组要创建一个项目。sogroup repository创建完成教了一下小伙伴的一般使用方式就跑路了。今天早上group中Developer用户的小伙伴用小乌龟的客户端clone项目后add添加后
背景:本地测试环境想跑点东西,就整个三节点的hadoop2.7.7吧。也跑过3.3.0的版本。本地正好跟着友凡老师的教程做些东西,他的课程都是2.6.0的版本。也不想先升级太快不匹配各种找问题了。就找了个2.7.7的包本地跑一跑了基础环境主机名ip系统hadoop1192.168.0.192centos8.2hadoop2192.168.0.192centos8.2hadoop3192.168.0
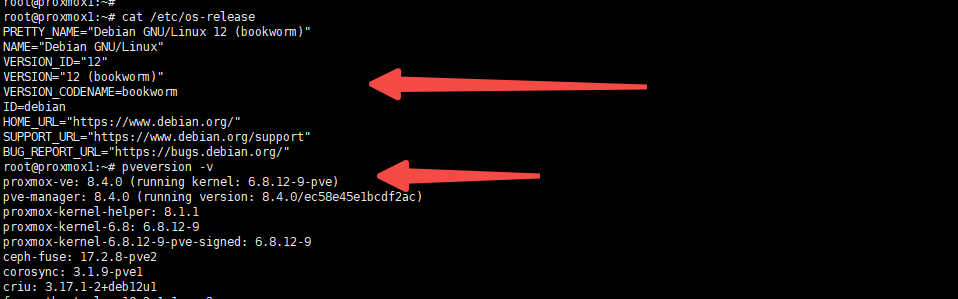
在R740服务器完成了proxmox的安装,并且安装了一张2080ti 魔改22g显存的的显卡。现在我需要将显卡直接直通到一台vm实例上面。验证系统信息****输出确认当前proxmox server 是基于debian 12 版本的 8.4.0 proxmox操作系统 :下面就就详细记录一下具体过程!请注意:当前服务器cpu为intel处理器,amd处理器配置有些许不同,请注意查找一下相关资料…
。。。今天启动comfyui突然出现了异常:但是浏览器访问15070端口无法访问:继续执行 systemctl status comfyui 发现:No CUDA GPUs are available。
背景:团队要发布一组应用,springboot开发的ws应用。然后需要对外。支持ws wss协议。jenkins写完pipeline发布任务。记得过去没有上容器的时候都是用的腾讯云的cls 挂证书映射cvm端口。我现在的网络环境是这样的:Kubernetes 1.20.5 安装traefik在腾讯云下的实践(当然了本次的环境是泡在tke1.20.6上面的,都是按照上面是咧搭建的—除了我新建了一个n