- @s1t16
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
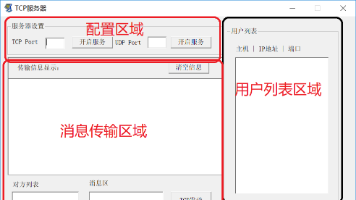
此项目为西北工业大学网络编程的课程设计选题。目标是在 VS 下,使用 Win32 网络编程和 MFC 框架实现多人在线聊天的服务器端和客户端。用户能够选择网络中的聊天对象,通过 UDP 广播或者通过 TCP 对指定用户进行通信,方便用户的交流。最终,在 windows 操作系统下实现多人在线即时聊天功能。服务器能够选择端口号并且启动服务器端的 TCP 服务,等待客户端的 Socket 连接。服务器
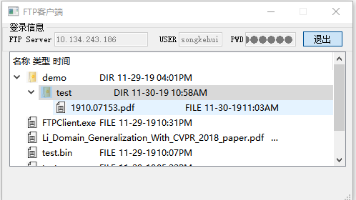
被动模式:FTP 服务器收到 PASV 命令后,随机打开一个高端端口(大于 1024)并且通知客户端在这个端口上传送数据的请求,客户端连接 FTP 服务器此端口,通过三次握手建立通道,然后 FTP 服务器将通过这个端口进行数据的传送。用户通过右击选中要删除的文件,点击“删除”按钮,程序将会发起请求将 FTP 服务器上的该文件删除。客户端进行上传文件操作时,先发出“PASV”命令建立起数据通信连接后
define MAX_LEN 12/* 字符串最大长度 */# define STU_NUM 30/* 最大的学生人数 */# define COURSE_NUM 6/* 最大的考试科目数 */# define LEN sizeof(struct Student)/* 学生结构体所占的字节大小*/int n, m;//输入的学生人数以及考试科目数int i;//输入菜单选项编号STU *head;
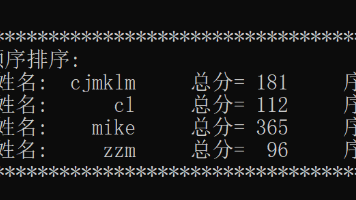
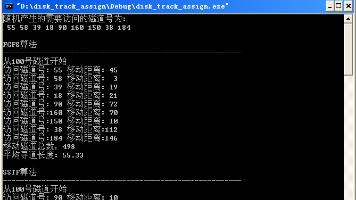
扫描算法(SCAN):优先考虑的是磁头当前的移动方向,即自里向外移动,访问既在当前磁道之外,同时又是距离最近的磁道;当磁头移到最外的磁道并访问后,磁头立即返回到最里的需访问的磁道,即。最短寻道时间优先算法(SSTF):要求访问的磁道与当前磁头所在的磁盘距离最近,以使每次的寻道时间最短。1. 本实验是模拟操作系统的磁盘寻道方式,运用磁盘访问顺序的不同来设计磁盘的调度算法。4. 选择磁盘调度算法,显示
当下人工智能行业发展迅猛,在各个领域都有涉及。人工智能的一大用处就是分类操作,在智能分类领域中,人工智能可以进行科学的模拟操作,以达到人们的相关需求。在本次大作业中,需要使用相关的分类器,对 200 类比的图片进行分类。首先我们选择了 ANN 模型即人工神经网络模型,这个模型使用神经网络技术模拟人体神经网络进行相关的训练,是对人脑组织结构和运行机制的某种抽象、简化和模拟。
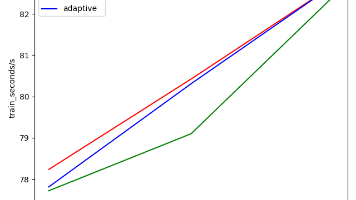
对于 225 的输入数量,上万的权值数,这点参数还不够塞牙缝的。在开始的网络训练的时候,我直接输入的是当前棋面,结果网络的收敛速度非常慢,在查阅资料发现,aplha-go 的实现方式是保存我方 8 步和敌方 8 步的落子信息,可能这种连续的落子信息能够让网络找到有效的信息。因为一开始我是直接将搜索 ai 作为训练对手,我的想法是,对于一个返回确定结果的对手,这样整个游戏就变成了一个确定的搜索树,只
PE 文件是 Windows 操作系统上的程序文件,可移植的可执行文件。一个操作系统的可执行文件在很多方面是这个操作系统的一面镜子。通过对 PE 文件结构,内部原理,作用的研究,让我们了解了 Windows 操作系统下,可执行文件是如何加载的,同时对操作系统的理解也更加深入了。同时也对软件安全,软件解密有了一定的了解。通过大作业的学习,也加深了对《操作系统原理》这门课程的理解。

1.Node.js2.Vue.js4.iView后端1.Node.js。
通过完成这次大作业,我提高了运用理论知识解决实际问题的能力,比如改进欧拉法、方程根的数值解等;同时也学到了很多新知识,比如 cordic 算法。这次大作业的难点在与误差分析,在对实际问题的结果进行误差分析的过程中,我加深了对方法误差和舍入误差的理解,认识到了实际问题中误差分析的必要性。将一个数值算法投入应用中,除了要考虑它的误差,另一个重要因素是算法的复杂度,cordic 算法的实现虽然需要提前准
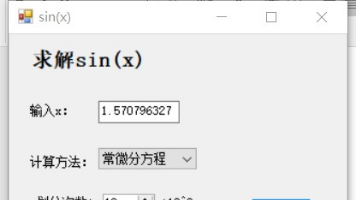
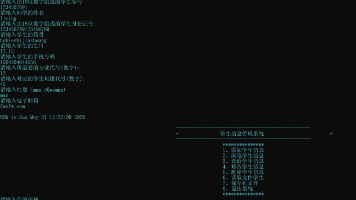
如果找到,输出其对应的数据,没有找到,则输出“很抱歉,没有你所需要的信息”本次课设模块主要分为,预编译,main 函数,输入/出函数,查找函数,修改函数,删除函数,保存文件函数,读取文件,以及系统时间加密函数,延时函数。main 函数作为本程序的核心程序,实现了本程序的菜单作用以及调用其他函数的以及改变控制台的属性的功能。⑴ 预编译主要是头文件的调取,宏定义,定义结构体,函数以及全局变量 coun