




- @qq_73553710
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
深度学习不是“看会的”,而是“练会的”。不要等“准备好了”再开始——今天就打开Colab,跑通第一个Notebook!“种一棵树最好的时间是十年前,其次是现在。” —— 非洲谚语。
官网:https://www.jetbrains.com/pycharm/适用场景:大型项目、Web开发(Django/Flask)、团队协作、专业级调试。版本选择Community(社区版):免费,支持纯Python开发。Professional(专业版):付费,支持Web框架、数据库、科学工具、远程开发等。优点智能代码补全、重构、错误检测极强集成调试器、测试工具、虚拟环境管理支持 Docker
从2014年简单的逐帧预测,到2025年Sora的世界模拟能力,视频生成技术经历了近十年的快速发展。这一历程不仅见证了深度学习技术的成熟,更预示着AI将在创意产业中发挥越来越重要的作用。正如OpenAI在Sora发布时所说:"我们正在向通用人工智能迈进,而视频生成只是这个宏伟蓝图中的一个重要步骤。"我们有理由相信,在不远的将来,每个人都能够轻松地创造出属于自己的精彩视频内容。这场从GAN到Sora
现有变化检测方法往往缺乏处理多样化现实查询的通用性,以及进行综合分析所需的智能化能力。本文提出了一种通用智能体框架——ChangeGPT,通过将大语言模型(LLM)与视觉基础模型(VFM)相结合,构建了一个层次化结构以抑制幻觉问题。该智能体在包含140个问题的精心标注数据集上进行了评估,这些问题按真实应用场景分类,涵盖多种问题类型(如:面积、类别、数量)及不同复杂度。评估维度包括:工具选择能力(精
本文介绍如何在腾讯云服务器上配置 OpenClaw 服务,通过 Nginx 反向代理实现公网访问。
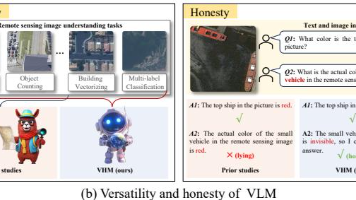
VHM代表了遥感视觉语言模型发展的一个重要里程碑。它通过数据驱动的方法,从根本上解决了传统方法的两个核心问题:理解深度不足和诚实性缺失。这项工作的价值不仅在于技术指标的提升,更在于方法论上的创新证明了高质量数据是提升模型能力的关键展示了模型诚实性可以通过数据设计来实现拓展了视觉语言模型在遥感领域的应用边界有时候,最好的算法改进不是修改模型架构,而是重新思考数据本身。武汉大学与上海人工智能实验室联合
📅 [2026年03月15日] AI 深度早报:GTC 开幕日,AI Agent 平台与具身世界模型双线引爆👋 晨间导读今天是 NVIDIA GTC 2026 的开幕日,也是本周 AI 圈最密集的一个爆发点。三件事同时发生:NVIDIA 用 NemoClaw 宣示进入 Agent 基础设施赛道;微软开源 AgentRx,把 AI Agent 的调试工程化带上台面;与此同时,来自中国的大晓机器人

👋 晨间导读今天是本年度 AI 圈最重磅的一天之一——NVIDIA GTC 2026 在圣何塞正式开幕,黄仁勋携 Feynman 1.6nm 新架构与 NemoClaw 开源 Agent 平台震撼登台,将 Physical AI 与具身智能推上新高度。与此同时,OpenAI 花 30 亿美元收购 Windsurf 的豪赌意外被微软截胡,暴露出 AI 编程赛道的内部角力;中国具身智能则在两个月内狂

👋 晨间导读今天是本年度 AI 圈最重磅的一天之一——NVIDIA GTC 2026 在圣何塞正式开幕,黄仁勋携 Feynman 1.6nm 新架构与 NemoClaw 开源 Agent 平台震撼登台,将 Physical AI 与具身智能推上新高度。与此同时,OpenAI 花 30 亿美元收购 Windsurf 的豪赌意外被微软截胡,暴露出 AI 编程赛道的内部角力;中国具身智能则在两个月内狂
📅 [2026年03月15日] AI 深度早报:GTC 开幕日,AI Agent 平台与具身世界模型双线引爆👋 晨间导读今天是 NVIDIA GTC 2026 的开幕日,也是本周 AI 圈最密集的一个爆发点。三件事同时发生:NVIDIA 用 NemoClaw 宣示进入 Agent 基础设施赛道;微软开源 AgentRx,把 AI Agent 的调试工程化带上台面;与此同时,来自中国的大晓机器人