




- @qq_71257020
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文分析了Flink多表JOIN导致状态爆炸的问题及解决方案。作者在处理10张MySQL CDC表关联的实时任务时,发现状态从几百MB暴涨至12GB。问题根源在于Regular JOIN会永久保存中间状态,TTL设置面临两难:太小会导致数据丢失,太大则内存爆炸。 Flink 2.1提出的MultiJoin方案通过"零中间状态"设计(用计算换存储)从根本上解决问题,但当前生产环境(Flink 1.1

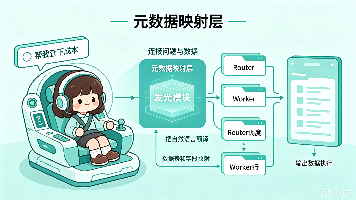
本文介绍了如何在Router+Worker架构中实现元数据映射功能。架构设计将映射层放在Skill Worker中,Router仅负责意图识别。具体实现分为三步:1) 表管理,通过配置表结构和字段描述划定LLM的知识边界;2) 术语词典,解决业务术语与数据库字段的映射问题;3) 表关联关系,提供跨表查询的JOIN规则。文中给出了Python代码示例,展示了如何在Worker中注入表结构上下文、处理
时长:约18-20分钟风格:搞钱干货+轻幽默+紧迫感核心目标:推广阿里云云小站 https://www.aliyun.com/minisite/goods?userCode=zg2tbduyBGM:紧张感电子乐,像倒计时主播A(老K):“问你个事——2026年,38块钱能买什么?”主播B(阿紫):“两杯奶茶?一张电影票?还是…”老K:“停。我今天用38块,买了一台全年无休的AI服务器,能跑Deep

本文总结了使用CDC工具从MySQL同步数据到Doris时遇到的乱序问题及解决方案。作者发现虽然CDC、Flink日志正常,但Doris数据异常,最终定位到是Doris Unique Key模型在乱序写入时后到数据覆盖先到数据的问题。通过为Doris表配置Sequence Column(如update_time字段),确保按业务时间顺序正确覆盖数据。文章还指出CDC涉及源库、网络、SQL引擎和存储

物流时效预测模型通过静态路由时效表计算运单计划时效,结合扫描轨迹提取的实际时效数据进行验证。模型基于运单路由信息和节点计划时间累加计算总时效,并通过偏差分析评估预测准确性。数据架构涵盖从扫描轨迹到时效宽表的多层处理,最终输出各线路预测准确率和偏差分析。该模型存在路由变化、异常事件和数据质量等局限,需通过实际路由重算、异常标记和数据兜底等方法优化。时效预测是数据驱动的计算与验证过程,为物流运营提供决

《物流大数据平台架构设计与实践》摘要: 物流行业数字化转型面临海量数据处理挑战,日均千万级订单和实时轨迹追踪需求催生了新一代大数据平台建设。该架构采用分层设计:数据采集层通过Kafka实现业务解耦;存储层融合HDFS、ClickHouse等组件满足不同场景;计算层基于Flink实现实时预警,Spark处理离线分析。技术选型注重高吞吐与低延迟,如Kafka3.4+Flink1.17组合。特别针对物流

在spark的bin下有是spark的指令,指令运行时可以指定对用的参数,实现对服务的控制。spark-submit--deploy-mode cluster代码文件名。当spark完成计算后,会产生对应的日志计算信息,在计算信息中显示了计算的流程。流程中涉及Application,job,stage,task的信息。dirver有资源调度分配在哪台机器上运行,就是cluster。dirver在提

x 数结构rdd中每个元素数据,元素是是什么类型,就进行什么类型的计算操作。可以选择指定master,appName。
时长:约18-20分钟风格:搞钱干货+轻幽默+紧迫感核心目标:推广阿里云云小站 https://www.aliyun.com/minisite/goods?userCode=zg2tbduyBGM:紧张感电子乐,像倒计时主播A(老K):“问你个事——2026年,38块钱能买什么?”主播B(阿紫):“两杯奶茶?一张电影票?还是…”老K:“停。我今天用38块,买了一台全年无休的AI服务器,能跑Deep
LSM 典型的 Minor Compaction 是指:增量数据只会让前面几层的文件进行合并,只要增量数据不够多,最底层的文件是不会参与 Compaction 的,这就意味着多个 Tag 之间的最底层是完全一样,完全复用的,结合湖格式的文件管理,多个 Tag 并不会带来冗余的文件存储。Tag 是 immuatable 的,它不能被增删改查的,一般来说,数据库映射的表是不可变的,我们推荐在 ODS